 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysAgent: Automating Physics-Based 4D Synthesis via Trajectory-Grounded Multi-Agent Feedback
Jun 07, 2026Achieving fully automated, physically plausible 3D motion synthesis is a core objective in graphics and generative AI. However, configuring complex environmental force fields still relies entirely on manual expert intervention, creating a severe bottleneck for large-scale simulation data generation. Existing automated methods primarily focus on material optimization and exhibit severe modality gaps and technical flaws when applied to the vastly more complex force field optimization space: naive Large Language Models (LLMs) lack underlying simulation feedback, causing severe physical inaccuracies, while traditional Score Distillation Sampling (SDS) suffers from sluggish gradients, local optima entrapment, and a mathematical inability to dynamically switch discrete force fields. To address this, we propose PhysAgent, the first simulator-in-the-loop multi-agent framework that leverages multimodal inputs for automated, physically grounded 4D synthesis. By decoupling intrinsic materials from extrinsic dynamics, PhysAgent utilizes a Semantic Agent equipped with an externalized Force Field Skill module to master simulation rules and generate valid initializations. Subsequently, the Refine Agents, driven by Trajectory-Grounded Multi-Agent Feedback, leverage vision foundation models to extract dense point trajectories from rendered frames. By converting these explicit motion trajectories into structured textual descriptors, the agent harnesses LLM commonsense reasoning to execute zero-shot macroscopic leaps, effectively escaping local optima and dynamically switching discrete force fields. Extensive experiments demonstrate that PhysAgent rapidly generates stable, diverse physical scenes from arbitrary multimodal prompts, significantly outperforming existing baselines in both generation diversity and physical accuracy.
Where to Refine, When to Stop: Rethinking Redundancy via Latent Discrepancy for Efficient Visual Autoregressive Generation
May 29, 2026Visual Autoregressive (VAR) models deliver high-quality image generation but suffer from significant inference latency at high resolutions. Recent acceleration approaches most rely on heuristic measures with layer features to prune tokens. Such heuristics are sensitive to complex contextual semantics, leading to inaccurate identification of redundant computation and poor adaptability across prompts. We rethink redundancy in VAR from the perspective of its impact on pixel-space generation and introduce Latent Discrepancy. This unified metric quantifies a token's contribution by measuring the change in model states during generation. Our analysis shows that redundancy is more accurately identified when guided by image latent or pixel-space signals. We further observed that in classifier-free guidance (CFG), the convergence trend of the discrepancy between conditional and unconditional branches exhibits high dynamics with different prompts. Based on these findings, we propose LD-Pruning (Latent Discrepancy Pruning), a training-free framework that removes redundancy via latent discrepancy by integrating decoding-free region selection and adaptive unconditional-branch skipping. Extensive experiments show that LD-Pruning substantially reduces inference latency while maintaining high generation quality, achieving up to 2.35x speedup on Infinity-8B.
Training-free Motion Factorization for Compositional Video Generation
Mar 10, 2026Compositional video generation aims to synthesize multiple instances with diverse appearance and motion, which is widely applicable in real-world scenarios. However, current approaches mainly focus on binding semantics, neglecting to understand diverse motion categories specified in prompts. In this paper, we propose a motion factorization framework that decomposes complex motion into three primary categories: motionlessness, rigid motion, and non-rigid motion. Specifically, our framework follows a planning before generation paradigm. (1) During planning, we reason about motion laws on the motion graph to obtain frame-wise changes in the shape and position of each instance. This alleviates semantic ambiguities in the user prompt by organizing it into a structured representation of instances and their interactions. (2) During generation, we modulate the synthesis of distinct motion categories in a disentangled manner. Conditioned on the motion cues, guidance branches stabilize appearance in motionless regions, preserve rigid-body geometry, and regularize local non-rigid deformations. Crucially, our two modules are model-agnostic, which can be seamlessly incorporated into various diffusion model architectures. Extensive experiments demonstrate that our framework achieves impressive performance in motion synthesis on real-world benchmarks. Our code will be released soon.
Astro: Activation-guided Structured Regularization for Outlier-Robust LLM Post-Training Quantization
Feb 07, 2026Weight-only post-training quantization (PTQ) is crucial for efficient Large Language Model (LLM) deployment but suffers from accuracy degradation caused by weight and activation outliers. Existing mitigation strategies often face critical limitations: they either yield insufficient outlier suppression or incur significant deployment inefficiencies, such as inference latency, heavy preprocessing, or reliance on complex operator fusion. To resolve these limitations, we leverage a key insight: over-parameterized LLMs often converge to Flat Minima, implying a vast equivalent solution space where weights can be adjusted without compromising accuracy. Building on this, we propose Astro, an Activation-guided Structured Regularization framework designed to suppress the negative effects of outliers in a hardware-friendly and efficient manner. Leveraging the activation-guided regularization objective, Astro actively reconstructs intrinsically robust weights, aggressively suppressing weight outliers corresponding to high-magnitude activations without sacrificing model accuracy. Crucially, Astro introduces zero inference latency and is orthogonal to mainstream quantization methods like GPTQ. Extensive experiments show that Astro achieves highly competitive performance; notably, on LLaMA-2-7B, it achieves better performance than complex learning-based rotation methods with almost 1/3 of the quantization time.
SE-MLP Model for Predicting Prior Acceleration Features in Penetration Signals
Dec 29, 2025Accurate identification of the penetration process relies heavily on prior feature values of penetration acceleration. However, these feature values are typically obtained through long simulation cycles and expensive computations. To overcome this limitation, this paper proposes a multi-layer Perceptron architecture, termed squeeze and excitation multi-layer perceptron (SE-MLP), which integrates a channel attention mechanism with residual connections to enable rapid prediction of acceleration feature values. Using physical parameters under different working conditions as inputs, the model outputs layer-wise acceleration features, thereby establishing a nonlinear mapping between physical parameters and penetration characteristics. Comparative experiments against conventional MLP, XGBoost, and Transformer models demonstrate that SE-MLP achieves superior prediction accuracy, generalization, and stability. Ablation studies further confirm that both the channel attention module and residual structure contribute significantly to performance gains. Numerical simulations and range recovery tests show that the discrepancies between predicted and measured acceleration peaks and pulse widths remain within acceptable engineering tolerances. These results validate the feasibility and engineering applicability of the proposed method and provide a practical basis for rapidly generating prior feature values for penetration fuzes.
Collaborative Human-Robot Surgery for Mandibular Angle Split Osteotomy: Optical Tracking based Approach
Jul 10, 2025Mandibular Angle Split Osteotomy (MASO) is a significant procedure in oral and maxillofacial surgery. Despite advances in technique and instrumentation, its success still relies heavily on the surgeon's experience. In this work, a human-robot collaborative system is proposed to perform MASO according to a preoperative plan and under guidance of a surgeon. A task decomposition methodology is used to divide the collaborative surgical procedure into three subtasks: (1) positional control and (2) orientation control, both led by the robot for precise alignment; and (3) force-control, managed by surgeon to ensure safety. Additionally, to achieve patient tracking without the need for a skull clamp, an optical tracking system (OTS) is utilized. Movement of the patient mandibular is measured with an optical-based tracker mounted on a dental occlusal splint. A registration method and Robot-OTS calibration method are introduced to achieve reliable navigation within our framework. The experiments of drilling were conducted on the realistic phantom model, which demonstrated that the average error between the planned and actual drilling points is 1.85mm.
ITPNet: Towards Instantaneous Trajectory Prediction for Autonomous Driving
Dec 10, 2024



Trajectory prediction of agents is crucial for the safety of autonomous vehicles, whereas previous approaches usually rely on sufficiently long-observed trajectory to predict the future trajectory of the agents. However, in real-world scenarios, it is not realistic to collect adequate observed locations for moving agents, leading to the collapse of most prediction models. For instance, when a moving car suddenly appears and is very close to an autonomous vehicle because of the obstruction, it is quite necessary for the autonomous vehicle to quickly and accurately predict the future trajectories of the car with limited observed trajectory locations. In light of this, we focus on investigating the task of instantaneous trajectory prediction, i.e., two observed locations are available during inference. To this end, we propose a general and plug-and-play instantaneous trajectory prediction approach, called ITPNet. Specifically, we propose a backward forecasting mechanism to reversely predict the latent feature representations of unobserved historical trajectories of the agent based on its two observed locations and then leverage them as complementary information for future trajectory prediction. Meanwhile, due to the inevitable existence of noise and redundancy in the predicted latent feature representations, we further devise a Noise Redundancy Reduction Former, aiming at to filter out noise and redundancy from unobserved trajectories and integrate the filtered features and observed features into a compact query for future trajectory predictions. In essence, ITPNet can be naturally compatible with existing trajectory prediction models, enabling them to gracefully handle the case of instantaneous trajectory prediction. Extensive experiments on the Argoverse and nuScenes datasets demonstrate ITPNet outperforms the baselines, and its efficacy with different trajectory prediction models.
DREAM: Domain-agnostic Reverse Engineering Attributes of Black-box Model
Dec 08, 2024



Deep learning models are usually black boxes when deployed on machine learning platforms. Prior works have shown that the attributes (e.g., the number of convolutional layers) of a target black-box model can be exposed through a sequence of queries. There is a crucial limitation: these works assume the training dataset of the target model is known beforehand and leverage this dataset for model attribute attack. However, it is difficult to access the training dataset of the target black-box model in reality. Therefore, whether the attributes of a target black-box model could be still revealed in this case is doubtful. In this paper, we investigate a new problem of black-box reverse engineering, without requiring the availability of the target model's training dataset. We put forward a general and principled framework DREAM, by casting this problem as out-of-distribution (OOD) generalization. In this way, we can learn a domain-agnostic meta-model to infer the attributes of the target black-box model with unknown training data. This makes our method one of the kinds that can gracefully apply to an arbitrary domain for model attribute reverse engineering with strong generalization ability. Extensive experimental results demonstrate the superiority of our proposed method over the baselines.
* arXiv admin note: substantial text overlap with arXiv:2307.10997
Remember, Retrieve and Generate: Understanding Infinite Visual Concepts as Your Personalized Assistant
Oct 17, 2024
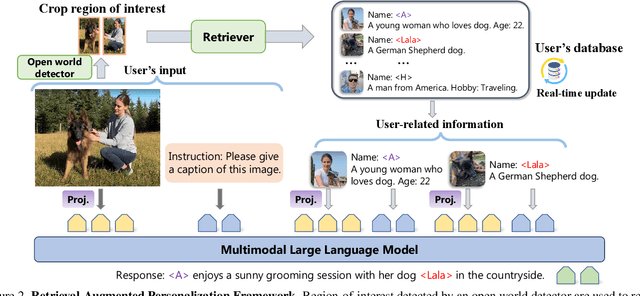


The development of large language models (LLMs) has significantly enhanced the capabilities of multimodal LLMs (MLLMs) as general assistants. However, lack of user-specific knowledge still restricts their application in human's daily life. In this paper, we introduce the Retrieval Augmented Personalization (RAP) framework for MLLMs' personalization. Starting from a general MLLM, we turn it into a personalized assistant in three steps. (a) Remember: We design a key-value database to store user-related information, e.g., user's name, avatar and other attributes. (b) Retrieve: When the user initiates a conversation, RAP will retrieve relevant information from the database using a multimodal retriever. (c) Generate: The input query and retrieved concepts' information are fed into MLLMs to generate personalized, knowledge-augmented responses. Unlike previous methods, RAP allows real-time concept editing via updating the external database. To further improve generation quality and alignment with user-specific information, we design a pipeline for data collection and create a specialized dataset for personalized training of MLLMs. Based on the dataset, we train a series of MLLMs as personalized multimodal assistants. By pretraining on large-scale dataset, RAP-MLLMs can generalize to infinite visual concepts without additional finetuning. Our models demonstrate outstanding flexibility and generation quality across a variety of tasks, such as personalized image captioning, question answering and visual recognition. The code, data and models are available at https://github.com/Hoar012/RAP-MLLM.
Fira: Can We Achieve Full-rank Training of LLMs Under Low-rank Constraint?
Oct 02, 2024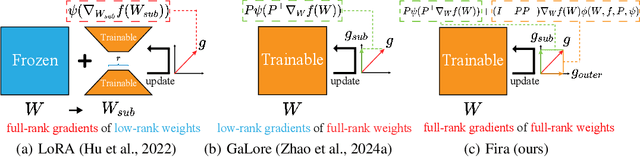
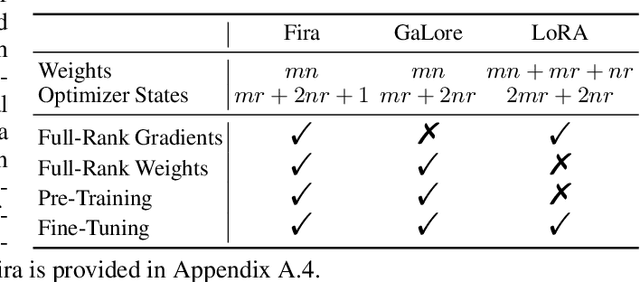
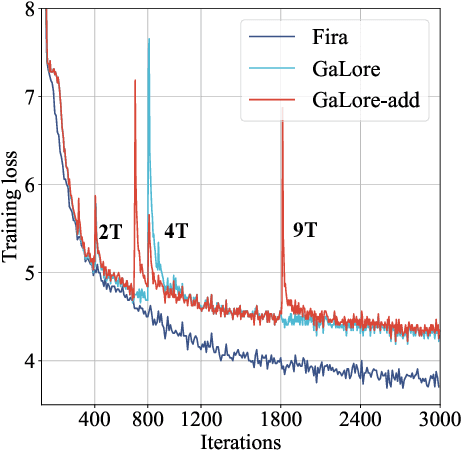
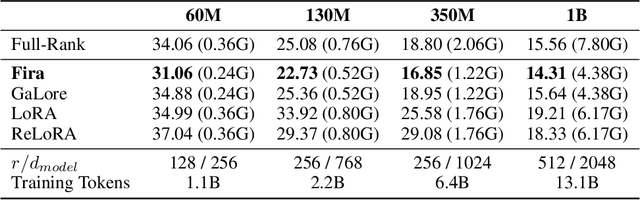
Low-rank training has emerged as a promising approach for reducing memory usage in training Large Language Models (LLMs). Previous methods either rely on decomposing weight matrices (e.g., LoRA), or seek to decompose gradient matrices (e.g., GaLore) to ensure reduced memory consumption. However, both of them constrain the training in a low-rank subspace, thus inevitably leading to sub-optimal performance. This raises a question: whether it is possible to consistently preserve the low-rank constraint for memory efficiency, while achieving full-rank training (i.e., training with full-rank gradients of full-rank weights) to avoid inferior outcomes? In this paper, we propose a new plug-and-play training framework for LLMs called Fira, as the first attempt to achieve this goal. First, we observe an interesting phenomenon during LLM training: the scaling impact of adaptive optimizers (e.g., Adam) on the gradient norm remains similar from low-rank to full-rank training. Based on this observation, we propose a norm-based scaling method, which utilizes the scaling impact of low-rank optimizers as substitutes for that of original full-rank optimizers to enable full-rank training. In this way, we can preserve the low-rank constraint in the optimizer while achieving full-rank training for better performance. Moreover, we find that there are sudden gradient rises during the optimization process, potentially causing loss spikes. To address this, we further put forward a norm-growth limiter to smooth the gradient via regulating the relative increase of gradient norms. Extensive experiments on the pre-training and fine-tuning of LLMs show that Fira outperforms both LoRA and GaLore, achieving performance that is comparable to or even better than full-rank training.