 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI2V-GS: Infrastructure-to-Vehicle View Transformation with Gaussian Splatting for Autonomous Driving Data Generation
Jul 31, 2025Vast and high-quality data are essential for end-to-end autonomous driving systems. However, current driving data is mainly collected by vehicles, which is expensive and inefficient. A potential solution lies in synthesizing data from real-world images. Recent advancements in 3D reconstruction demonstrate photorealistic novel view synthesis, highlighting the potential of generating driving data from images captured on the road. This paper introduces a novel method, I2V-GS, to transfer the Infrastructure view To the Vehicle view with Gaussian Splatting. Reconstruction from sparse infrastructure viewpoints and rendering under large view transformations is a challenging problem. We adopt the adaptive depth warp to generate dense training views. To further expand the range of views, we employ a cascade strategy to inpaint warped images, which also ensures inpainting content is consistent across views. To further ensure the reliability of the diffusion model, we utilize the cross-view information to perform a confidenceguided optimization. Moreover, we introduce RoadSight, a multi-modality, multi-view dataset from real scenarios in infrastructure views. To our knowledge, I2V-GS is the first framework to generate autonomous driving datasets with infrastructure-vehicle view transformation. Experimental results demonstrate that I2V-GS significantly improves synthesis quality under vehicle view, outperforming StreetGaussian in NTA-Iou, NTL-Iou, and FID by 45.7%, 34.2%, and 14.9%, respectively.
ITPNet: Towards Instantaneous Trajectory Prediction for Autonomous Driving
Dec 10, 2024



Trajectory prediction of agents is crucial for the safety of autonomous vehicles, whereas previous approaches usually rely on sufficiently long-observed trajectory to predict the future trajectory of the agents. However, in real-world scenarios, it is not realistic to collect adequate observed locations for moving agents, leading to the collapse of most prediction models. For instance, when a moving car suddenly appears and is very close to an autonomous vehicle because of the obstruction, it is quite necessary for the autonomous vehicle to quickly and accurately predict the future trajectories of the car with limited observed trajectory locations. In light of this, we focus on investigating the task of instantaneous trajectory prediction, i.e., two observed locations are available during inference. To this end, we propose a general and plug-and-play instantaneous trajectory prediction approach, called ITPNet. Specifically, we propose a backward forecasting mechanism to reversely predict the latent feature representations of unobserved historical trajectories of the agent based on its two observed locations and then leverage them as complementary information for future trajectory prediction. Meanwhile, due to the inevitable existence of noise and redundancy in the predicted latent feature representations, we further devise a Noise Redundancy Reduction Former, aiming at to filter out noise and redundancy from unobserved trajectories and integrate the filtered features and observed features into a compact query for future trajectory predictions. In essence, ITPNet can be naturally compatible with existing trajectory prediction models, enabling them to gracefully handle the case of instantaneous trajectory prediction. Extensive experiments on the Argoverse and nuScenes datasets demonstrate ITPNet outperforms the baselines, and its efficacy with different trajectory prediction models.
On the Road to Portability: Compressing End-to-End Motion Planner for Autonomous Driving
Mar 02, 2024End-to-end motion planning models equipped with deep neural networks have shown great potential for enabling full autonomous driving. However, the oversized neural networks render them impractical for deployment on resource-constrained systems, which unavoidably requires more computational time and resources during reference.To handle this, knowledge distillation offers a promising approach that compresses models by enabling a smaller student model to learn from a larger teacher model. Nevertheless, how to apply knowledge distillation to compress motion planners has not been explored so far. In this paper, we propose PlanKD, the first knowledge distillation framework tailored for compressing end-to-end motion planners. First, considering that driving scenes are inherently complex, often containing planning-irrelevant or even noisy information, transferring such information is not beneficial for the student planner. Thus, we design an information bottleneck based strategy to only distill planning-relevant information, rather than transfer all information indiscriminately. Second, different waypoints in an output planned trajectory may hold varying degrees of importance for motion planning, where a slight deviation in certain crucial waypoints might lead to a collision. Therefore, we devise a safety-aware waypoint-attentive distillation module that assigns adaptive weights to different waypoints based on the importance, to encourage the student to accurately mimic more crucial waypoints, thereby improving overall safety. Experiments demonstrate that our PlanKD can boost the performance of smaller planners by a large margin, and significantly reduce their reference time.
GANet: Goal Area Network for Motion Forecasting
Sep 20, 2022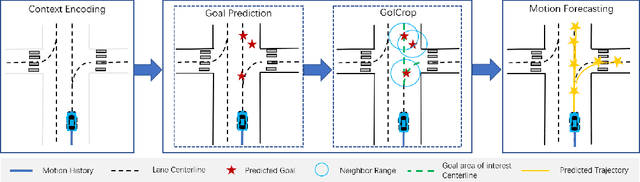
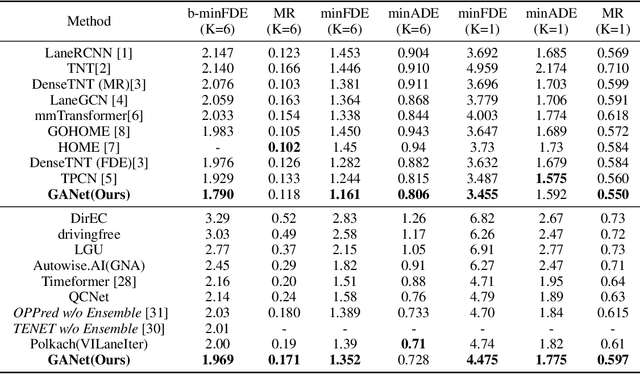
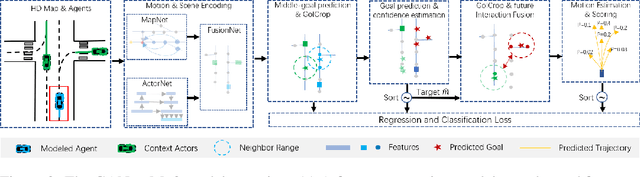
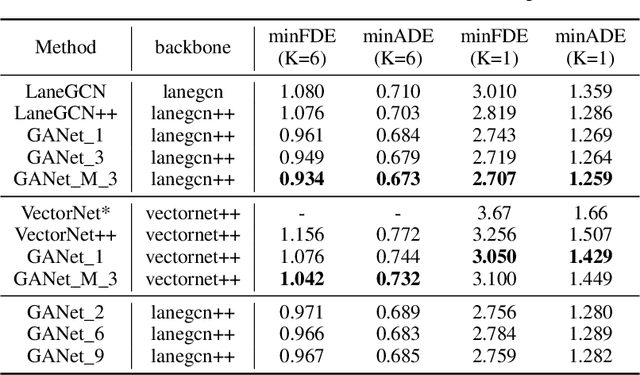
Predicting the future motion of road participants is crucial for autonomous driving but is extremely challenging due to staggering motion uncertainty. Recently, most motion forecasting methods resort to the goal-based strategy, i.e., predicting endpoints of motion trajectories as conditions to regress the entire trajectories, so that the search space of solution can be reduced. However, accurate goal coordinates are hard to predict and evaluate. In addition, the point representation of the destination limits the utilization of a rich road context, leading to inaccurate prediction results in many cases. Goal area, i.e., the possible destination area, rather than goal coordinate, could provide a more soft constraint for searching potential trajectories by involving more tolerance and guidance. In view of this, we propose a new goal area-based framework, named Goal Area Network (GANet), for motion forecasting, which models goal areas rather than exact goal coordinates as preconditions for trajectory prediction, performing more robustly and accurately. Specifically, we propose a GoICrop (Goal Area of Interest) operator to effectively extract semantic lane features in goal areas and model actors' future interactions, which benefits a lot for future trajectory estimations. GANet ranks the 1st on the leaderboard of Argoverse Challenge among all public literature (till the paper submission), and its source codes will be released.
CORE: Consistent Representation Learning for Face Forgery Detection
Jun 06, 2022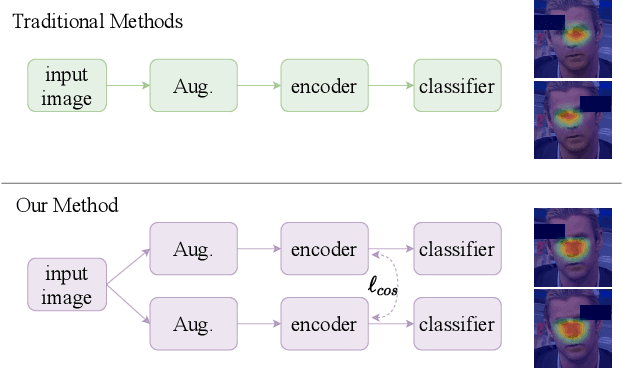
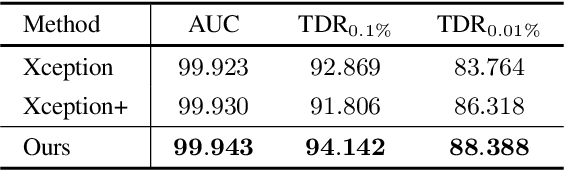
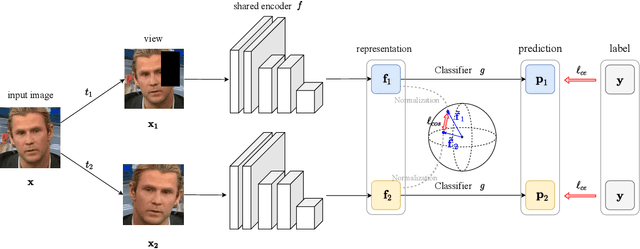
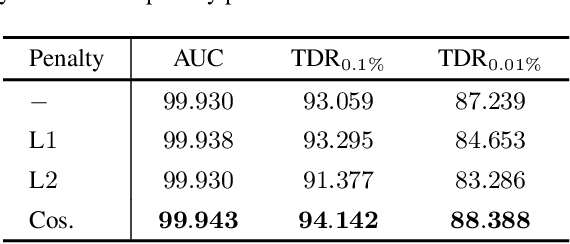
Face manipulation techniques develop rapidly and arouse widespread public concerns. Despite that vanilla convolutional neural networks achieve acceptable performance, they suffer from the overfitting issue. To relieve this issue, there is a trend to introduce some erasing-based augmentations. We find that these methods indeed attempt to implicitly induce more consistent representations for different augmentations via assigning the same label for different augmented images. However, due to the lack of explicit regularization, the consistency between different representations is less satisfactory. Therefore, we constrain the consistency of different representations explicitly and propose a simple yet effective framework, COnsistent REpresentation Learning (CORE). Specifically, we first capture the different representations with different augmentations, then regularize the cosine distance of the representations to enhance the consistency. Extensive experiments (in-dataset and cross-dataset) demonstrate that CORE performs favorably against state-of-the-art face forgery detection methods.
Sliding Sequential CVAE with Time Variant Socially-aware Rethinking for Trajectory Prediction
Oct 28, 2021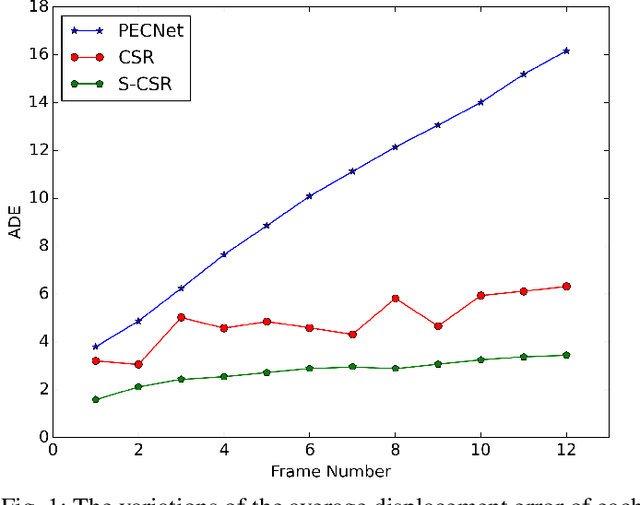
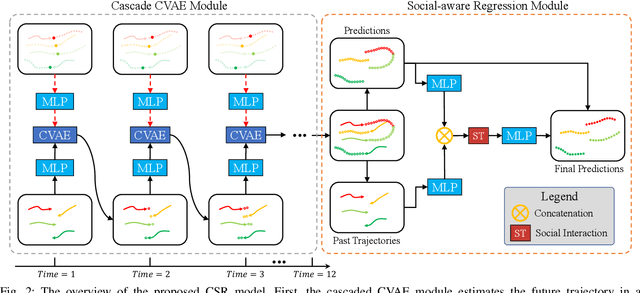
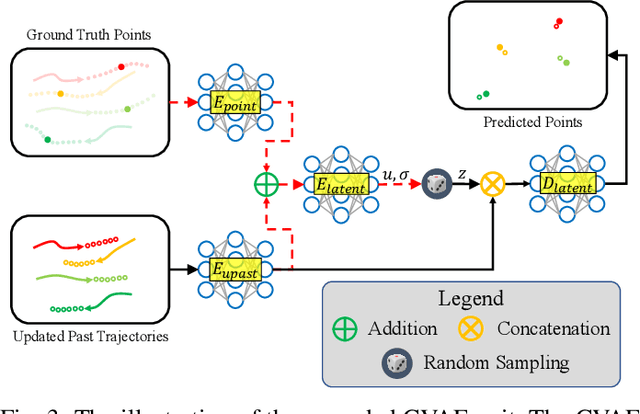
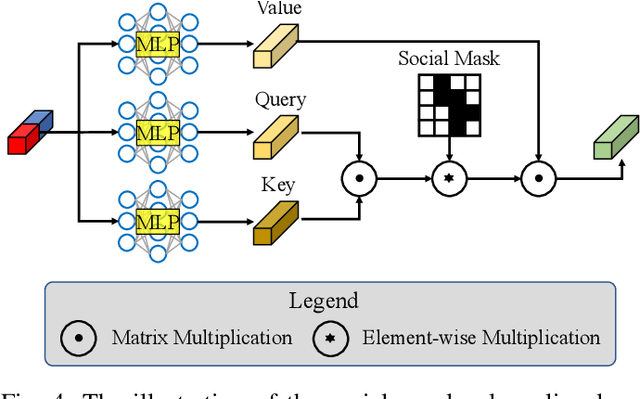
Pedestrian trajectory prediction is a key technology in many applications such as video surveillance, social robot navigation, and autonomous driving, and significant progress has been made in this research topic. However, there remain two limitations of previous studies. First, with the continuation of time, the prediction error at each time step increases significantly, causing the final displacement error to be impossible to ignore. Second, the prediction results of multiple pedestrians might be impractical in the prediction horizon, i.e., the predicted trajectories might collide with each other. To overcome these limitations, this work proposes a novel trajectory prediction method called CSR, which consists of a cascaded conditional variational autoencoder (CVAE) module and a socially-aware regression module. The cascaded CVAE module first estimates the future trajectories in a sequential pattern. Specifically, each CVAE concatenates the past trajectories and the predicted points so far as the input and predicts the location at the following time step. Then, the socially-aware regression module generates offsets from the estimated future trajectories to produce the socially compliant final predictions, which are more reasonable and accurate results than the estimated trajectories. Moreover, considering the large model parameters of the cascaded CVAE module, a slide CVAE module is further exploited to improve the model efficiency using one shared CVAE, in a slidable manner. Experiments results demonstrate that the proposed method exhibits improvements over state-of-the-art method on the Stanford Drone Dataset (SDD) and ETH/UCY of approximately 38.0% and 22.2%, respectively.
An Efficient Generation Method based on Dynamic Curvature of the Reference Curve for Robust Trajectory Planning
Dec 29, 2020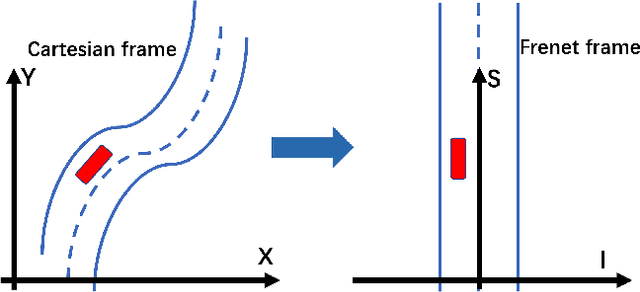
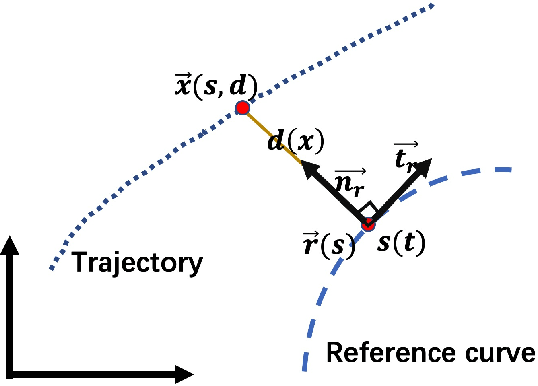
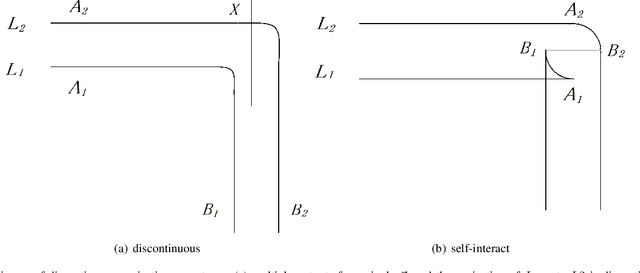
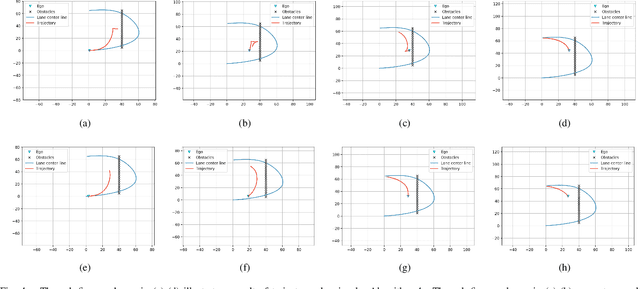
Trajectory planning is a fundamental task on various autonomous driving platforms, such as social robotics and self-driving cars. Many trajectory planning algorithms use a reference curve based Frenet frame with time to reduce the planning dimension. However, there is a common implicit assumption in classic trajectory planning approaches, which is that the generated trajectory should follow the reference curve continuously. This assumption is not always true in real applications and it might cause some undesired issues in planning. One issue is that the projection of the planned trajectory onto the reference curve maybe discontinuous. Then, some segments on the reference curve are not the image of any part of the planned path. Another issue is that the planned path might self-intersect when following a simple reference curve continuously. The generated trajectories are unnatural and suboptimal ones when these issues happen. In this paper, we firstly demonstrate these issues and then introduce an efficient trajectory generation method which uses a new transformation from the Cartesian frame to Frenet frames. Experimental results on a simulated street scenario demonstrated the effectiveness of the proposed method.
Robust Trajectory Forecasting for Multiple Intelligent Agents in Dynamic Scene
May 27, 2020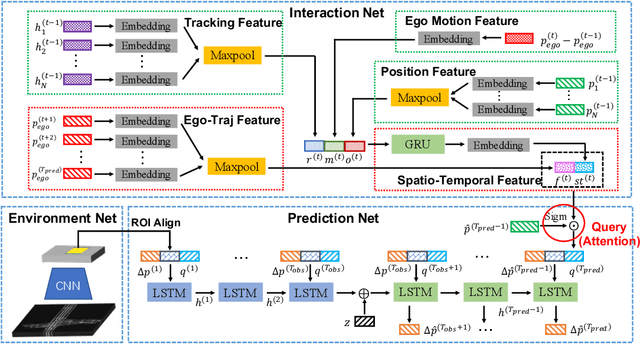
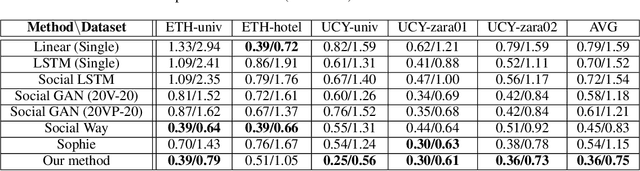
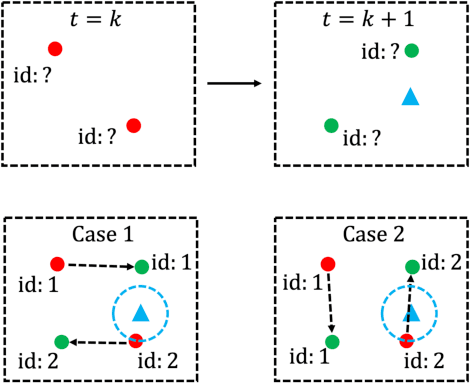
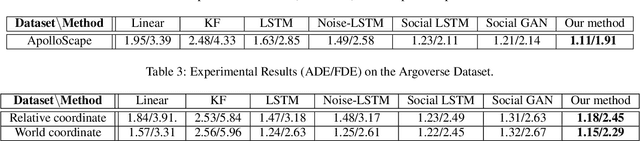
Trajectory forecasting, or trajectory prediction, of multiple interacting agents in dynamic scenes, is an important problem for many applications, such as robotic systems and autonomous driving. The problem is a great challenge because of the complex interactions among the agents and their interactions with the surrounding scenes. In this paper, we present a novel method for the robust trajectory forecasting of multiple intelligent agents in dynamic scenes. The proposed method consists of three major interrelated components: an interaction net for global spatiotemporal interactive feature extraction, an environment net for decoding dynamic scenes (i.e., the surrounding road topology of an agent), and a prediction net that combines the spatiotemporal feature, the scene feature, the past trajectories of agents and some random noise for the robust trajectory prediction of agents. Experiments on pedestrian-walking and vehicle-pedestrian heterogeneous datasets demonstrate that the proposed method outperforms the state-of-the-art prediction methods in terms of prediction accuracy.
VisionNet: A Drivable-space-based Interactive Motion Prediction Network for Autonomous Driving
Jan 08, 2020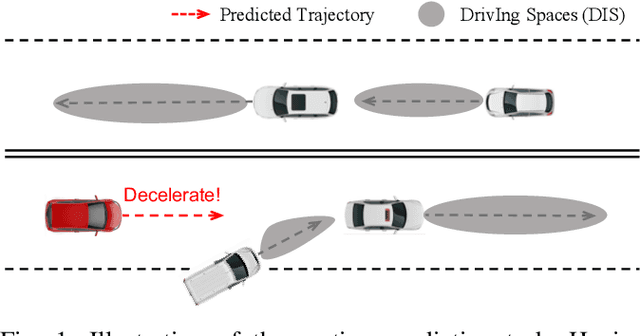
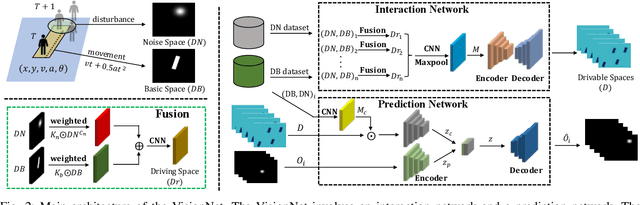
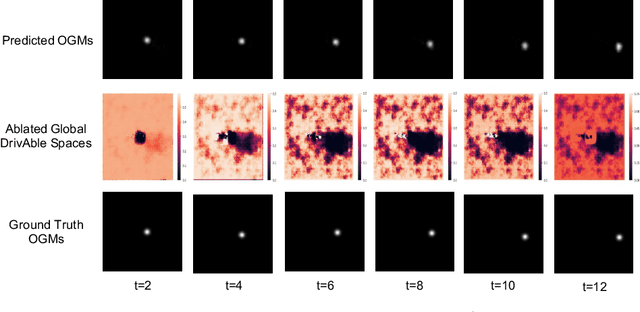
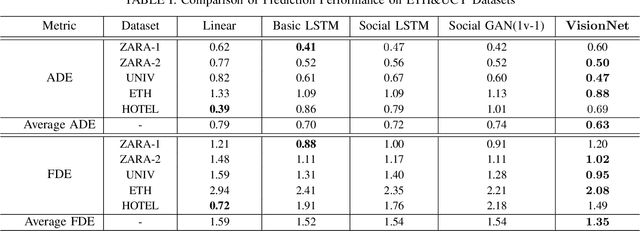
The comprehension of environmental traffic situation largely ensures the driving safety of autonomous vehicles. Recently, the mission has been investigated by plenty of researches, while it is hard to be well addressed due to the limitation of collective influence in complex scenarios. These approaches model the interactions through the spatial relations between the target obstacle and its neighbors. However, they oversimplify the challenge since the training stage of the interactions lacks effective supervision. As a result, these models are far from promising. More intuitively, we transform the problem into calculating the interaction-aware drivable spaces and propose the CNN-based VisionNet for trajectory prediction. The VisionNet accepts a sequence of motion states, i.e., location, velocity, and acceleration, to estimate the future drivable spaces. The reified interactions significantly increase the interpretation ability of the VisionNet and refine the prediction. To further advance the performance, we propose an interactive loss to guide the generation of the drivable spaces. Experiments on multiple public datasets demonstrate the effectiveness of the proposed VisionNet.
StarNet: Pedestrian Trajectory Prediction using Deep Neural Network in Star Topology
Jun 05, 2019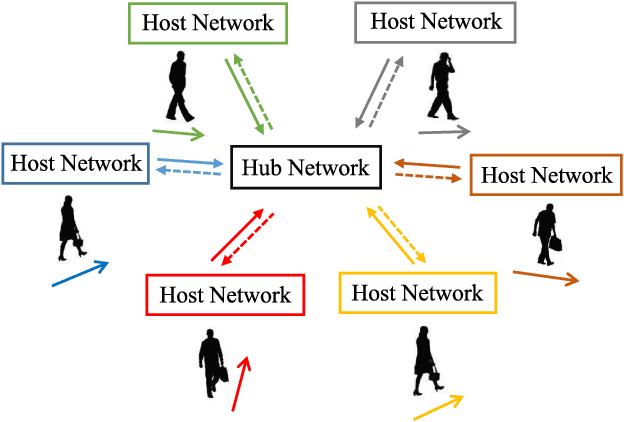
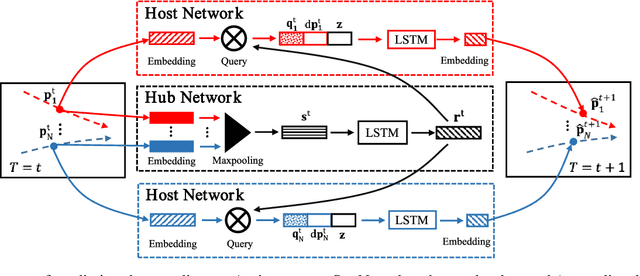
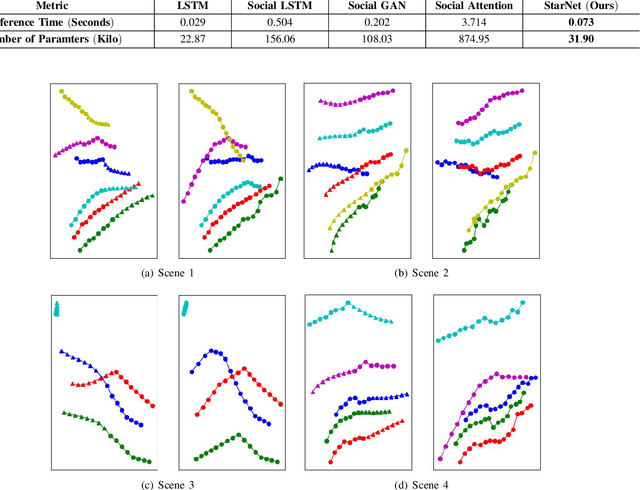
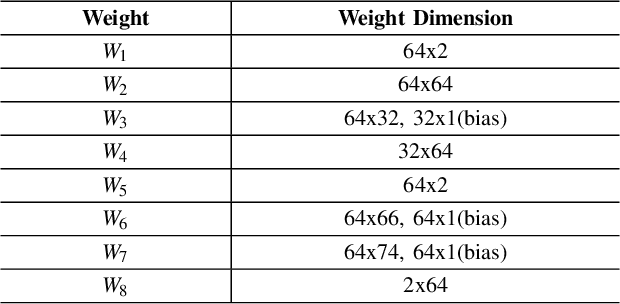
Pedestrian trajectory prediction is crucial for many important applications. This problem is a great challenge because of complicated interactions among pedestrians. Previous methods model only the pairwise interactions between pedestrians, which not only oversimplifies the interactions among pedestrians but also is computationally inefficient. In this paper, we propose a novel model StarNet to deal with these issues. StarNet has a star topology which includes a unique hub network and multiple host networks. The hub network takes observed trajectories of all pedestrians to produce a comprehensive description of the interpersonal interactions. Then the host networks, each of which corresponds to one pedestrian, consult the description and predict future trajectories. The star topology gives StarNet two advantages over conventional models. First, StarNet is able to consider the collective influence among all pedestrians in the hub network, making more accurate predictions. Second, StarNet is computationally efficient since the number of host network is linear to the number of pedestrians. Experiments on multiple public datasets demonstrate that StarNet outperforms multiple state-of-the-arts by a large margin in terms of both accuracy and efficiency.