 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning From a Steady Hand: A Weakly Supervised Agent for Robot Assistance under Microscopy
Jan 28, 2026This paper rethinks steady-hand robotic manipulation by using a weakly supervised framework that fuses calibration-aware perception with admittance control. Unlike conventional automation that relies on labor-intensive 2D labeling, our framework leverages reusable warm-up trajectories to extract implicit spatial information, thereby achieving calibration-aware, depth-resolved perception without the need for external fiducials or manual depth annotation. By explicitly characterizing residuals from observation and calibration models, the system establishes a task-space error budget from recorded warm-ups. The uncertainty budget yields a lateral closed-loop accuracy of approx. 49 micrometers at 95% confidence (worst-case testing subset) and a depth accuracy of <= 291 micrometers at 95% confidence bound during large in-plane moves. In a within-subject user study (N=8), the learned agent reduces overall NASA-TLX workload by 77.1% relative to the simple steady-hand assistance baseline. These results demonstrate that the weakly supervised agent improves the reliability of microscope-guided biomedical micromanipulation without introducing complex setup requirements, offering a practical framework for microscope-guided intervention.
Hydra: Marker-Free RGB-D Hand-Eye Calibration
Apr 29, 2025This work presents an RGB-D imaging-based approach to marker-free hand-eye calibration using a novel implementation of the iterative closest point (ICP) algorithm with a robust point-to-plane (PTP) objective formulated on a Lie algebra. Its applicability is demonstrated through comprehensive experiments using three well known serial manipulators and two RGB-D cameras. With only three randomly chosen robot configurations, our approach achieves approximately 90% successful calibrations, demonstrating 2-3x higher convergence rates to the global optimum compared to both marker-based and marker-free baselines. We also report 2 orders of magnitude faster convergence time (0.8 +/- 0.4 s) for 9 robot configurations over other marker-free methods. Our method exhibits significantly improved accuracy (5 mm in task space) over classical approaches (7 mm in task space) whilst being marker-free. The benchmarking dataset and code are open sourced under Apache 2.0 License, and a ROS 2 integration with robot abstraction is provided to facilitate deployment.
Evaluating Robotic Approach Techniques for the Insertion of a Straight Instrument into a Vitreoretinal Surgery Trocar
Jan 13, 2025

Advances in vitreoretinal robotic surgery enable precise techniques for gene therapies. This study evaluates three robotic approaches using the 7-DoF robotic arm for docking a micro-precise tool to a trocar: fully co-manipulated, hybrid co-manipulated/teleoperated, and hybrid with camera assistance. The fully co-manipulated approach was the fastest but had a 42% success rate. Hybrid methods showed higher success rates (91.6% and 100%) and completed tasks within 2 minutes. NASA Task Load Index (TLX) assessments indicated lower physical demand and effort for hybrid approaches.
Learning-Based Autonomous Navigation, Benchmark Environments and Simulation Framework for Endovascular Interventions
Oct 02, 2024



Endovascular interventions are a life-saving treatment for many diseases, yet suffer from drawbacks such as radiation exposure and potential scarcity of proficient physicians. Robotic assistance during these interventions could be a promising support towards these problems. Research focusing on autonomous endovascular interventions utilizing artificial intelligence-based methodologies is gaining popularity. However, variability in assessment environments hinders the ability to compare and contrast the efficacy of different approaches, primarily due to each study employing a unique evaluation framework. In this study, we present deep reinforcement learning-based autonomous endovascular device navigation on three distinct digital benchmark interventions: BasicWireNav, ArchVariety, and DualDeviceNav. The benchmark interventions were implemented with our modular simulation framework stEVE (simulated EndoVascular Environment). Autonomous controllers were trained solely in simulation and evaluated in simulation and on physical test benches with camera and fluoroscopy feedback. Autonomous control for BasicWireNav and ArchVariety reached high success rates and was successfully transferred from the simulated training environment to the physical test benches, while autonomous control for DualDeviceNav reached a moderate success rate. The experiments demonstrate the feasibility of stEVE and its potential for transferring controllers trained in simulation to real-world scenarios. Nevertheless, they also reveal areas that offer opportunities for future research. This study demonstrates the transferability of autonomous controllers from simulation to the real world in endovascular navigation and lowers the entry barriers and increases the comparability of research on endovascular assistance systems by providing open-source training scripts, benchmarks and the stEVE framework.
Vision and Contact based Optimal Control for Autonomous Trocar Docking
Jul 31, 2024Future operating theatres will be equipped with robots to perform various surgical tasks including, for example, endoscope control. Human-in-the-loop supervisory control architectures where the surgeon selects from several autonomous sequences is already being successfully applied in preclinical tests. Inserting an endoscope into a trocar or introducer is a key step for every keyhole surgical procedure -- hereafter we will only refer to this device as a "trocar". Our goal is to develop a controller for autonomous trocar docking. Autonomous trocar docking is a version of the peg-in-hole problem. Extensive work in the robotics literature addresses this problem. The peg-in-hole problem has been widely studied in the context of assembly where, typically, the hole is considered static and rigid to interaction. In our case, however, the trocar is not fixed and responds to interaction. We consider a variety of surgical procedures where surgeons will utilize contact between the endoscope and trocar in order to complete the insertion successfully. To the best of our knowledge, we have not found literature that explores this particular generalization of the problem directly. Our primary contribution in this work is an optimal control formulation for automated trocar docking. We use a nonlinear optimization program to model the task, minimizing a cost function subject to constraints to find optimal joint configurations. The controller incorporates a geometric model for insertion and a force-feedback (FF) term to ensure patient safety by preventing excessive interaction forces with the trocar. Experiments, demonstrated on a real hardware lab setup, validate the approach. Our method successfully achieves trocar insertion on our real robot lab setup, and simulation trials demonstrate its ability to reduce interaction forces.
Semi-Autonomous Laparoscopic Robot Docking with Learned Hand-Eye Information Fusion
May 09, 2024In this study, we introduce a novel shared-control system for key-hole docking operations, combining a commercial camera with occlusion-robust pose estimation and a hand-eye information fusion technique. This system is used to enhance docking precision and force-compliance safety. To train a hand-eye information fusion network model, we generated a self-supervised dataset using this docking system. After training, our pose estimation method showed improved accuracy compared to traditional methods, including observation-only approaches, hand-eye calibration, and conventional state estimation filters. In real-world phantom experiments, our approach demonstrated its effectiveness with reduced position dispersion (1.23\pm 0.81 mm vs. 2.47 \pm 1.22 mm) and force dispersion (0.78\pm 0.57 N vs. 1.15 \pm 0.97 N) compared to the control group. These advancements in semi-autonomy co-manipulation scenarios enhance interaction and stability. The study presents an anti-interference, steady, and precision solution with potential applications extending beyond laparoscopic surgery to other minimally invasive procedures.
RetiGen: A Framework for Generalized Retinal Diagnosis Using Multi-View Fundus Images
Mar 22, 2024



This study introduces a novel framework for enhancing domain generalization in medical imaging, specifically focusing on utilizing unlabelled multi-view colour fundus photographs. Unlike traditional approaches that rely on single-view imaging data and face challenges in generalizing across diverse clinical settings, our method leverages the rich information in the unlabelled multi-view imaging data to improve model robustness and accuracy. By incorporating a class balancing method, a test-time adaptation technique and a multi-view optimization strategy, we address the critical issue of domain shift that often hampers the performance of machine learning models in real-world applications. Experiments comparing various state-of-the-art domain generalization and test-time optimization methodologies show that our approach consistently outperforms when combined with existing baseline and state-of-the-art methods. We also show our online method improves all existing techniques. Our framework demonstrates improvements in domain generalization capabilities and offers a practical solution for real-world deployment by facilitating online adaptation to new, unseen datasets. Our code is available at https://github.com/zgy600/RetiGen .
Rethinking Low-quality Optical Flow in Unsupervised Surgical Instrument Segmentation
Mar 15, 2024
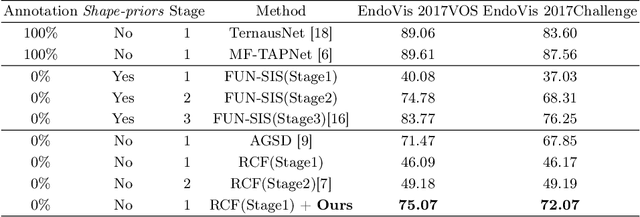
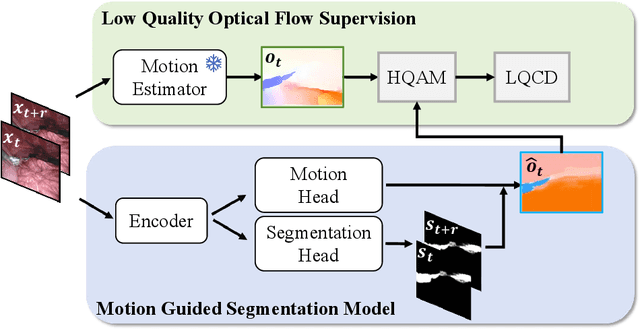
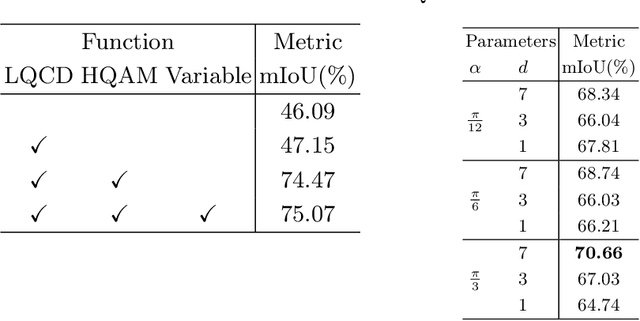
Video-based surgical instrument segmentation plays an important role in robot-assisted surgeries. Unlike supervised settings, unsupervised segmentation relies heavily on motion cues, which are challenging to discern due to the typically lower quality of optical flow in surgical footage compared to natural scenes. This presents a considerable burden for the advancement of unsupervised segmentation techniques. In our work, we address the challenge of enhancing model performance despite the inherent limitations of low-quality optical flow. Our methodology employs a three-pronged approach: extracting boundaries directly from the optical flow, selectively discarding frames with inferior flow quality, and employing a fine-tuning process with variable frame rates. We thoroughly evaluate our strategy on the EndoVis2017 VOS dataset and Endovis2017 Challenge dataset, where our model demonstrates promising results, achieving a mean Intersection-over-Union (mIoU) of 0.75 and 0.72, respectively. Our findings suggest that our approach can greatly decrease the need for manual annotations in clinical environments and may facilitate the annotation process for new datasets. The code is available at https://github.com/wpr1018001/Rethinking-Low-quality-Optical-Flow.git
ArcSin: Adaptive ranged cosine Similarity injected noise for Language-Driven Visual Tasks
Feb 27, 2024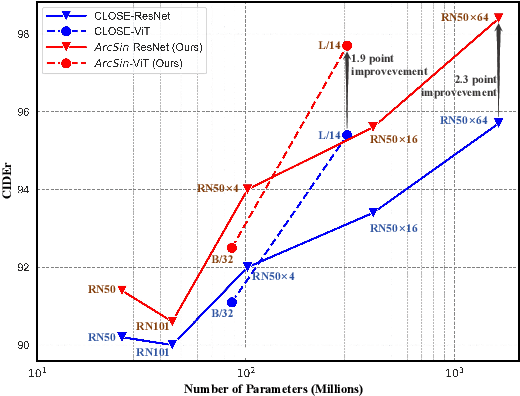
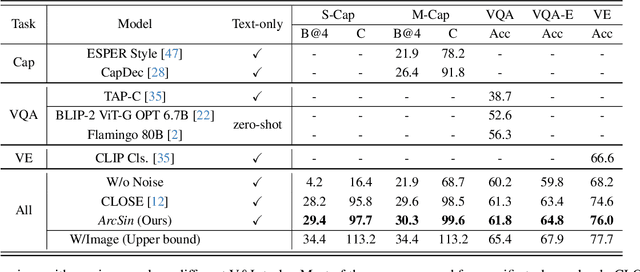

In this study, we address the challenging task of bridging the modality gap between learning from language and inference for visual tasks, including Visual Question Answering (VQA), Image Captioning (IC) and Visual Entailment (VE). We train models for these tasks in a zero-shot cross-modal transfer setting, a domain where the previous state-of-the-art method relied on the fixed scale noise injection, often compromising the semantic content of the original modality embedding. To combat it, we propose a novel method called Adaptive ranged cosine Similarity injected noise (ArcSin). First, we introduce an innovative adaptive noise scale that effectively generates the textual elements with more variability while preserving the original text feature's integrity. Second, a similarity pool strategy is employed, expanding the domain generalization potential by broadening the overall noise scale. This dual strategy effectively widens the scope of the original domain while safeguarding content integrity. Our empirical results demonstrate that these models closely rival those trained on images in terms of performance. Specifically, our method exhibits substantial improvements over the previous state-of-the-art, achieving gains of 1.9 and 1.1 CIDEr points in S-Cap and M-Cap, respectively. Additionally, we observe increases of 1.5 percentage points (pp), 1.4 pp, and 1.4 pp in accuracy for VQA, VQA-E, and VE, respectively, pushing the boundaries of what is achievable within the constraints of image-trained model benchmarks. The code will be released.
Excitation Trajectory Optimization for Dynamic Parameter Identification Using Virtual Constraints in Hands-on Robotic System
Jan 29, 2024

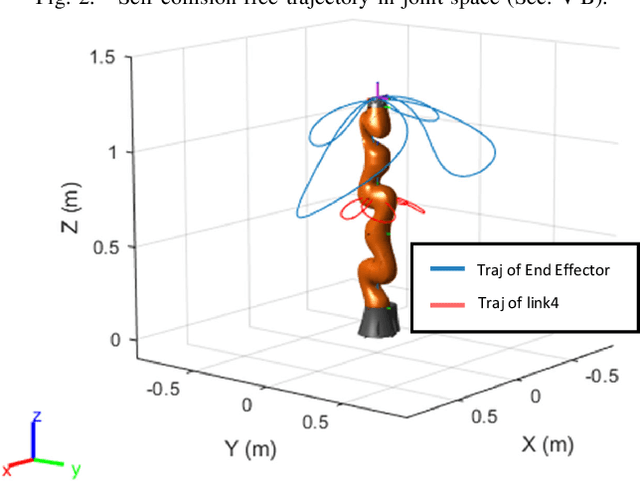
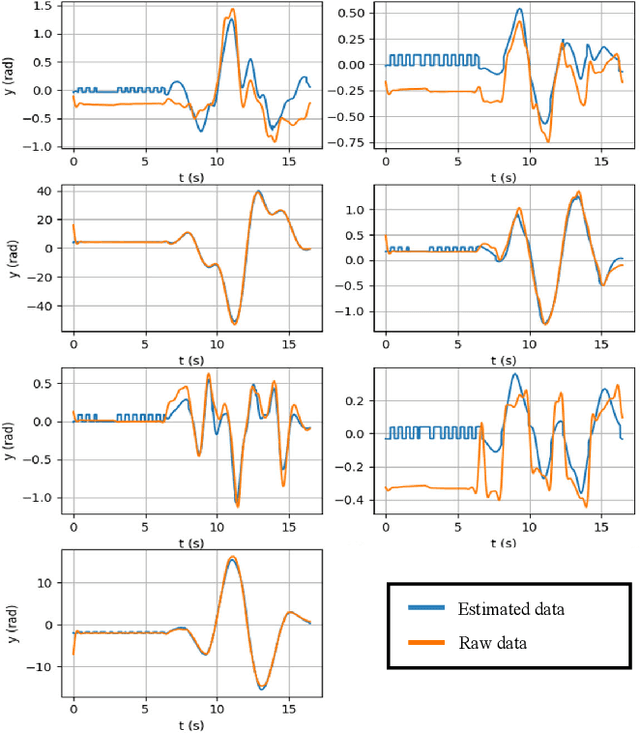
This paper proposes a novel, more computationally efficient method for optimizing robot excitation trajectories for dynamic parameter identification, emphasizing self-collision avoidance. This addresses the system identification challenges for getting high-quality training data associated with co-manipulated robotic arms that can be equipped with a variety of tools, a common scenario in industrial but also clinical and research contexts. Utilizing the Unified Robotics Description Format (URDF) to implement a symbolic Python implementation of the Recursive Newton-Euler Algorithm (RNEA), the approach aids in dynamically estimating parameters such as inertia using regression analyses on data from real robots. The excitation trajectory was evaluated and achieved on par criteria when compared to state-of-the-art reported results which didn't consider self-collision and tool calibrations. Furthermore, physical Human-Robot Interaction (pHRI) admittance control experiments were conducted in a surgical context to evaluate the derived inverse dynamics model showing a 30.1\% workload reduction by the NASA TLX questionnaire.