 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavelength-multiplexed massively parallel diffractive optical information storage and image projection
Apr 03, 2026We introduce a wavelength-multiplexed massively parallel diffractive information storage platform composed of dielectric surfaces that are structurally optimized at the wavelength scale using deep learning to store and project thousands of distinct image patterns, each assigned to a unique wavelength. Through numerical simulations in the visible spectrum, we demonstrated that our wavelength-multiplexed diffractive system can store and project over 4,000 independent desired images/patterns within its output field-of-view, with high image quality and minimal crosstalk between spectral channels. Furthermore, in a proof-of-concept experiment, we demonstrated a two-layer diffractive design that stored six distinct patterns and projected them onto the same output field of view at six different wavelengths (500, 548, 596, 644, 692, and 740 nm). This diffractive architecture is scalable and can operate at various parts of the electromagnetic spectrum without the need for material dispersion engineering or redesigning its optimized diffractive layers. The demonstrated storage capacity, reconstruction image fidelity, and wavelength-encoded massively parallel read-out of our diffractive platform offer a compact and fast-access solution for large-scale optical information storage, image projection applications.
Optimal Brain Decomposition for Accurate LLM Low-Rank Approximation
Apr 01, 2026Low-rank decomposition has emerged as an important problem in Large Language Model (LLM) fine-tuning and inference. Through Singular Value Decomposition (SVD), the weight matrix can be factorized into low-rank spaces optimally. Previously, a common practice was to decompose the weight in the activation-whitened space, and then achieve satisfying results. In this work, we propose Optimal Brain Decomposition LLM (OBD-LLM), which studies the decomposition problem in the model space by utilizing second-order Hessian information. Through a rigorous Kronecker-factorization of the Hessian, we show that the decomposition needs to consider both input and output information of the layer, and achieves much better decomposition results compared to input only method. Our loss-aware decomposition method involves a bi-directional whitening on the weight matrix. As a result, OBD-LLM is a closed-form solution for the optimal decomposition of weights in the language model. Remarkably, we achieve ~20-40\% better results than previous state-of-the-art decomposition methods, the SVD-LLM.
Large-scale nonlinear optical computing with incoherent light via linear diffractive systems
Mar 31, 2026Nonlinear computation is essential for various information processing tasks. Optical implementations are attractive because passive light propagation can manipulate high-dimensional signals with extreme throughput and parallelism; yet realizing nonlinear mappings in optical hardware remains challenging due to the weak nonlinearity of optical materials and the large intensities required to induce nonlinear interactions. This challenge is further amplified in many systems that operate with incoherent illumination, motivating a coherence-aware framework for scalable optical nonlinear processing. Here, we show that linear optical systems, in particular, optimized diffractive processors comprising passive surfaces, can perform large-scale nonlinear function approximation under spatially incoherent or partially coherent illumination, when preceded by intensity-only input encoding. We quantify how the accuracy of the nonlinear function approximation varies with the degree of parallelism, the number of diffractive layers, and the number of trainable diffractive features. Numerical results demonstrate snapshot computation of up to one million distinct nonlinear functions in a single forward pass through a diffractive processor, with the function outputs spatially multiplexed and read out using densely packed detectors at the output. We further provide a proof-of-concept experimental demonstration under incoherent illumination from a liquid crystal display (LCD), enabled by a model-free in situ learning strategy that jointly optimizes the diffractive profile and detector readout geometry in the presence of hardware imperfections and misalignments. Our findings establish diffractive processors as a massively parallel universal function approximator for both spatially incoherent and partially coherent illumination.
Mamba Learns in Context: Structure-Aware Domain Generalization for Multi-Task Point Cloud Understanding
Mar 21, 2026While recent Transformer and Mamba architectures have advanced point cloud representation learning, they are typically developed for single-task or single-domain settings. Directly applying them to multi-task domain generalization (DG) leads to degraded performance. Transformers effectively model global dependencies but suffer from quadratic attention cost and lack explicit structural ordering, whereas Mamba offers linear-time recurrence yet often depends on coordinate-driven serialization, which is sensitive to viewpoint changes and missing regions, causing structural drift and unstable sequential modeling. In this paper, we propose Structure-Aware Domain Generalization (SADG), a Mamba-based In-Context Learning framework that preserves structural hierarchy across domains and tasks. We design structure-aware serialization (SAS) that generates transformation-invariant sequences using centroid-based topology and geodesic curvature continuity. We further devise hierarchical domain-aware modeling (HDM) that stabilizes cross-domain reasoning by consolidating intra-domain structure and fusing inter-domain relations. At test time, we introduce a lightweight spectral graph alignment (SGA) that shifts target features toward source prototypes in the spectral domain without updating model parameters, ensuring structure-preserving test-time feature shifting. In addition, we introduce MP3DObject, a real-scan object dataset for multi-task DG evaluation. Comprehensive experiments demonstrate that the proposed approach improves structural fidelity and consistently outperforms state-of-the-art methods across multiple tasks including reconstruction, denoising, and registration.
QuRL: Efficient Reinforcement Learning with Quantized Rollout
Feb 15, 2026Reinforcement learning with verifiable rewards (RLVR) has become a trending paradigm for training reasoning large language models (LLMs). However, due to the autoregressive decoding nature of LLMs, the rollout process becomes the efficiency bottleneck of RL training, consisting of up to 70\% of the total training time. In this work, we propose Quantized Reinforcement Learning (QuRL) that uses a quantized actor for accelerating the rollout. We address two challenges in QuRL. First, we propose Adaptive Clipping Range (ACR) that dynamically adjusts the clipping ratio based on the policy ratio between the full-precision actor and the quantized actor, which is essential for mitigating long-term training collapse. Second, we identify the weight update problem, where weight changes between RL steps are extremely small, making it difficult for the quantization operation to capture them effectively. We mitigate this problem through the invariant scaling technique that reduces quantization noise and increases weight update. We evaluate our method with INT8 and FP8 quantization experiments on DeepScaleR and DAPO, and achieve 20% to 80% faster rollout during training.
Snapshot 3D image projection using a diffractive decoder
Dec 23, 20253D image display is essential for next-generation volumetric imaging; however, dense depth multiplexing for 3D image projection remains challenging because diffraction-induced cross-talk rapidly increases as the axial image planes get closer. Here, we introduce a 3D display system comprising a digital encoder and a diffractive optical decoder, which simultaneously projects different images onto multiple target axial planes with high axial resolution. By leveraging multi-layer diffractive wavefront decoding and deep learning-based end-to-end optimization, the system achieves high-fidelity depth-resolved 3D image projection in a snapshot, enabling axial plane separations on the order of a wavelength. The digital encoder leverages a Fourier encoder network to capture multi-scale spatial and frequency-domain features from input images, integrates axial position encoding, and generates a unified phase representation that simultaneously encodes all images to be axially projected in a single snapshot through a jointly-optimized diffractive decoder. We characterized the impact of diffractive decoder depth, output diffraction efficiency, spatial light modulator resolution, and axial encoding density, revealing trade-offs that govern axial separation and 3D image projection quality. We further demonstrated the capability to display volumetric images containing 28 axial slices, as well as the ability to dynamically reconfigure the axial locations of the image planes, performed on demand. Finally, we experimentally validated the presented approach, demonstrating close agreement between the measured results and the target images. These results establish the diffractive 3D display system as a compact and scalable framework for depth-resolved snapshot 3D image projection, with potential applications in holographic displays, AR/VR interfaces, and volumetric optical computing.
GNN-Enabled Robust Hybrid Beamforming with Score-Based CSI Generation and Denoising
Nov 10, 2025Accurate Channel State Information (CSI) is critical for Hybrid Beamforming (HBF) tasks. However, obtaining high-resolution CSI remains challenging in practical wireless communication systems. To address this issue, we propose to utilize Graph Neural Networks (GNNs) and score-based generative models to enable robust HBF under imperfect CSI conditions. Firstly, we develop the Hybrid Message Graph Attention Network (HMGAT) which updates both node and edge features through node-level and edge-level message passing. Secondly, we design a Bidirectional Encoder Representations from Transformers (BERT)-based Noise Conditional Score Network (NCSN) to learn the distribution of high-resolution CSI, facilitating CSI generation and data augmentation to further improve HMGAT's performance. Finally, we present a Denoising Score Network (DSN) framework and its instantiation, termed DeBERT, which can denoise imperfect CSI under arbitrary channel error levels, thereby facilitating robust HBF. Experiments on DeepMIMO urban datasets demonstrate the proposed models' superior generalization, scalability, and robustness across various HBF tasks with perfect and imperfect CSI.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
GAME: Learning Multimodal Interactions via Graph Structures for Personality Trait Estimation
May 05, 2025



Apparent personality analysis from short videos poses significant chal-lenges due to the complex interplay of visual, auditory, and textual cues. In this paper, we propose GAME, a Graph-Augmented Multimodal Encoder designed to robustly model and fuse multi-source features for automatic personality prediction. For the visual stream, we construct a facial graph and introduce a dual-branch Geo Two-Stream Network, which combines Graph Convolutional Networks (GCNs) and Convolutional Neural Net-works (CNNs) with attention mechanisms to capture both structural and appearance-based facial cues. Complementing this, global context and iden-tity features are extracted using pretrained ResNet18 and VGGFace back-bones. To capture temporal dynamics, frame-level features are processed by a BiGRU enhanced with temporal attention modules. Meanwhile, audio representations are derived from the VGGish network, and linguistic se-mantics are captured via the XLM-Roberta transformer. To achieve effective multimodal integration, we propose a Channel Attention-based Fusion module, followed by a Multi-Layer Perceptron (MLP) regression head for predicting personality traits. Extensive experiments show that GAME con-sistently outperforms existing methods across multiple benchmarks, vali-dating its effectiveness and generalizability.
GPTQv2: Efficient Finetuning-Free Quantization for Asymmetric Calibration
Apr 03, 2025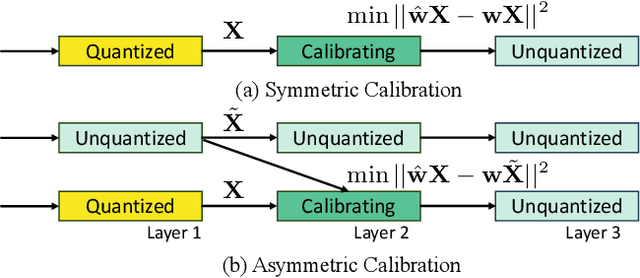
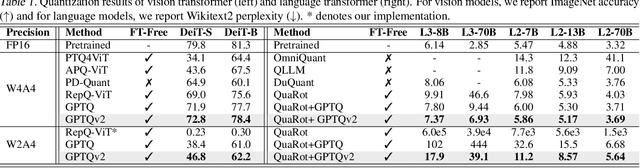
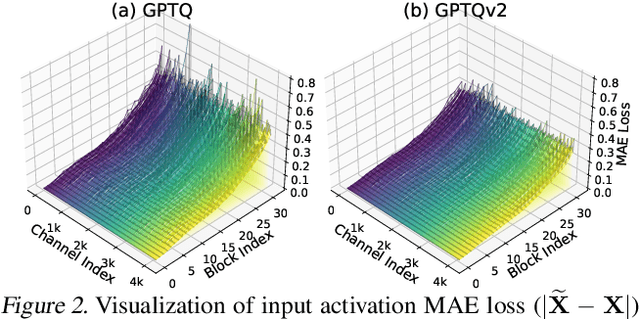
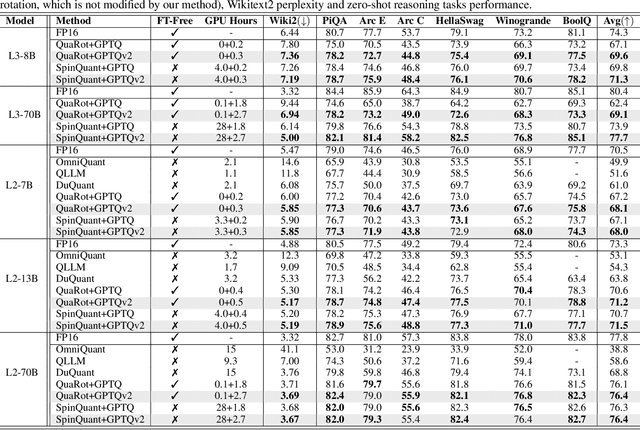
We introduce GPTQv2, a novel finetuning-free quantization method for compressing large-scale transformer architectures. Unlike the previous GPTQ method, which independently calibrates each layer, we always match the quantized layer's output to the exact output in the full-precision model, resulting in a scheme that we call asymmetric calibration. Such a scheme can effectively reduce the quantization error accumulated in previous layers. We analyze this problem using optimal brain compression to derive a close-formed solution. The new solution explicitly minimizes the quantization error as well as the accumulated asymmetry error. Furthermore, we utilize various techniques to parallelize the solution calculation, including channel parallelization, neuron decomposition, and Cholesky reformulation for matrix fusion. As a result, GPTQv2 is easy to implement, simply using 20 more lines of code than GPTQ but improving its performance under low-bit quantization. Remarkably, on a single GPU, we quantize a 405B language transformer as well as EVA-02 the rank first vision transformer that achieves 90% pretraining Imagenet accuracy. Code is available at github.com/Intelligent-Computing-Lab-Yale/GPTQv2.