 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalog Foundation Models
May 14, 2025Analog in-memory computing (AIMC) is a promising compute paradigm to improve speed and power efficiency of neural network inference beyond the limits of conventional von Neumann-based architectures. However, AIMC introduces fundamental challenges such as noisy computations and strict constraints on input and output quantization. Because of these constraints and imprecisions, off-the-shelf LLMs are not able to achieve 4-bit-level performance when deployed on AIMC-based hardware. While researchers previously investigated recovering this accuracy gap on small, mostly vision-based models, a generic method applicable to LLMs pre-trained on trillions of tokens does not yet exist. In this work, we introduce a general and scalable method to robustly adapt LLMs for execution on noisy, low-precision analog hardware. Our approach enables state-of-the-art models $\unicode{x2013}$ including Phi-3-mini-4k-instruct and Llama-3.2-1B-Instruct $\unicode{x2013}$ to retain performance comparable to 4-bit weight, 8-bit activation baselines, despite the presence of analog noise and quantization constraints. Additionally, we show that as a byproduct of our training methodology, analog foundation models can be quantized for inference on low-precision digital hardware. Finally, we show that our models also benefit from test-time compute scaling, showing better scaling behavior than models trained with 4-bit weight and 8-bit static input quantization. Our work bridges the gap between high-capacity LLMs and efficient analog hardware, offering a path toward energy-efficient foundation models. Code is available at https://github.com/IBM/analog-foundation-models .
Can Large Reasoning Models do Analogical Reasoning under Perceptual Uncertainty?
Mar 14, 2025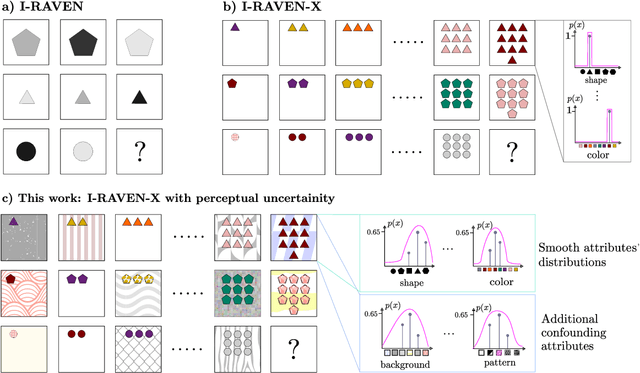
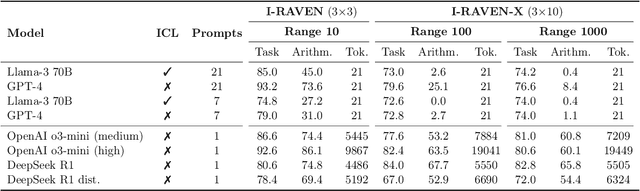
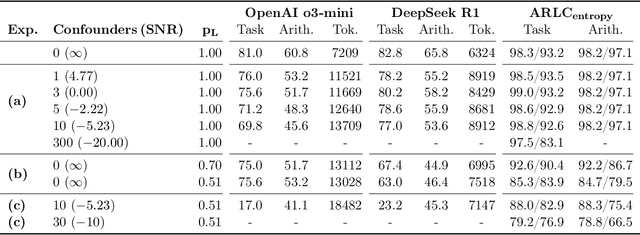
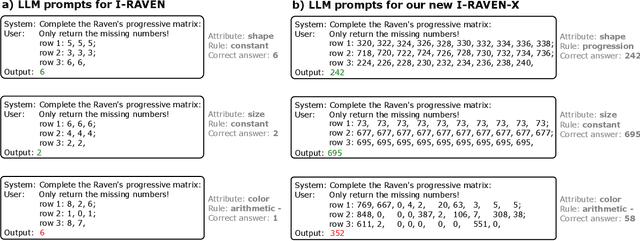
This work presents a first evaluation of two state-of-the-art Large Reasoning Models (LRMs), OpenAI's o3-mini and DeepSeek R1, on analogical reasoning, focusing on well-established nonverbal human IQ tests based on Raven's progressive matrices. We benchmark with the I-RAVEN dataset and its more difficult extension, I-RAVEN-X, which tests the ability to generalize to longer reasoning rules and ranges of the attribute values. To assess the influence of visual uncertainties on these nonverbal analogical reasoning tests, we extend the I-RAVEN-X dataset, which otherwise assumes an oracle perception. We adopt a two-fold strategy to simulate this imperfect visual perception: 1) we introduce confounding attributes which, being sampled at random, do not contribute to the prediction of the correct answer of the puzzles and 2) smoothen the distributions of the input attributes' values. We observe a sharp decline in OpenAI's o3-mini task accuracy, dropping from 86.6% on the original I-RAVEN to just 17.0% -- approaching random chance -- on the more challenging I-RAVEN-X, which increases input length and range and emulates perceptual uncertainty. This drop occurred despite spending 3.4x more reasoning tokens. A similar trend is also observed for DeepSeek R1: from 80.6% to 23.2%. On the other hand, a neuro-symbolic probabilistic abductive model, ARLC, that achieves state-of-the-art performances on I-RAVEN, can robustly reason under all these out-of-distribution tests, maintaining strong accuracy with only a modest reduction from 98.6% to 88.0%. Our code is available at https://github.com/IBM/raven-large-language-models.
On the Expressiveness and Length Generalization of Selective State-Space Models on Regular Languages
Dec 26, 2024



Selective state-space models (SSMs) are an emerging alternative to the Transformer, offering the unique advantage of parallel training and sequential inference. Although these models have shown promising performance on a variety of tasks, their formal expressiveness and length generalization properties remain underexplored. In this work, we provide insight into the workings of selective SSMs by analyzing their expressiveness and length generalization performance on regular language tasks, i.e., finite-state automaton (FSA) emulation. We address certain limitations of modern SSM-based architectures by introducing the Selective Dense State-Space Model (SD-SSM), the first selective SSM that exhibits perfect length generalization on a set of various regular language tasks using a single layer. It utilizes a dictionary of dense transition matrices, a softmax selection mechanism that creates a convex combination of dictionary matrices at each time step, and a readout consisting of layer normalization followed by a linear map. We then proceed to evaluate variants of diagonal selective SSMs by considering their empirical performance on commutative and non-commutative automata. We explain the experimental results with theoretical considerations. Our code is available at https://github.com/IBM/selective-dense-state-space-model.
Towards Learning to Reason: Comparing LLMs with Neuro-Symbolic on Arithmetic Relations in Abstract Reasoning
Dec 07, 2024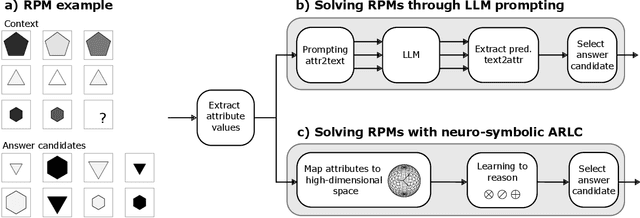
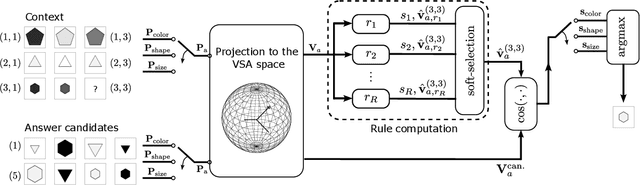
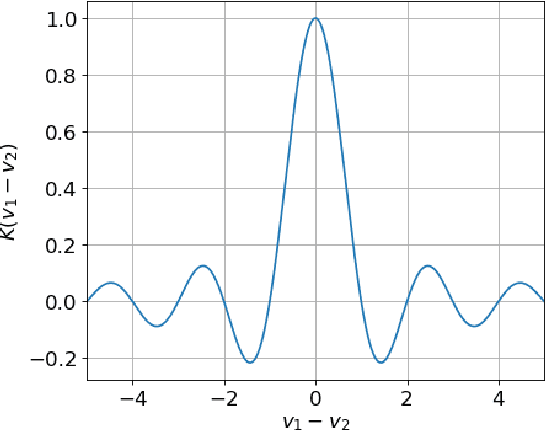
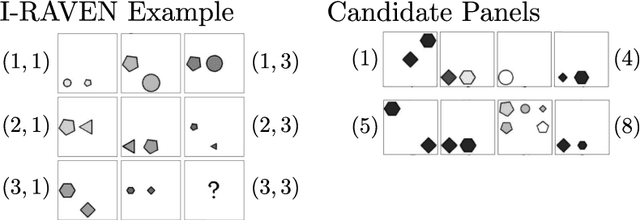
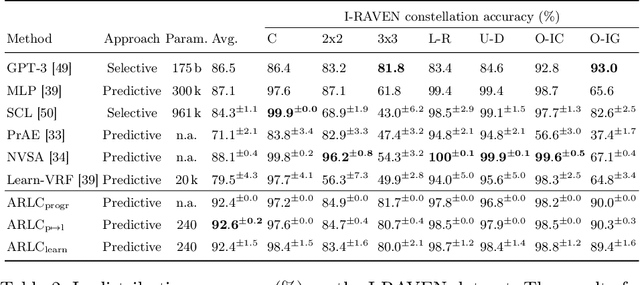
This work compares large language models (LLMs) and neuro-symbolic approaches in solving Raven's progressive matrices (RPM), a visual abstract reasoning test that involves the understanding of mathematical rules such as progression or arithmetic addition. Providing the visual attributes directly as textual prompts, which assumes an oracle visual perception module, allows us to measure the model's abstract reasoning capability in isolation. Despite providing such compositionally structured representations from the oracle visual perception and advanced prompting techniques, both GPT-4 and Llama-3 70B cannot achieve perfect accuracy on the center constellation of the I-RAVEN dataset. Our analysis reveals that the root cause lies in the LLM's weakness in understanding and executing arithmetic rules. As a potential remedy, we analyze the Abductive Rule Learner with Context-awareness (ARLC), a neuro-symbolic approach that learns to reason with vector-symbolic architectures (VSAs). Here, concepts are represented with distributed vectors s.t. dot products between encoded vectors define a similarity kernel, and simple element-wise operations on the vectors perform addition/subtraction on the encoded values. We find that ARLC achieves almost perfect accuracy on the center constellation of I-RAVEN, demonstrating a high fidelity in arithmetic rules. To stress the length generalization capabilities of the models, we extend the RPM tests to larger matrices (3x10 instead of typical 3x3) and larger dynamic ranges of the attribute values (from 10 up to 1000). We find that the LLM's accuracy of solving arithmetic rules drops to sub-10%, especially as the dynamic range expands, while ARLC can maintain a high accuracy due to emulating symbolic computations on top of properly distributed representations. Our code is available at https://github.com/IBM/raven-large-language-models.
On the Role of Noise in Factorizers for Disentangling Distributed Representations
Nov 30, 2024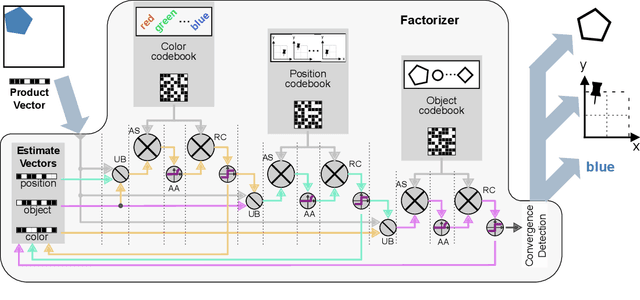
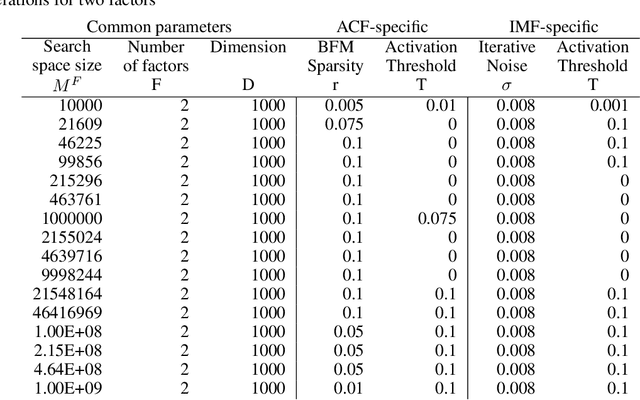
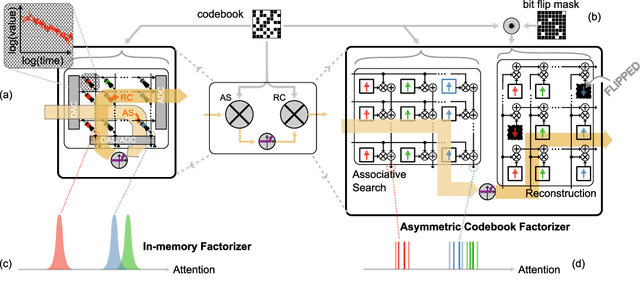
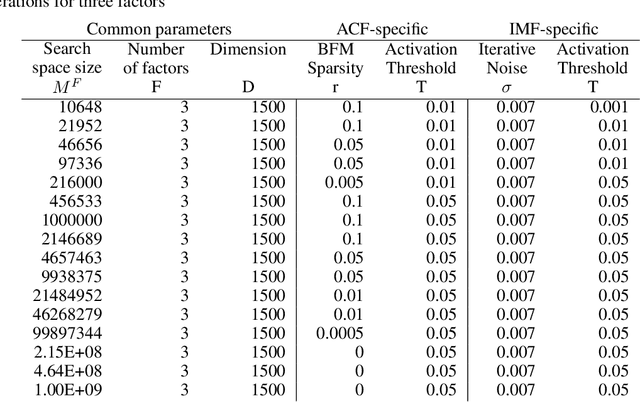
To efficiently factorize high-dimensional distributed representations to the constituent atomic vectors, one can exploit the compute-in-superposition capabilities of vector-symbolic architectures (VSA). Such factorizers however suffer from the phenomenon of limit cycles. Applying noise during the iterative decoding is one mechanism to address this issue. In this paper, we explore ways to further relax the noise requirement by applying noise only at the time of VSA's reconstruction codebook initialization. While the need for noise during iterations proves analog in-memory computing systems to be a natural choice as an implementation media, the adequacy of initialization noise allows digital hardware to remain equally indispensable. This broadens the implementation possibilities of factorizers. Our study finds that while the best performance shifts from initialization noise to iterative noise as the number of factors increases from 2 to 4, both extend the operational capacity by at least 50 times compared to the baseline factorizer resonator networks. Our code is available at: https://github.com/IBM/in-memory-factorizer
Kernel Approximation using Analog In-Memory Computing
Nov 05, 2024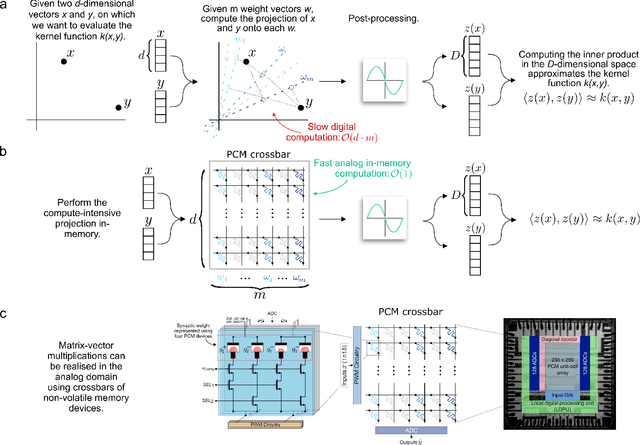
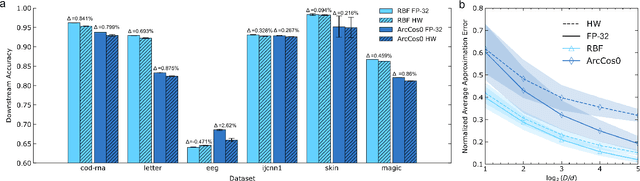
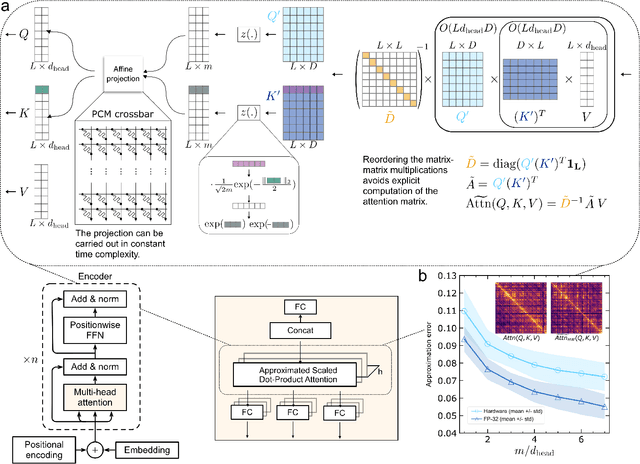
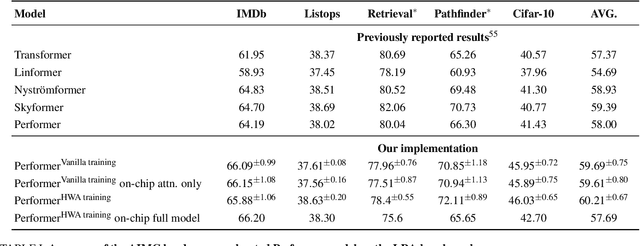
Kernel functions are vital ingredients of several machine learning algorithms, but often incur significant memory and computational costs. We introduce an approach to kernel approximation in machine learning algorithms suitable for mixed-signal Analog In-Memory Computing (AIMC) architectures. Analog In-Memory Kernel Approximation addresses the performance bottlenecks of conventional kernel-based methods by executing most operations in approximate kernel methods directly in memory. The IBM HERMES Project Chip, a state-of-the-art phase-change memory based AIMC chip, is utilized for the hardware demonstration of kernel approximation. Experimental results show that our method maintains high accuracy, with less than a 1% drop in kernel-based ridge classification benchmarks and within 1% accuracy on the Long Range Arena benchmark for kernelized attention in Transformer neural networks. Compared to traditional digital accelerators, our approach is estimated to deliver superior energy efficiency and lower power consumption. These findings highlight the potential of heterogeneous AIMC architectures to enhance the efficiency and scalability of machine learning applications.
In-Materia Speech Recognition
Oct 14, 2024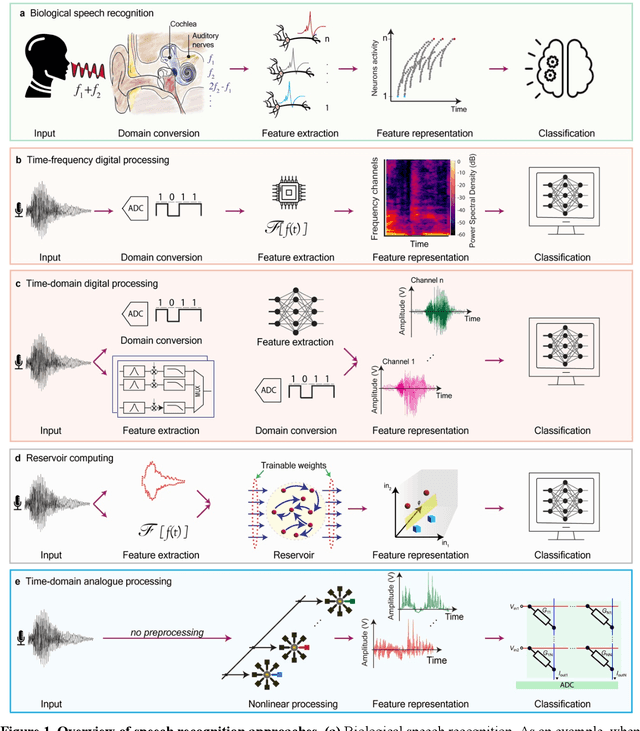
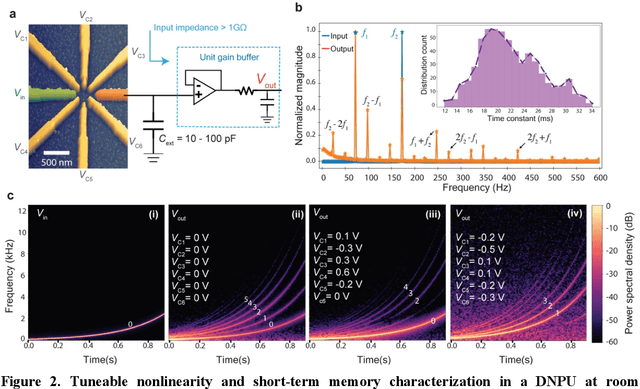
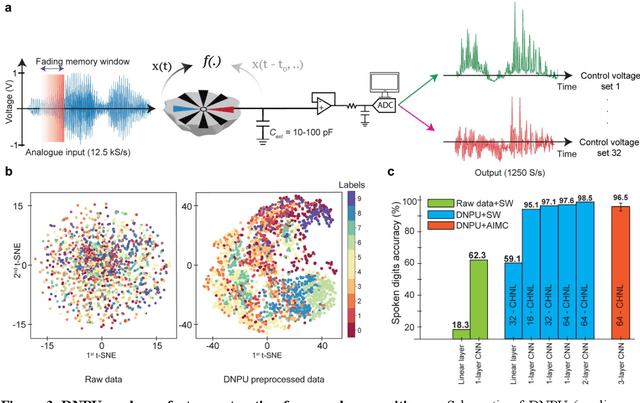
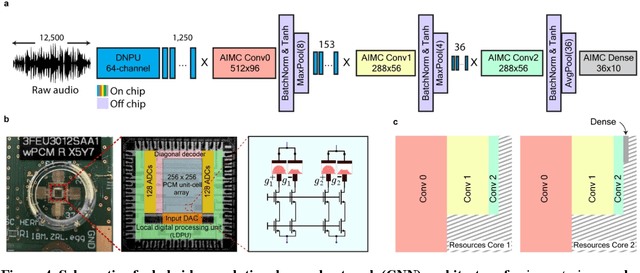
With the rise of decentralized computing, as in the Internet of Things, autonomous driving, and personalized healthcare, it is increasingly important to process time-dependent signals at the edge efficiently: right at the place where the temporal data are collected, avoiding time-consuming, insecure, and costly communication with a centralized computing facility (or cloud). However, modern-day processors often cannot meet the restrained power and time budgets of edge systems because of intrinsic limitations imposed by their architecture (von Neumann bottleneck) or domain conversions (analogue-to-digital and time-to-frequency). Here, we propose an edge temporal-signal processor based on two in-materia computing systems for both feature extraction and classification, reaching a software-level accuracy of 96.2% for the TI-46-Word speech-recognition task. First, a nonlinear, room-temperature dopant-network-processing-unit (DNPU) layer realizes analogue, time-domain feature extraction from the raw audio signals, similar to the human cochlea. Second, an analogue in-memory computing (AIMC) chip, consisting of memristive crossbar arrays, implements a compact neural network trained on the extracted features for classification. With the DNPU feature extraction consuming 100s nW and AIMC-based classification having the potential for less than 10 fJ per multiply-accumulate operation, our findings offer a promising avenue for advancing the compactness, efficiency, and performance of heterogeneous smart edge processors through in-materia computing hardware.
Roadmap to Neuromorphic Computing with Emerging Technologies
Jul 02, 2024



The roadmap is organized into several thematic sections, outlining current computing challenges, discussing the neuromorphic computing approach, analyzing mature and currently utilized technologies, providing an overview of emerging technologies, addressing material challenges, exploring novel computing concepts, and finally examining the maturity level of emerging technologies while determining the next essential steps for their advancement.
Towards Learning Abductive Reasoning using VSA Distributed Representations
Jun 27, 2024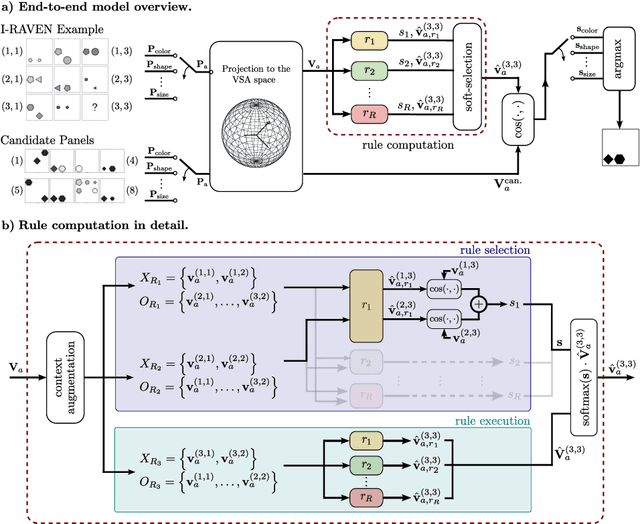

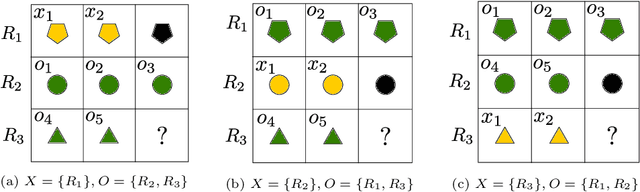
We introduce the Abductive Rule Learner with Context-awareness (ARLC), a model that solves abstract reasoning tasks based on Learn-VRF. ARLC features a novel and more broadly applicable training objective for abductive reasoning, resulting in better interpretability and higher accuracy when solving Raven's progressive matrices (RPM). ARLC allows both programming domain knowledge and learning the rules underlying a data distribution. We evaluate ARLC on the I-RAVEN dataset, showcasing state-of-the-art accuracy across both in-distribution and out-of-distribution (unseen attribute-rule pairs) tests. ARLC surpasses neuro-symbolic and connectionist baselines, including large language models, despite having orders of magnitude fewer parameters. We show ARLC's robustness to post-programming training by incrementally learning from examples on top of programmed knowledge, which only improves its performance and does not result in catastrophic forgetting of the programmed solution. We validate ARLC's seamless transfer learning from a 2x2 RPM constellation to unseen constellations. Our code is available at https://github.com/IBM/abductive-rule-learner-with-context-awareness.
Training of Physical Neural Networks
Jun 05, 2024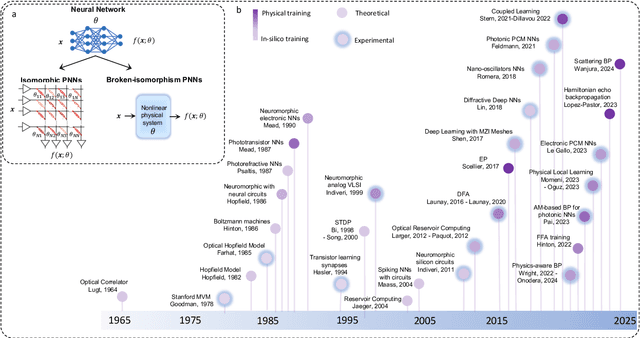
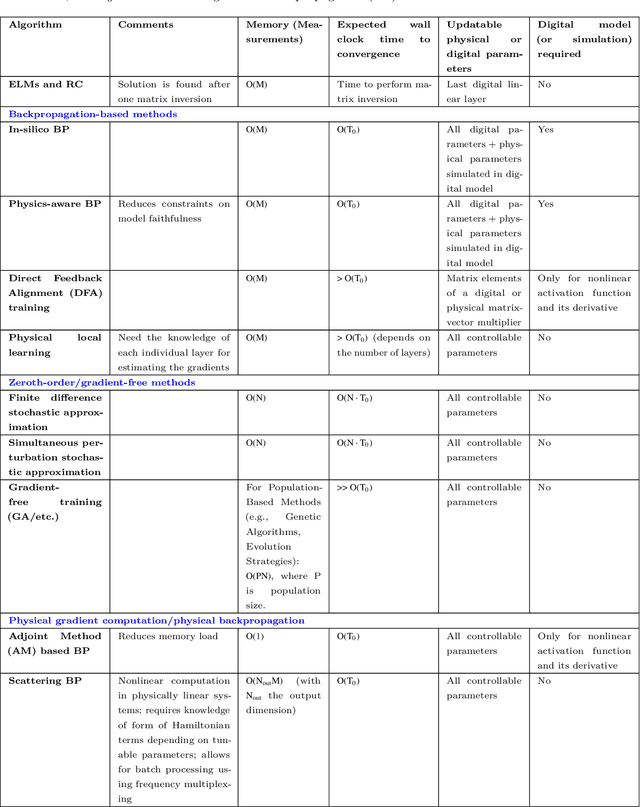
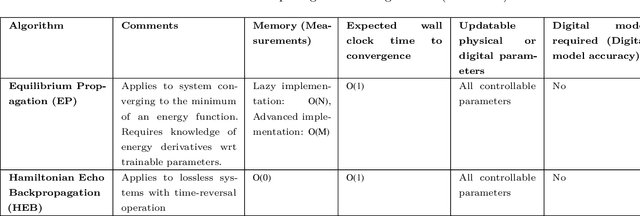
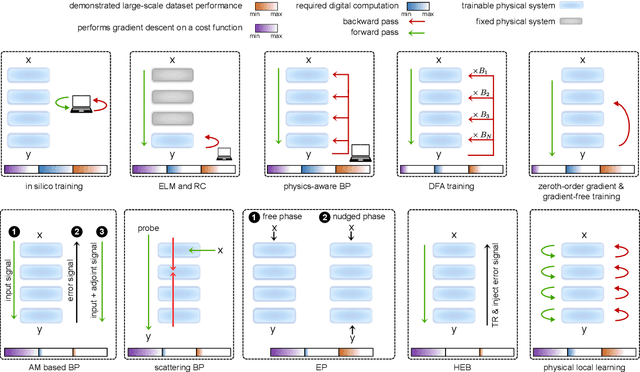
Physical neural networks (PNNs) are a class of neural-like networks that leverage the properties of physical systems to perform computation. While PNNs are so far a niche research area with small-scale laboratory demonstrations, they are arguably one of the most underappreciated important opportunities in modern AI. Could we train AI models 1000x larger than current ones? Could we do this and also have them perform inference locally and privately on edge devices, such as smartphones or sensors? Research over the past few years has shown that the answer to all these questions is likely "yes, with enough research": PNNs could one day radically change what is possible and practical for AI systems. To do this will however require rethinking both how AI models work, and how they are trained - primarily by considering the problems through the constraints of the underlying hardware physics. To train PNNs at large scale, many methods including backpropagation-based and backpropagation-free approaches are now being explored. These methods have various trade-offs, and so far no method has been shown to scale to the same scale and performance as the backpropagation algorithm widely used in deep learning today. However, this is rapidly changing, and a diverse ecosystem of training techniques provides clues for how PNNs may one day be utilized to create both more efficient realizations of current-scale AI models, and to enable unprecedented-scale models.