 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision and Contact based Optimal Control for Autonomous Trocar Docking
Jul 31, 2024Future operating theatres will be equipped with robots to perform various surgical tasks including, for example, endoscope control. Human-in-the-loop supervisory control architectures where the surgeon selects from several autonomous sequences is already being successfully applied in preclinical tests. Inserting an endoscope into a trocar or introducer is a key step for every keyhole surgical procedure -- hereafter we will only refer to this device as a "trocar". Our goal is to develop a controller for autonomous trocar docking. Autonomous trocar docking is a version of the peg-in-hole problem. Extensive work in the robotics literature addresses this problem. The peg-in-hole problem has been widely studied in the context of assembly where, typically, the hole is considered static and rigid to interaction. In our case, however, the trocar is not fixed and responds to interaction. We consider a variety of surgical procedures where surgeons will utilize contact between the endoscope and trocar in order to complete the insertion successfully. To the best of our knowledge, we have not found literature that explores this particular generalization of the problem directly. Our primary contribution in this work is an optimal control formulation for automated trocar docking. We use a nonlinear optimization program to model the task, minimizing a cost function subject to constraints to find optimal joint configurations. The controller incorporates a geometric model for insertion and a force-feedback (FF) term to ensure patient safety by preventing excessive interaction forces with the trocar. Experiments, demonstrated on a real hardware lab setup, validate the approach. Our method successfully achieves trocar insertion on our real robot lab setup, and simulation trials demonstrate its ability to reduce interaction forces.
Robust Path Planning via Learning from Demonstrations for Robotic Catheters in Deformable Environments
Feb 01, 2024Navigation through tortuous and deformable vessels using catheters with limited steering capability underscores the need for reliable path planning. State-of-the-art path planners do not fully account for the deformable nature of the environment. This work proposes a robust path planner via a learning from demonstrations method, named Curriculum Generative Adversarial Imitation Learning (C-GAIL). This path planning framework takes into account the interaction between steerable catheters and vessel walls and the deformable property of vessels. In-silico comparative experiments show that the proposed network achieves smaller targeting errors, and a higher success rate, compared to a state-of-the-art approach based on GAIL. The in-vitro validation experiments demonstrate that the path generated by the proposed C-GAIL path planner aligns better with the actual steering capability of the pneumatic artificial muscle-driven catheter utilized in this study. Therefore, the proposed approach can provide enhanced support to the user in navigating the catheter towards the target with greater precision, in contrast to the conventional centerline-following technique. The targeting and tracking errors are 1.26$\pm$0.55mm and 5.18$\pm$3.48mm, respectively. The proposed path planning framework exhibits superior performance in managing uncertainty associated with vessel deformation, thereby resulting in lower tracking errors.
Autonomous Navigation for Robot-assisted Intraluminal and Endovascular Procedures: A Systematic Review
May 06, 2023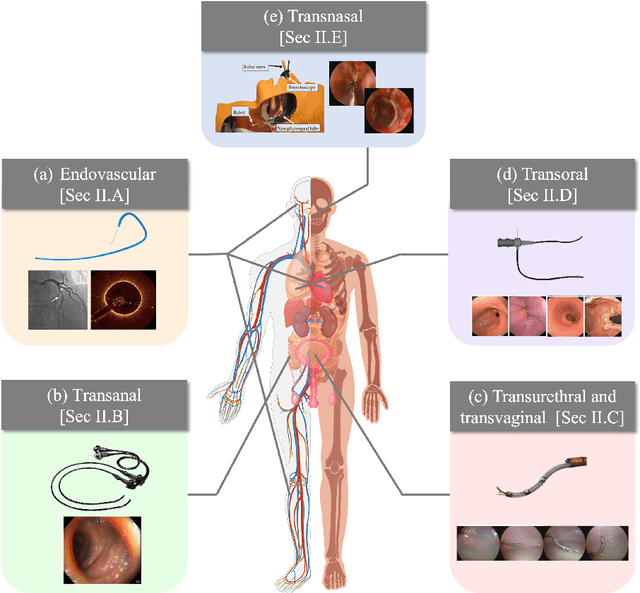
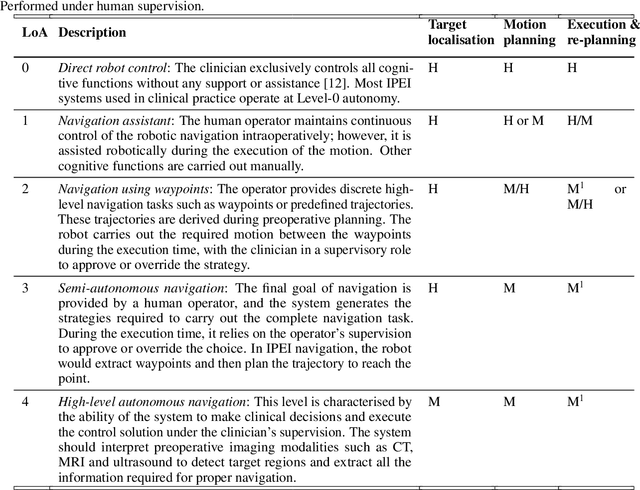
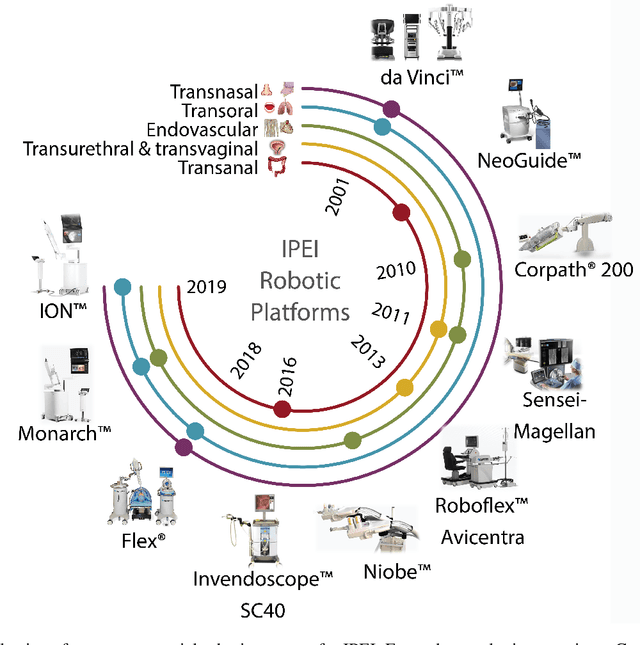

Increased demand for less invasive procedures has accelerated the adoption of Intraluminal Procedures (IP) and Endovascular Interventions (EI) performed through body lumens and vessels. As navigation through lumens and vessels is quite complex, interest grows to establish autonomous navigation techniques for IP and EI for reaching the target area. Current research efforts are directed toward increasing the Level of Autonomy (LoA) during the navigation phase. One key ingredient for autonomous navigation is Motion Planning (MP) techniques. This paper provides an overview of MP techniques categorizing them based on LoA. Our analysis investigates advances for the different clinical scenarios. Through a systematic literature analysis using the PRISMA method, the study summarizes relevant works and investigates the clinical aim, LoA, adopted MP techniques, and validation types. We identify the limitations of the corresponding MP methods and provide directions to improve the robustness of the algorithms in dynamic intraluminal environments. MP for IP and EI can be classified into four subgroups: node, sampling, optimization, and learning-based techniques, with a notable rise in learning-based approaches in recent years. One of the review's contributions is the identification of the limiting factors in IP and EI robotic systems hindering higher levels of autonomous navigation. In the future, navigation is bound to become more autonomous, placing the clinician in a supervisory position to improve control precision and reduce workload.
RL-Based Guidance in Outpatient Hysteroscopy Training: A Feasibility Study
Nov 26, 2022This work presents an RL-based agent for outpatient hysteroscopy training. Hysteroscopy is a gynecological procedure for examination of the uterine cavity. Recent advancements enabled performing this type of intervention in the outpatient setup without anaesthesia. While being beneficial to the patient, this approach introduces new challenges for clinicians, who should take additional measures to maintain the level of patient comfort and prevent tissue damage. Our prior work has presented a platform for hysteroscopic training with the focus on the passage of the cervical canal. With this work, we aim to extend the functionality of the platform by designing a subsystem that autonomously performs the task of the passage of the cervical canal. This feature can later be used as a virtual instructor to provide educational cues for trainees and assess their performance. The developed algorithm is based on the soft actor critic approach to smooth the learning curve of the agent and ensure uniform exploration of the workspace. The designed algorithm was tested against the performance of five clinicians. Overall, the algorithm demonstrated high efficiency and reliability, succeeding in 98% of trials and outperforming the expert group in three out of four measured metrics.
Autonomous Robotic Endoscope Control based on Semantically Rich Instructions
Jul 05, 2021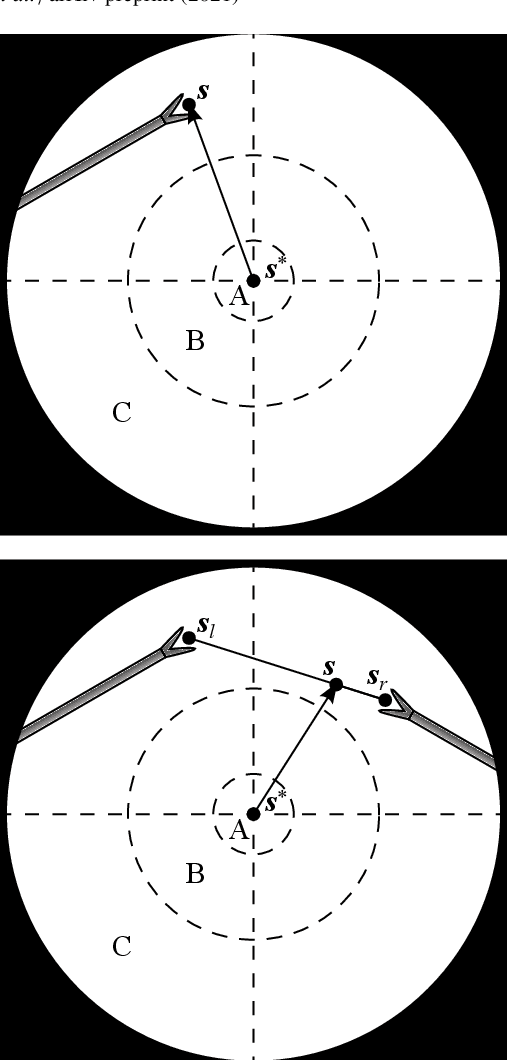
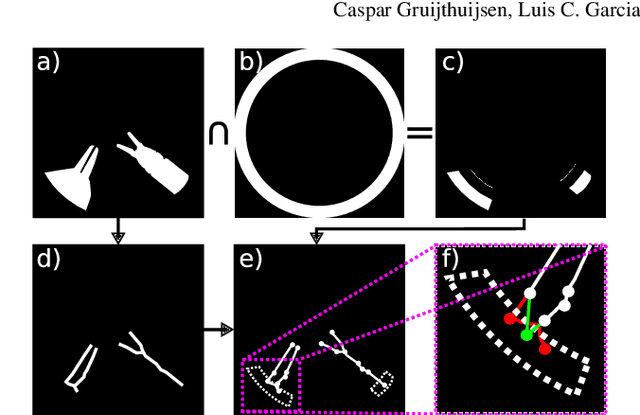
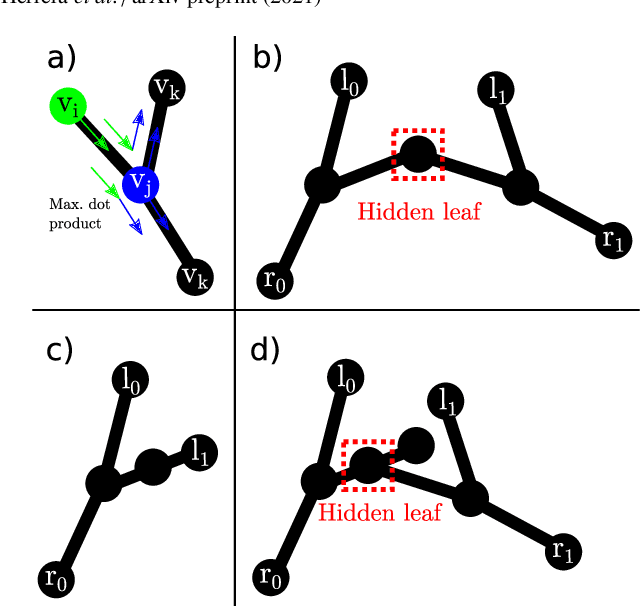
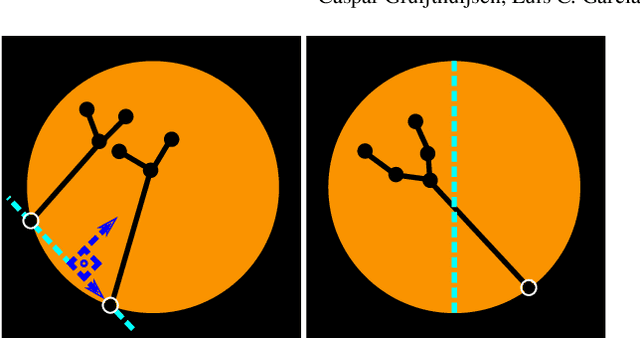
In keyhole interventions, surgeons rely on a colleague to act as a camera assistant when their hands are occupied with surgical instruments. This often leads to reduced image stability, increased task completion times and sometimes errors. Robotic endoscope holders (REHs), controlled by a set of basic instructions, have been proposed as an alternative, but their unnatural handling increases the cognitive load of the surgeon, hindering their widespread clinical acceptance. We propose that REHs collaborate with the operating surgeon via semantically rich instructions that closely resemble those issued to a human camera assistant, such as "focus on my right-hand instrument". As a proof-of-concept, we present a novel system that paves the way towards a synergistic interaction between surgeons and REHs. The proposed platform allows the surgeon to perform a bi-manual coordination and navigation task, while a robotic arm autonomously performs various endoscope positioning tasks. Within our system, we propose a novel tooltip localization method based on surgical tool segmentation, and a novel visual servoing approach that ensures smooth and correct motion of the endoscope camera. We validate our vision pipeline and run a user study of this system. Through successful application in a medically proven bi-manual coordination and navigation task, the framework has shown to be a promising starting point towards broader clinical adoption of REHs.
Real-Time Segmentation of Non-Rigid Surgical Tools based on Deep Learning and Tracking
Sep 07, 2020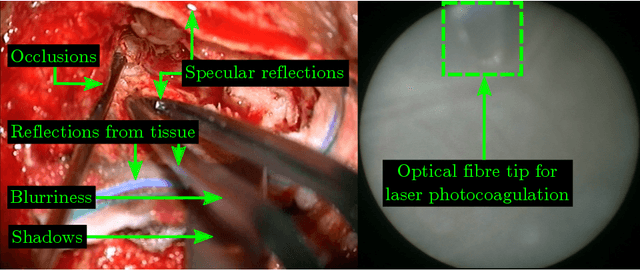

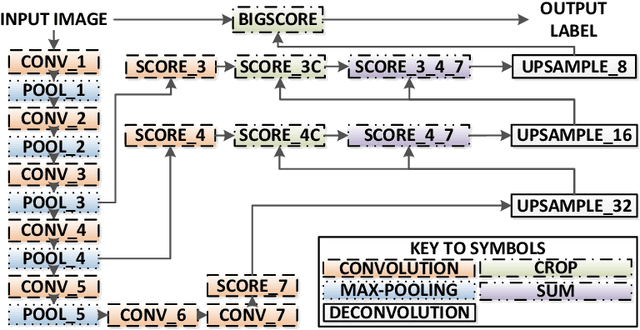
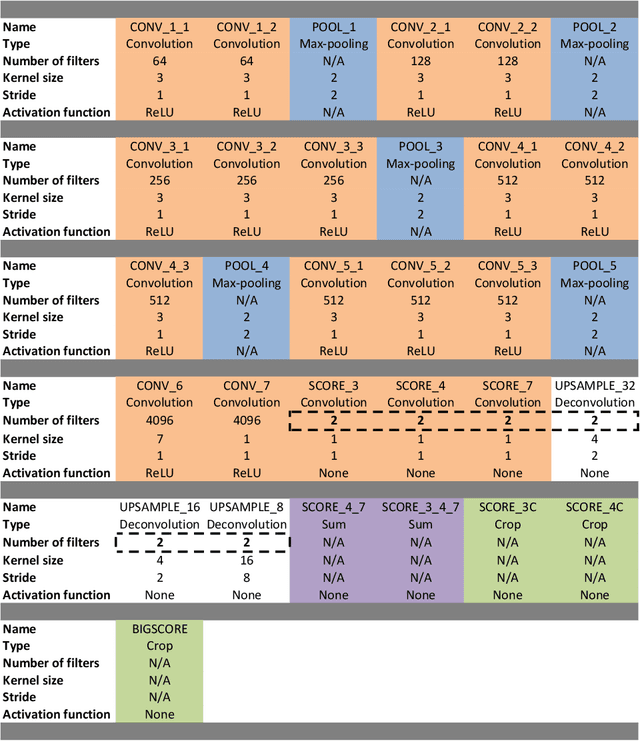
Real-time tool segmentation is an essential component in computer-assisted surgical systems. We propose a novel real-time automatic method based on Fully Convolutional Networks (FCN) and optical flow tracking. Our method exploits the ability of deep neural networks to produce accurate segmentations of highly deformable parts along with the high speed of optical flow. Furthermore, the pre-trained FCN can be fine-tuned on a small amount of medical images without the need to hand-craft features. We validated our method using existing and new benchmark datasets, covering both ex vivo and in vivo real clinical cases where different surgical instruments are employed. Two versions of the method are presented, non-real-time and real-time. The former, using only deep learning, achieves a balanced accuracy of 89.6% on a real clinical dataset, outperforming the (non-real-time) state of the art by 3.8% points. The latter, a combination of deep learning with optical flow tracking, yields an average balanced accuracy of 78.2% across all the validated datasets.
Deep Placental Vessel Segmentation for Fetoscopic Mosaicking
Jul 08, 2020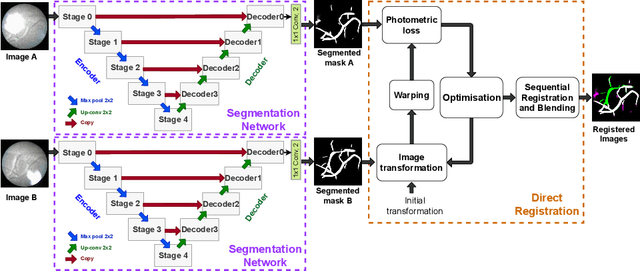
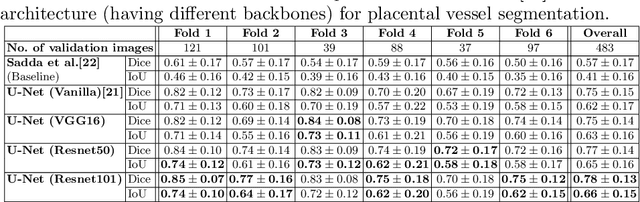
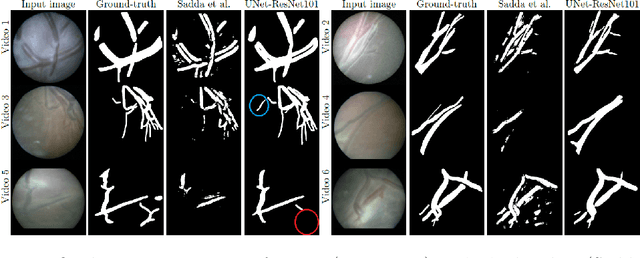
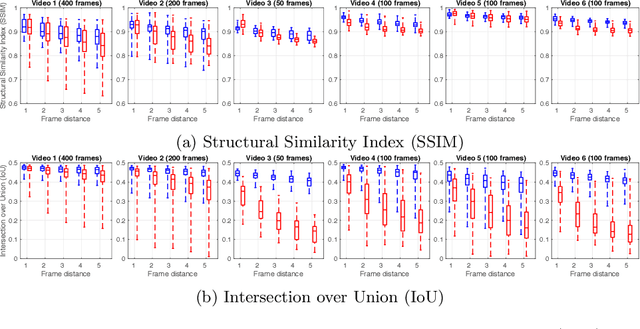
During fetoscopic laser photocoagulation, a treatment for twin-to-twin transfusion syndrome (TTTS), the clinician first identifies abnormal placental vascular connections and laser ablates them to regulate blood flow in both fetuses. The procedure is challenging due to the mobility of the environment, poor visibility in amniotic fluid, occasional bleeding, and limitations in the fetoscopic field-of-view and image quality. Ideally, anastomotic placental vessels would be automatically identified, segmented and registered to create expanded vessel maps to guide laser ablation, however, such methods have yet to be clinically adopted. We propose a solution utilising the U-Net architecture for performing placental vessel segmentation in fetoscopic videos. The obtained vessel probability maps provide sufficient cues for mosaicking alignment by registering consecutive vessel maps using the direct intensity-based technique. Experiments on 6 different in vivo fetoscopic videos demonstrate that the vessel intensity-based registration outperformed image intensity-based registration approaches showing better robustness in qualitative and quantitative comparison. We additionally reduce drift accumulation to negligible even for sequences with up to 400 frames and we incorporate a scheme for quantifying drift error in the absence of the ground-truth. Our paper provides a benchmark for fetoscopy placental vessel segmentation and registration by contributing the first in vivo vessel segmentation and fetoscopic videos dataset.
Deep Sequential Mosaicking of Fetoscopic Videos
Jul 15, 2019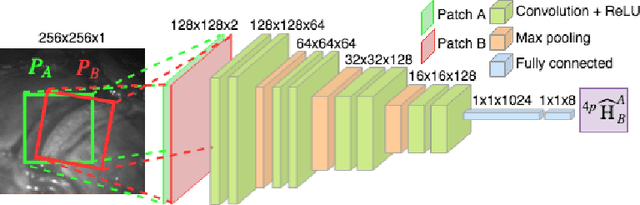
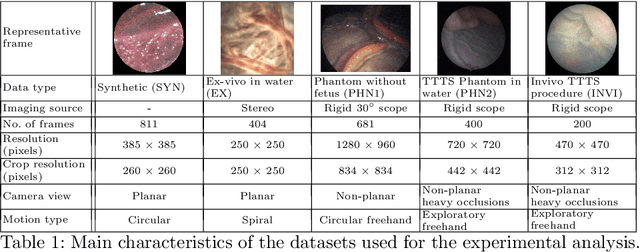
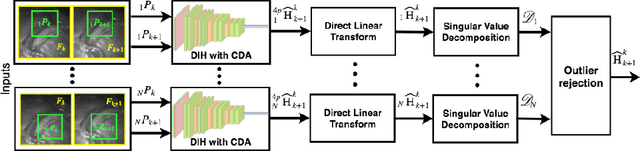

Twin-to-twin transfusion syndrome treatment requires fetoscopic laser photocoagulation of placental vascular anastomoses to regulate blood flow to both fetuses. Limited field-of-view (FoV) and low visual quality during fetoscopy make it challenging to identify all vascular connections. Mosaicking can align multiple overlapping images to generate an image with increased FoV, however, existing techniques apply poorly to fetoscopy due to the low visual quality, texture paucity, and hence fail in longer sequences due to the drift accumulated over time. Deep learning techniques can facilitate in overcoming these challenges. Therefore, we present a new generalized Deep Sequential Mosaicking (DSM) framework for fetoscopic videos captured from different settings such as simulation, phantom, and real environments. DSM extends an existing deep image-based homography model to sequential data by proposing controlled data augmentation and outlier rejection methods. Unlike existing methods, DSM can handle visual variations due to specular highlights and reflection across adjacent frames, hence reducing the accumulated drift. We perform experimental validation and comparison using 5 diverse fetoscopic videos to demonstrate the robustness of our framework.
Automatic Tool Landmark Detection for Stereo Vision in Robot-Assisted Retinal Surgery
Nov 20, 2017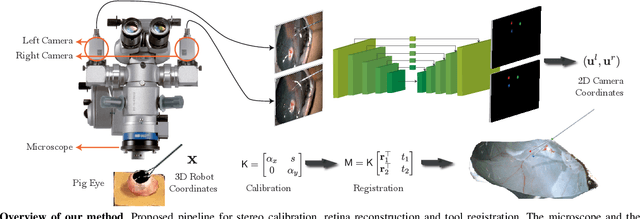
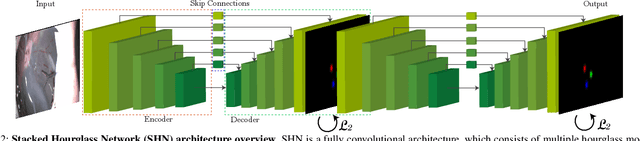
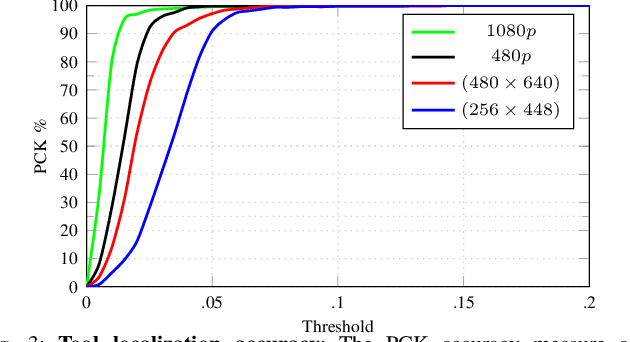
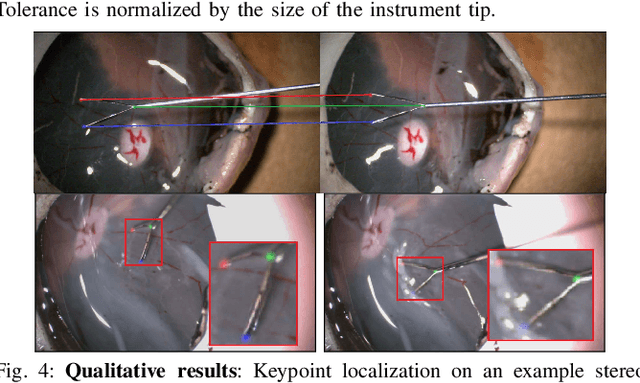
Computer vision and robotics are being increasingly applied in medical interventions. Especially in interventions where extreme precision is required they could make a difference. One such application is robot-assisted retinal microsurgery. In recent works, such interventions are conducted under a stereo-microscope, and with a robot-controlled surgical tool. The complementarity of computer vision and robotics has however not yet been fully exploited. In order to improve the robot control we are interested in 3D reconstruction of the anatomy and in automatic tool localization using a stereo microscope. In this paper, we solve this problem for the first time using a single pipeline, starting from uncalibrated cameras to reach metric 3D reconstruction and registration, in retinal microsurgery. The key ingredients of our method are: (a) surgical tool landmark detection, and (b) 3D reconstruction with the stereo microscope, using the detected landmarks. To address the former, we propose a novel deep learning method that detects and recognizes keypoints in high definition images at higher than real-time speed. We use the detected 2D keypoints along with their corresponding 3D coordinates obtained from the robot sensors to calibrate the stereo microscope using an affine projection model. We design an online 3D reconstruction pipeline that makes use of smoothness constraints and performs robot-to-camera registration. The entire pipeline is extensively validated on open-sky porcine eye sequences. Quantitative and qualitative results are presented for all steps.
ToolNet: Holistically-Nested Real-Time Segmentation of Robotic Surgical Tools
Jul 04, 2017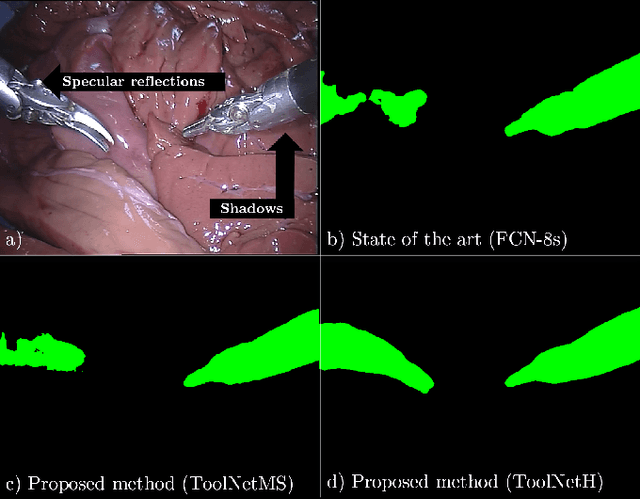
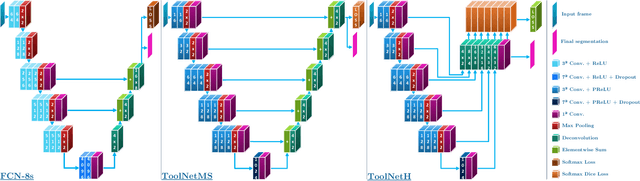
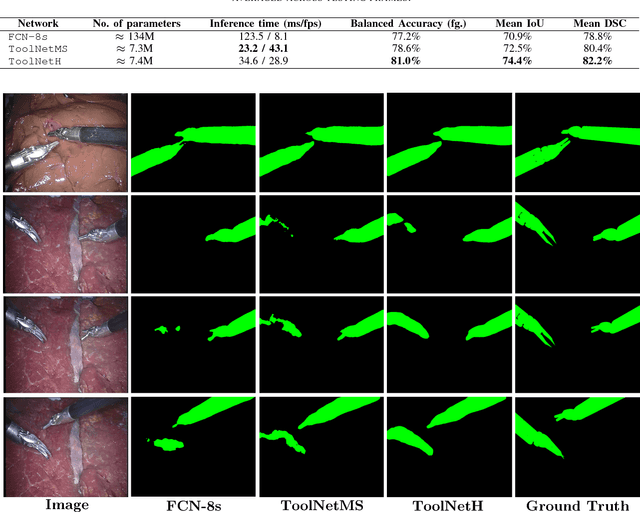
Real-time tool segmentation from endoscopic videos is an essential part of many computer-assisted robotic surgical systems and of critical importance in robotic surgical data science. We propose two novel deep learning architectures for automatic segmentation of non-rigid surgical instruments. Both methods take advantage of automated deep-learning-based multi-scale feature extraction while trying to maintain an accurate segmentation quality at all resolutions. The two proposed methods encode the multi-scale constraint inside the network architecture. The first proposed architecture enforces it by cascaded aggregation of predictions and the second proposed network does it by means of a holistically-nested architecture where the loss at each scale is taken into account for the optimization process. As the proposed methods are for real-time semantic labeling, both present a reduced number of parameters. We propose the use of parametric rectified linear units for semantic labeling in these small architectures to increase the regularization ability of the design and maintain the segmentation accuracy without overfitting the training sets. We compare the proposed architectures against state-of-the-art fully convolutional networks. We validate our methods using existing benchmark datasets, including ex vivo cases with phantom tissue and different robotic surgical instruments present in the scene. Our results show a statistically significant improved Dice Similarity Coefficient over previous instrument segmentation methods. We analyze our design choices and discuss the key drivers for improving accuracy.