 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixed-Point Reasoners: Stable and Adaptive Deep Looped Transformers
Jun 16, 2026Looped architectures provide an inductive bias toward learning step-by-step procedures for tasks that require compositional reasoning. The number of effective layers reached by looping determines the quality of the solution these models find. Like deep architectures, looped architectures are prone to a signal propagation problem induced by depth as the halting decision is postponed. In this paper, we address this signal propagation issue using pre-norm layers and residual scaling. Building on these architectural modifications, we propose FPRM, a Transformer-based Fixed-Point Reasoning Model that uses fixed-point convergence as an end-to-end halting mechanism in a looped architecture. We show that fixed-point halting allows FPRM to adapt its compute to task difficulty. FPRM is effective on common reasoning benchmarks, namely Sudoku, Maze, state-tracking, and ARC-AGI.
SeqLoRA: Bilevel Orthogonal Adaptation for Continual Multi-Concept Generation
May 21, 2026Parameter-efficient fine-tuning enables fast personalization of text-to-image diffusion models, but composing multiple custom concepts remains challenging due to representation interference. Existing modular methods either rely on expensive post-hoc fusion or freeze adaptation subspaces, which limit expressiveness and concept fidelity. To address this trade-off, we propose Sequential regularized LoRA (SeqLoRA), a constrained continual learning framework that jointly optimizes both LoRA factors via bilevel optimization. Theoretically, we establish strong convergence guarantees for our algorithm and model the residual layer activations as a matrix sub-Gaussian process to derive high-probability bounds on catastrophic forgetting. We further prove that learning the LoRA basis from data minimizes residual interference energy more effectively than frozen-basis methods. Experiments on multi-concept image generation demonstrate that SeqLoRA improves identity preservation and scalability across up to 101 concepts, while avoiding costly fusion and reducing attribute interference in composed generations.
FullFlow: Upgrading Text-to-Image Flow Matching Models for Bidirectional Vision--Language Generation
May 19, 2026Modern text-to-image diffusion models encode rich visual priors, but expose them only through one-way text-conditioned generation. Existing unified vision--language models derived from them recover bidirectional capability through large-scale joint pretraining or substantial retraining of the text pathway, discarding the strong image prior the text-to-image backbone already encodes. We introduce \emph{FullFlow}, a parameter-efficient recipe that upgrades a pretrained rectified-flow text-to-image model into a bidirectional vision--language generator by training only LoRA adapters and lightweight text heads. FullFlow keeps images in their native continuous flow and adds a discrete insertion process for text. Separate image and text timesteps turn inference into trajectory selection in a two-dimensional generative space, enabling text$\rightarrow$image, image$\rightarrow$text, joint sampling, and partial-text prediction with a single backbone. On Stable Diffusion 3 (SD3) under an identical trainable-parameter count and matched LoRA rank, FullFlow improves text$\rightarrow$image FID from $62.7$ to $31.6$ and image$\rightarrow$text CIDEr from $2.0$ to $99.4$ over a LoRA equivalent following the previous SOTA formulation (Dual Diffusion) at matched wall-clock training time, while reducing peak VRAM from ${\sim}84$\,GB to ${\sim}38$\,GB and raising throughput by ${\sim}8\times$ on two RTX A5000 GPUs in under 24 hours, training only ${\sim}5\%$ of the backbone parameters. The same recipe transfers to FLUX.1-dev and supports downstream VQA through partial-text generation. These results show that strong bidirectional vision--language capability can be unlocked from pretrained text-to-image flow models without full multimodal pretraining.
Flash PD-SSM: Memory-Optimized Structured Sparse State-Space Models
May 18, 2026State-space models (SSMs) face a fundamental trade-off between efficiency and expressivity that is mainly dictated by the structure of the model's transition matrix. Unstructured transition matrices enable maximal expressivity, as measured by their ability to model finite-state automaton (FSA) transitions, but come at a prohibitively high compute and memory cost. In contrast, most structured transition matrix forms are highly efficient both in runtime and memory consumption, but suffer from limited expressivity. Building on recent work on structured sparse SSMs, we propose Flash PD-SSM, a novel SSM that achieves comparable throughput to widely-used structured SSMs with significantly better expressivity guarantees. Flash PD-SSM maintains a trainable set of structured sparse matrices, a single one of which is discretely selected at each time-step, enabling FSA expressiveness at the level of unstructured matrices while maintaining the efficiency required for training models at scale. First, we validate Flash PD-SSM against a suite of alternative models on synthetic mechanistic and state-tracking tasks, finding that its theoretical expressivity is achieved in practice. Second, on multivariate time-series tasks involving sequences of length over 17,000, we find that Flash PD-SSM defines a new state-of-the-art (SoTA) accuracy among competing SSM methods. Finally, we demonstrate that Flash PD-SSM is an effective drop-in replacement for hybrid LLMs, yielding improvements both in natural language state-tracking and in common language modeling scenarios. The model exhibits increased throughput and decreased memory consumption compared to SSMs widely used in frontier language models.
When Does Sparsity Mitigate the Curse of Depth in LLMs
Mar 16, 2026Recent work has demonstrated the curse of depth in large language models (LLMs), where later layers contribute less to learning and representation than earlier layers. Such under-utilization is linked to the accumulated growth of variance in Pre-Layer Normalization, which can push deep blocks toward near-identity behavior. In this paper, we demonstrate that, sparsity, beyond enabling efficiency, acts as a regulator of variance propagation and thereby improves depth utilization. Our investigation covers two sources of sparsity: (i) implicit sparsity, which emerges from training and data conditions, including weight sparsity induced by weight decay and attention sparsity induced by long context inputs; and (ii) explicit sparsity, which is enforced by architectural design, including key/value-sharing sparsity in Grouped-Query Attention and expert-activation sparsity in Mixtureof-Experts. Our claim is thoroughly supported by controlled depth-scaling experiments and targeted layer effectiveness interventions. Across settings, we observe a consistent relationship: sparsity improves layer utilization by reducing output variance and promoting functional differentiation. We eventually distill our findings into a practical rule-of-thumb recipe for training deptheffective LLMs, yielding a notable 4.6% accuracy improvement on downstream tasks. Our results reveal sparsity, arising naturally from standard design choices, as a key yet previously overlooked mechanism for effective depth scaling in LLMs. Code is available at https://github.com/pUmpKin-Co/SparsityAndCoD.
Latent-DARM: Bridging Discrete Diffusion And Autoregressive Models For Reasoning
Mar 10, 2026Most multi-agent systems rely exclusively on autoregressive language models (ARMs) that are based on sequential generation. Although effective for fluent text, ARMs limit global reasoning and plan revision. On the other hand, Discrete Diffusion Language Models (DDLMs) enable non-sequential, globally revisable generation and have shown strong planning capabilities, but their limited text fluency hinders direct collaboration with ARMs. We introduce Latent-DARM, a latent-space communication framework bridging DDLM (planners) and ARM (executors), maximizing collaborative benefits. Across mathematical, scientific, and commonsense reasoning benchmarks, Latent-DARM outperforms text-based interfaces on average, improving accuracy from 27.0% to 36.0% on DART-5 and from 0.0% to 14.0% on AIME2024. Latent-DARM approaches the results of state-of-the-art reasoning models while using less than 2.2% of its token budget. This work advances multi-agent collaboration among agents with heterogeneous models.
Fast and Geometrically Grounded Lorentz Neural Networks
Jan 29, 2026Hyperbolic space is quickly gaining traction as a promising geometry for hierarchical and robust representation learning. A core open challenge is the development of a mathematical formulation of hyperbolic neural networks that is both efficient and captures the key properties of hyperbolic space. The Lorentz model of hyperbolic space has been shown to enable both fast forward and backward propagation. However, we prove that, with the current formulation of Lorentz linear layers, the hyperbolic norms of the outputs scale logarithmically with the number of gradient descent steps, nullifying the key advantage of hyperbolic geometry. We propose a new Lorentz linear layer grounded in the well-known ``distance-to-hyperplane" formulation. We prove that our formulation results in the usual linear scaling of output hyperbolic norms with respect to the number of gradient descent steps. Our new formulation, together with further algorithmic efficiencies through Lorentzian activation functions and a new caching strategy results in neural networks fully abiding by hyperbolic geometry while simultaneously bridging the computation gap to Euclidean neural networks. Code available at: https://github.com/robertdvdk/hyperbolic-fully-connected.
Scaling Behavior of Discrete Diffusion Language Models
Dec 11, 2025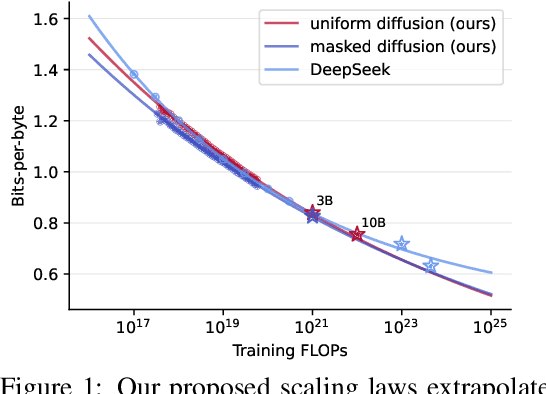
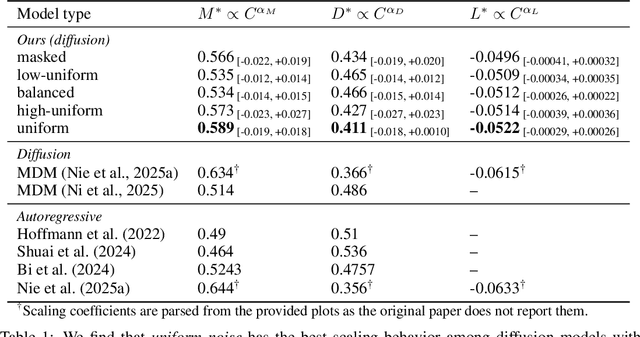
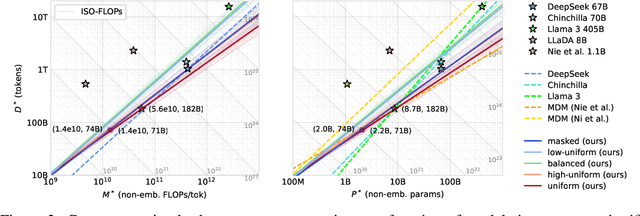
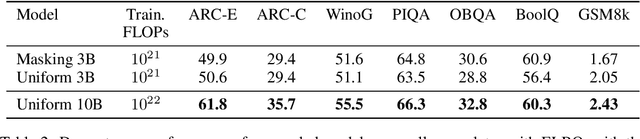
Modern LLM pre-training consumes vast amounts of compute and training data, making the scaling behavior, or scaling laws, of different models a key distinguishing factor. Discrete diffusion language models (DLMs) have been proposed as an alternative to autoregressive language models (ALMs). However, their scaling behavior has not yet been fully explored, with prior work suggesting that they require more data and compute to match the performance of ALMs. We study the scaling behavior of DLMs on different noise types by smoothly interpolating between masked and uniform diffusion while paying close attention to crucial hyperparameters such as batch size and learning rate. Our experiments reveal that the scaling behavior of DLMs strongly depends on the noise type and is considerably different from ALMs. While all noise types converge to similar loss values in compute-bound scaling, we find that uniform diffusion requires more parameters and less data for compute-efficient training compared to masked diffusion, making them a promising candidate in data-bound settings. We scale our uniform diffusion model up to 10B parameters trained for $10^{22}$ FLOPs, confirming the predicted scaling behavior and making it the largest publicly known uniform diffusion model to date.
Asymptotic analysis of shallow and deep forgetting in replay with Neural Collapse
Dec 08, 2025A persistent paradox in continual learning (CL) is that neural networks often retain linearly separable representations of past tasks even when their output predictions fail. We formalize this distinction as the gap between deep feature-space and shallow classifier-level forgetting. We reveal a critical asymmetry in Experience Replay: while minimal buffers successfully anchor feature geometry and prevent deep forgetting, mitigating shallow forgetting typically requires substantially larger buffer capacities. To explain this, we extend the Neural Collapse framework to the sequential setting. We characterize deep forgetting as a geometric drift toward out-of-distribution subspaces and prove that any non-zero replay fraction asymptotically guarantees the retention of linear separability. Conversely, we identify that the "strong collapse" induced by small buffers leads to rank-deficient covariances and inflated class means, effectively blinding the classifier to true population boundaries. By unifying CL with out-of-distribution detection, our work challenges the prevailing reliance on large buffers, suggesting that explicitly correcting these statistical artifacts could unlock robust performance with minimal replay.
Optimal Control Meets Flow Matching: A Principled Route to Multi-Subject Fidelity
Oct 02, 2025Text-to-image (T2I) models excel on single-entity prompts but struggle with multi-subject descriptions, often showing attribute leakage, identity entanglement, and subject omissions. We introduce the first theoretical framework with a principled, optimizable objective for steering sampling dynamics toward multi-subject fidelity. Viewing flow matching (FM) through stochastic optimal control (SOC), we formulate subject disentanglement as control over a trained FM sampler. This yields two architecture-agnostic algorithms: (i) a training-free test-time controller that perturbs the base velocity with a single-pass update, and (ii) Adjoint Matching, a lightweight fine-tuning rule that regresses a control network to a backward adjoint signal while preserving base-model capabilities. The same formulation unifies prior attention heuristics, extends to diffusion models via a flow-diffusion correspondence, and provides the first fine-tuning route explicitly designed for multi-subject fidelity. Empirically, on Stable Diffusion 3.5, FLUX, and Stable Diffusion XL, both algorithms consistently improve multi-subject alignment while maintaining base-model style. Test-time control runs efficiently on commodity GPUs, and fine-tuned controllers trained on limited prompts generalize to unseen ones. We further highlight FOCUS (Flow Optimal Control for Unentangled Subjects), which achieves state-of-the-art multi-subject fidelity across models.