 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimits of nonlinear and dispersive fiber propagation for photonic extreme learning
Mar 05, 2025We report a generalized nonlinear Schr\"odinger equation simulation model of an extreme learning machine based on optical fiber propagation. Using handwritten digit classification as a benchmark, we study how accuracy depends on propagation dynamics, as well as parameters governing spectral encoding, readout, and noise. Test accuracies of over 91% and 93% are found for propagation in the anomalous and normal dispersion regimes respectively. Our simulation results also suggest that quantum noise on the input pulses introduces an intrinsic penalty to ELM performance.
A spiking photonic neural network of 40.000 neurons, trained with rank-order coding for leveraging sparsity
Nov 28, 2024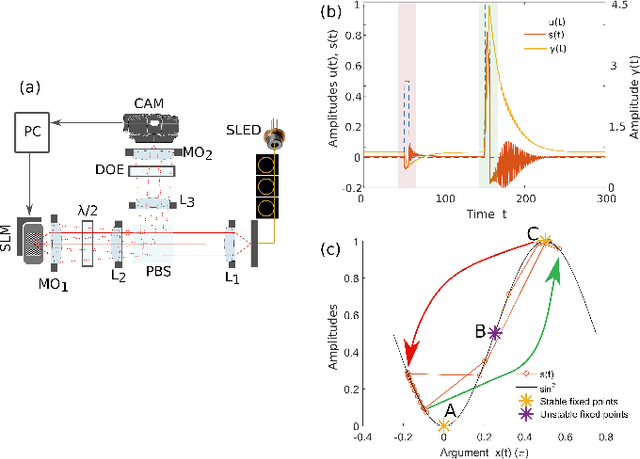
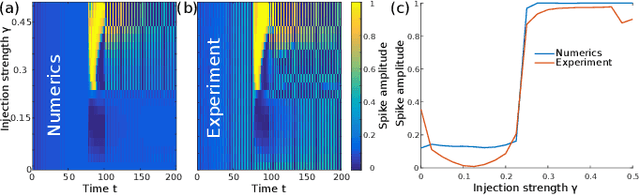
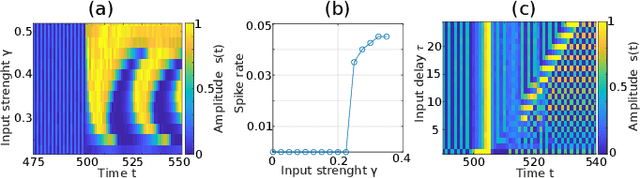
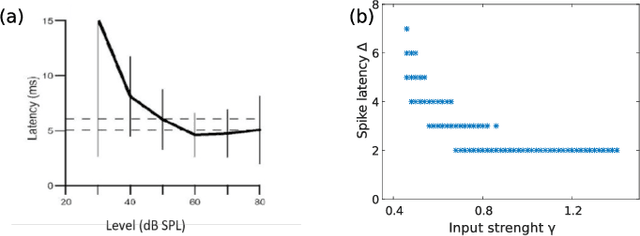
In recent years, the hardware implementation of neural networks, leveraging physical coupling and analog neurons has substantially increased in relevance. Such nonlinear and complex physical networks provide significant advantages in speed and energy efficiency, but are potentially susceptible to internal noise when compared to digital emulations of such networks. In this work, we consider how additive and multiplicative Gaussian white noise on the neuronal level can affect the accuracy of the network when applied for specific tasks and including a softmax function in the readout layer. We adapt several noise reduction techniques to the essential setting of classification tasks, which represent a large fraction of neural network computing. We find that these adjusted concepts are highly effective in mitigating the detrimental impact of noise.
Training of Physical Neural Networks
Jun 05, 2024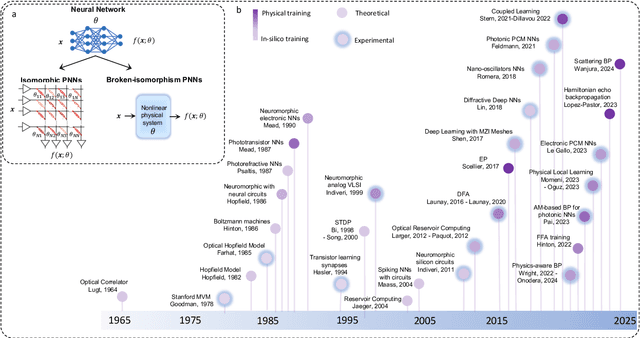
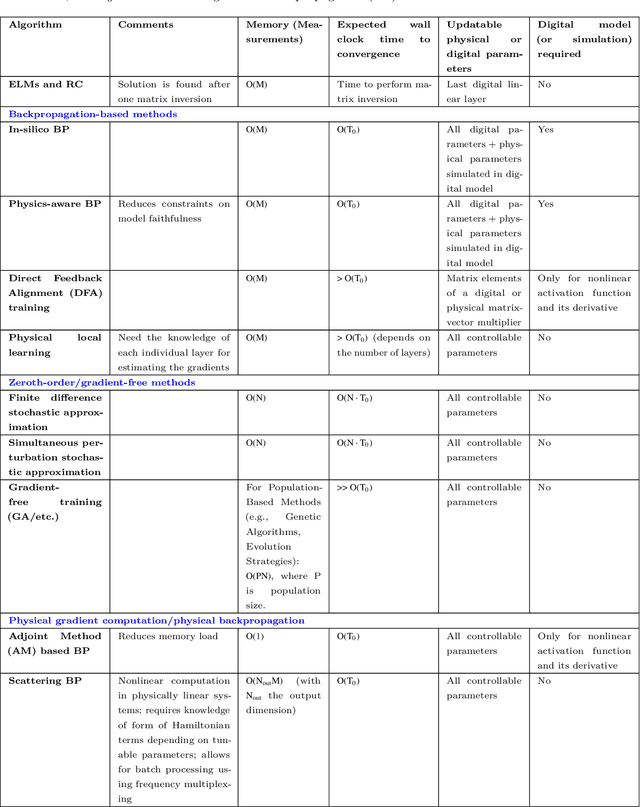
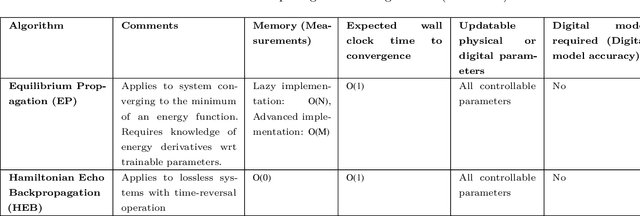
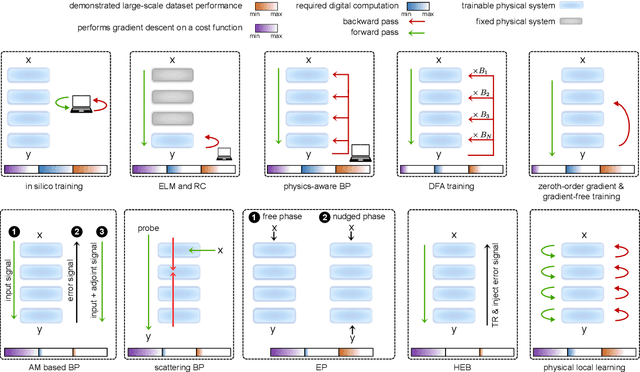
Physical neural networks (PNNs) are a class of neural-like networks that leverage the properties of physical systems to perform computation. While PNNs are so far a niche research area with small-scale laboratory demonstrations, they are arguably one of the most underappreciated important opportunities in modern AI. Could we train AI models 1000x larger than current ones? Could we do this and also have them perform inference locally and privately on edge devices, such as smartphones or sensors? Research over the past few years has shown that the answer to all these questions is likely "yes, with enough research": PNNs could one day radically change what is possible and practical for AI systems. To do this will however require rethinking both how AI models work, and how they are trained - primarily by considering the problems through the constraints of the underlying hardware physics. To train PNNs at large scale, many methods including backpropagation-based and backpropagation-free approaches are now being explored. These methods have various trade-offs, and so far no method has been shown to scale to the same scale and performance as the backpropagation algorithm widely used in deep learning today. However, this is rapidly changing, and a diverse ecosystem of training techniques provides clues for how PNNs may one day be utilized to create both more efficient realizations of current-scale AI models, and to enable unprecedented-scale models.
A complete, parallel and autonomous photonic neural network in a semiconductor multimode laser
Dec 21, 2020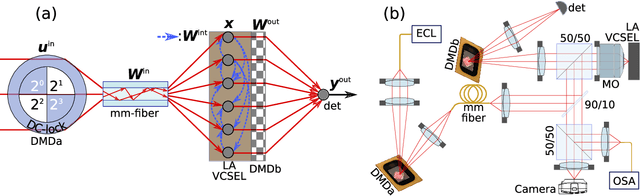
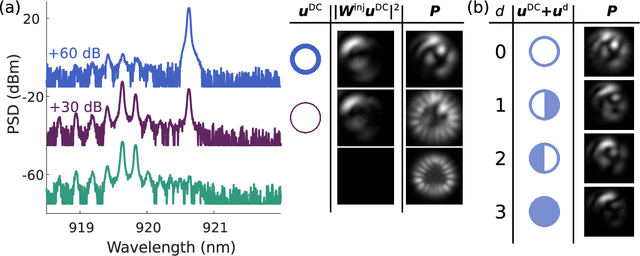
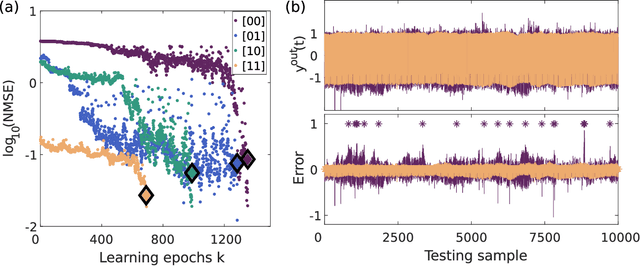
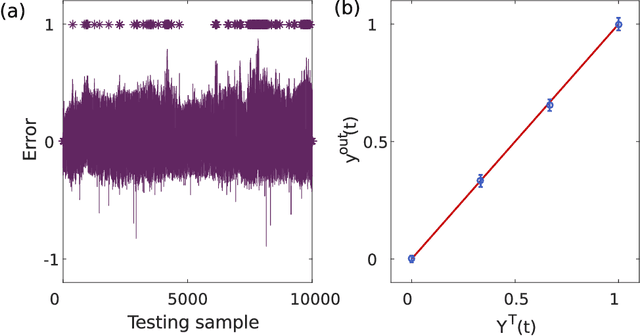
Neural networks are one of the disruptive computing concepts of our time. However, they fundamentally differ from classical, algorithmic computing in a number of fundamental aspects. These differences result in equally fundamental, severe and relevant challenges for neural network computing using current computing substrates. Neural networks urge for parallelism across the entire processor and for a co-location of memory and arithmetic, i.e. beyond von Neumann architectures. Parallelism in particular made photonics a highly promising platform, yet until now scalable and integratable concepts are scarce. Here, we demonstrate for the first time how a fully parallel and fully implemented photonic neural network can be realized using spatially distributed modes of an efficient and fast semiconductor laser. Importantly, all neural network connections are realized in hardware, and our processor produces results without pre- or post-processing. 130+ nodes are implemented in a large-area vertical cavity surface emitting laser, input and output weights are realized via the complex transmission matrix of a multimode fiber and a digital micro-mirror array, respectively. We train the readout weights to perform 2-bit header recognition, a 2-bit XOR and 2-bit digital analog conversion, and obtain < 0.9 10^-3 and 2.9 10^-2 error rates for digit recognition and XOR, respectively. Finally, the digital analog conversion can be realized with a standard deviation of only 5.4 10^-2. Our system is scalable to much larger sizes and to bandwidths in excess of 20 GHz.