 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning State-Tracking from Code Using Linear RNNs
Feb 16, 2026Over the last years, state-tracking tasks, particularly permutation composition, have become a testbed to understand the limits of sequence models architectures like Transformers and RNNs (linear and non-linear). However, these are often sequence-to-sequence tasks: learning to map actions (permutations) to states, which is incompatible with the next-token prediction setting commonly used to train language models. We address this gap by converting permutation composition into code via REPL traces that interleave state-reveals through prints and variable transformations. We show that linear RNNs capable of state-tracking excel also in this setting, while Transformers still fail. Motivated by this representation, we investigate why tracking states in code is generally difficult: actions are not always fully observable. We frame this as tracking the state of a probabilistic finite-state automaton with deterministic state reveals and show that linear RNNs can be worse than non-linear RNNs at tracking states in this setup.
Debugging code world models
Feb 07, 2026Code World Models (CWMs) are language models trained to simulate program execution by predicting explicit runtime state after every executed command. This execution-based world modeling enables internal verification within the model, offering an alternative to natural language chain-of-thought reasoning. However, the sources of errors and the nature of CWMs' limitations remain poorly understood. We study CWMs from two complementary perspectives: local semantic execution and long-horizon state tracking. On real-code benchmarks, we identify two dominant failure regimes. First, dense runtime state reveals produce token-intensive execution traces, leading to token-budget exhaustion on programs with long execution histories. Second, failures disproportionately concentrate in string-valued state, which we attribute to limitations of subword tokenization rather than program structure. To study long-horizon behavior, we use a controlled permutation-tracking benchmark that isolates state propagation under action execution. We show that long-horizon degradation is driven primarily by incorrect action generation: when actions are replaced with ground-truth commands, a Transformer-based CWM propagates state accurately over long horizons, despite known limitations of Transformers in long-horizon state tracking. These findings suggest directions for more efficient supervision and state representations in CWMs that are better aligned with program execution and data types.
Implicit Language Models are RNNs: Balancing Parallelization and Expressivity
Feb 10, 2025State-space models (SSMs) and transformers dominate the language modeling landscape. However, they are constrained to a lower computational complexity than classical recurrent neural networks (RNNs), limiting their expressivity. In contrast, RNNs lack parallelization during training, raising fundamental questions about the trade off between parallelization and expressivity. We propose implicit SSMs, which iterate a transformation until convergence to a fixed point. Theoretically, we show that implicit SSMs implement the non-linear state-transitions of RNNs. Empirically, we find that only approximate fixed-point convergence suffices, enabling the design of a scalable training curriculum that largely retains parallelization, with full convergence required only for a small subset of tokens. Our approach demonstrates superior state-tracking capabilities on regular languages, surpassing transformers and SSMs. We further scale implicit SSMs to natural language reasoning tasks and pretraining of large-scale language models up to 1.3B parameters on 207B tokens - representing, to our knowledge, the largest implicit model trained to date. Notably, our implicit models outperform their explicit counterparts on standard benchmarks.
Training of Physical Neural Networks
Jun 05, 2024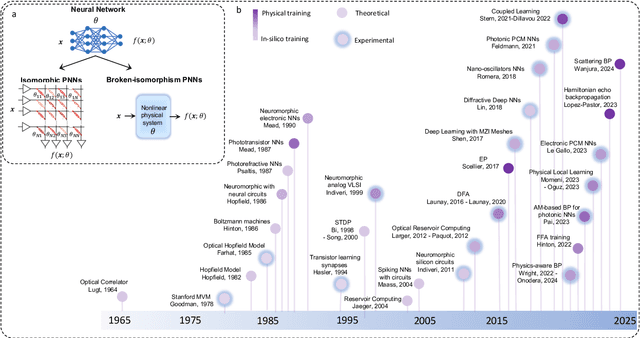
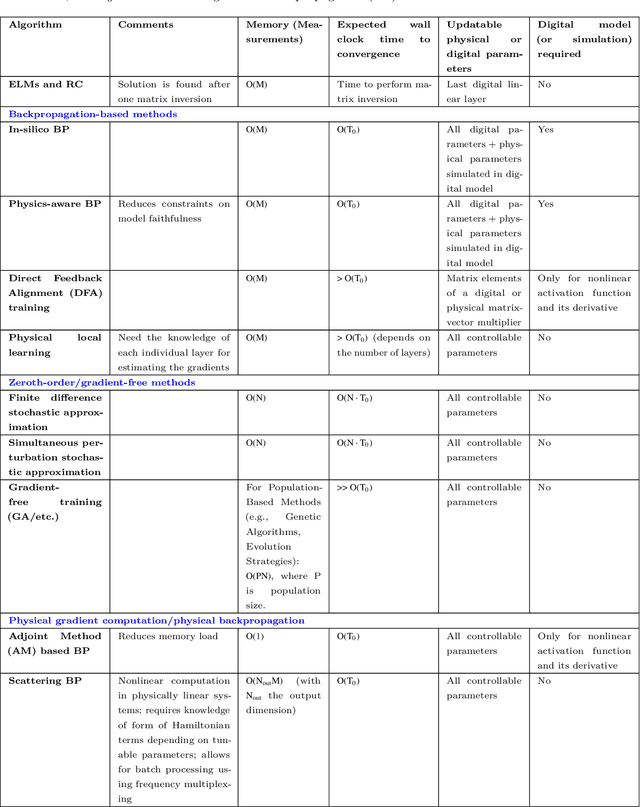
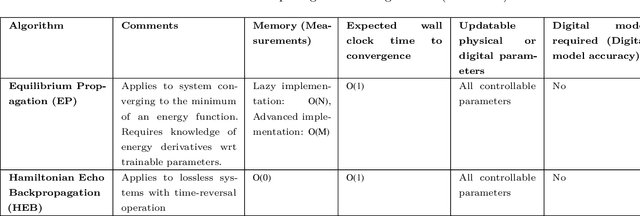
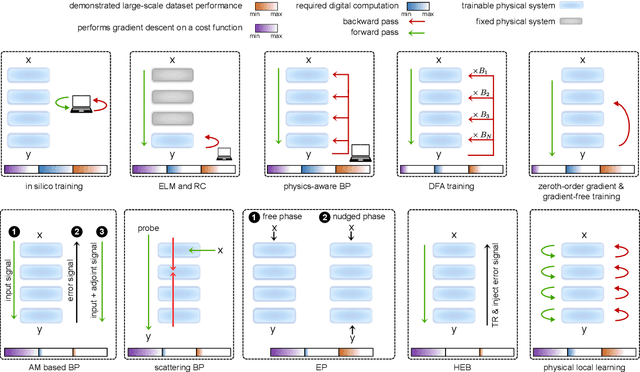
Physical neural networks (PNNs) are a class of neural-like networks that leverage the properties of physical systems to perform computation. While PNNs are so far a niche research area with small-scale laboratory demonstrations, they are arguably one of the most underappreciated important opportunities in modern AI. Could we train AI models 1000x larger than current ones? Could we do this and also have them perform inference locally and privately on edge devices, such as smartphones or sensors? Research over the past few years has shown that the answer to all these questions is likely "yes, with enough research": PNNs could one day radically change what is possible and practical for AI systems. To do this will however require rethinking both how AI models work, and how they are trained - primarily by considering the problems through the constraints of the underlying hardware physics. To train PNNs at large scale, many methods including backpropagation-based and backpropagation-free approaches are now being explored. These methods have various trade-offs, and so far no method has been shown to scale to the same scale and performance as the backpropagation algorithm widely used in deep learning today. However, this is rapidly changing, and a diverse ecosystem of training techniques provides clues for how PNNs may one day be utilized to create both more efficient realizations of current-scale AI models, and to enable unprecedented-scale models.
Backpropagation-free Training of Deep Physical Neural Networks
Apr 20, 2023Recent years have witnessed the outstanding success of deep learning in various fields such as vision and natural language processing. This success is largely indebted to the massive size of deep learning models that is expected to increase unceasingly. This growth of the deep learning models is accompanied by issues related to their considerable energy consumption, both during the training and inference phases, as well as their scalability. Although a number of work based on unconventional physical systems have been proposed which addresses the issue of energy efficiency in the inference phase, efficient training of deep learning models has remained unaddressed. So far, training of digital deep learning models mainly relies on backpropagation, which is not suitable for physical implementation as it requires perfect knowledge of the computation performed in the so-called forward pass of the neural network. Here, we tackle this issue by proposing a simple deep neural network architecture augmented by a biologically plausible learning algorithm, referred to as "model-free forward-forward training". The proposed architecture enables training deep physical neural networks consisting of layers of physical nonlinear systems, without requiring detailed knowledge of the nonlinear physical layers' properties. We show that our method outperforms state-of-the-art hardware-aware training methods by improving training speed, decreasing digital computations, and reducing power consumption in physical systems. We demonstrate the adaptability of the proposed method, even in systems exposed to dynamic or unpredictable external perturbations. To showcase the universality of our approach, we train diverse wave-based physical neural networks that vary in the underlying wave phenomenon and the type of non-linearity they use, to perform vowel and image classification tasks experimentally.
Variational framework for partially-measured physical system control: examples of vision neuroscience and optical random media
Oct 25, 2021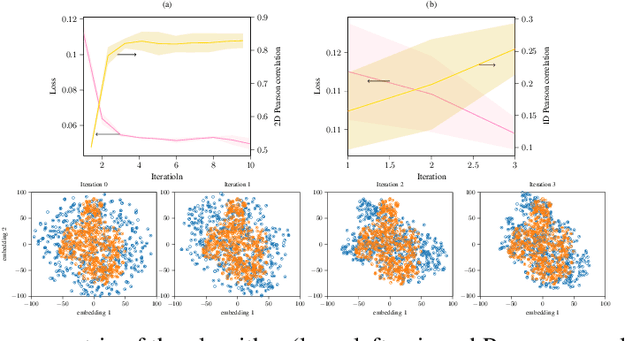

To characterize a physical system to behave as desired, either its underlying governing rules must be known a priori or the system itself be accurately measured. The complexity of full measurements of the system scales with its size. When exposed to real-world conditions, such as perturbations or time-varying settings, the system calibrated for a fixed working condition might require non-trivial re-calibration, a process that could be prohibitively expensive, inefficient and impractical for real-world use cases. In this work, we propose a learning procedure to obtain a desired target output from a physical system. We use Variational Auto-Encoders (VAE) to provide a generative model of the system function and use this model to obtain the required input of the system that produces the target output. We showcase the applicability of our method for two datasets in optical physics and neuroscience.
Multimode Fiber Projector
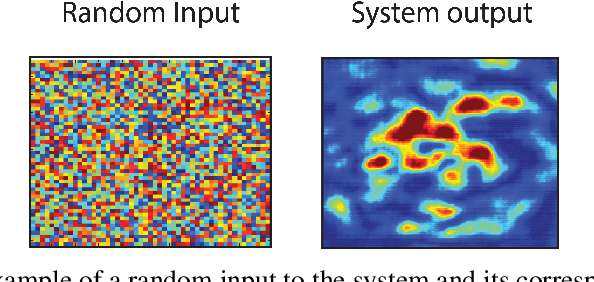
Jun 29, 2019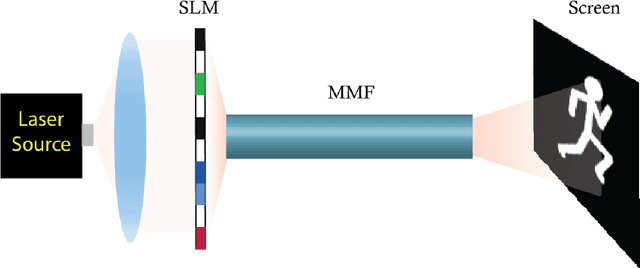
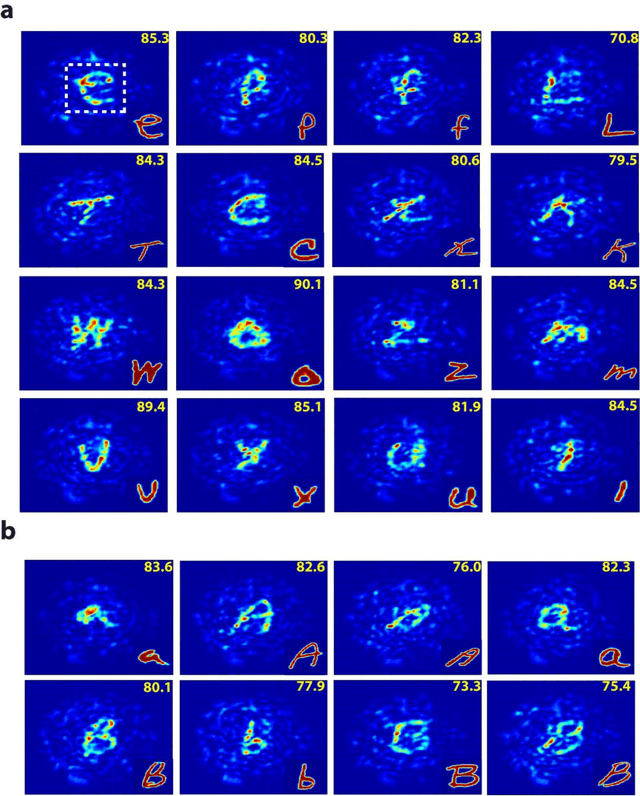
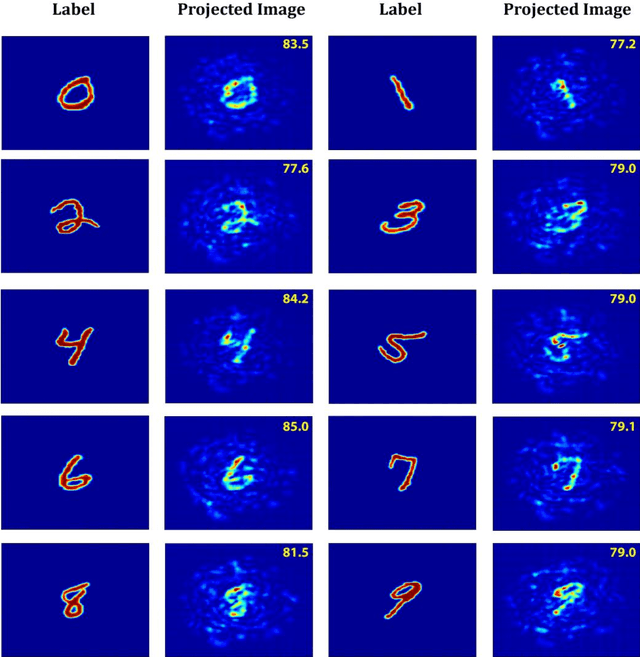

Direct image transmission in multimode fibers (MMFs) is hampered by modal scrambling inside the fiber due to the multimodal nature of the medium. To undo modal scrambling, approaches that either use interferometry to construct a transmission matrix or iterative feedback based wavefront shaping to form an output spot on the camera have been proposed and implemented successfully. The former method entails measuring the complex output field (phase and amplitude) using interferometric systems. The latter, requires scanning the spot by phase conjugation or iterative techniques to form arbitrary shapes, increasing the computational cost. In this work, we show that by using neural networks, we are able to project arbitrary shapes through the MMF without measuring the output phase. Specifically, we demonstrate that our projector network is able to produce input patterns that, when sent through the fiber, form arbitrary shapes on the camera with fidelities (correlation) as high as ~90%. We believe this approach opens up new paths towards imaging and pattern projection for a plethora of applications ranging from tissue imaging, surgical ablations to virtual/augmented reality.