 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive Learning of Robot Task Knowledge from Raw Data and Online Expert Feedback
Jan 13, 2025The increasing level of autonomy of robots poses challenges of trust and social acceptance, especially in human-robot interaction scenarios. This requires an interpretable implementation of robotic cognitive capabilities, possibly based on formal methods as logics for the definition of task specifications. However, prior knowledge is often unavailable in complex realistic scenarios. In this paper, we propose an offline algorithm based on inductive logic programming from noisy examples to extract task specifications (i.e., action preconditions, constraints and effects) directly from raw data of few heterogeneous (i.e., not repetitive) robotic executions. Our algorithm leverages on the output of any unsupervised action identification algorithm from video-kinematic recordings. Combining it with the definition of very basic, almost task-agnostic, commonsense concepts about the environment, which contribute to the interpretability of our methodology, we are able to learn logical axioms encoding preconditions of actions, as well as their effects in the event calculus paradigm. Since the quality of learned specifications depends mainly on the accuracy of the action identification algorithm, we also propose an online framework for incremental refinement of task knowledge from user feedback, guaranteeing safe execution. Results in a standard manipulation task and benchmark for user training in the safety-critical surgical robotic scenario, show the robustness, data- and time-efficiency of our methodology, with promising results towards the scalability in more complex domains.
Sim-To-Real Transfer for Visual Reinforcement Learning of Deformable Object Manipulation for Robot-Assisted Surgery
Jun 10, 2024Automation holds the potential to assist surgeons in robotic interventions, shifting their mental work load from visuomotor control to high level decision making. Reinforcement learning has shown promising results in learning complex visuomotor policies, especially in simulation environments where many samples can be collected at low cost. A core challenge is learning policies in simulation that can be deployed in the real world, thereby overcoming the sim-to-real gap. In this work, we bridge the visual sim-to-real gap with an image-based reinforcement learning pipeline based on pixel-level domain adaptation and demonstrate its effectiveness on an image-based task in deformable object manipulation. We choose a tissue retraction task because of its importance in clinical reality of precise cancer surgery. After training in simulation on domain-translated images, our policy requires no retraining to perform tissue retraction with a 50% success rate on the real robotic system using raw RGB images. Furthermore, our sim-to-real transfer method makes no assumptions on the task itself and requires no paired images. This work introduces the first successful application of visual sim-to-real transfer for robotic manipulation of deformable objects in the surgical field, which represents a notable step towards the clinical translation of cognitive surgical robotics.
Do LLMs Dream of Ontologies?
Jan 26, 2024
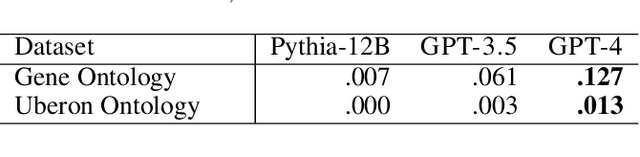
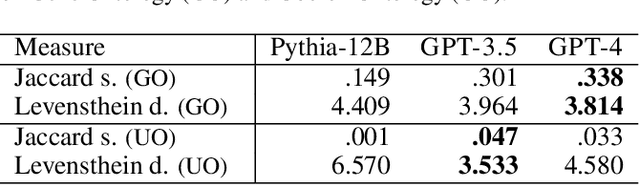

Large language models (LLMs) have recently revolutionized automated text understanding and generation. The performance of these models relies on the high number of parameters of the underlying neural architectures, which allows LLMs to memorize part of the vast quantity of data seen during the training. This paper investigates whether and to what extent general-purpose pre-trained LLMs have memorized information from known ontologies. Our results show that LLMs partially know ontologies: they can, and do indeed, memorize concepts from ontologies mentioned in the text, but the level of memorization of their concepts seems to vary proportionally to their popularity on the Web, the primary source of their training material. We additionally propose new metrics to estimate the degree of memorization of ontological information in LLMs by measuring the consistency of the output produced across different prompt repetitions, query languages, and degrees of determinism.
Challenges in Multi-centric Generalization: Phase and Step Recognition in Roux-en-Y Gastric Bypass Surgery
Dec 18, 2023Most studies on surgical activity recognition utilizing Artificial intelligence (AI) have focused mainly on recognizing one type of activity from small and mono-centric surgical video datasets. It remains speculative whether those models would generalize to other centers. In this work, we introduce a large multi-centric multi-activity dataset consisting of 140 videos (MultiBypass140) of laparoscopic Roux-en-Y gastric bypass (LRYGB) surgeries performed at two medical centers: the University Hospital of Strasbourg (StrasBypass70) and Inselspital, Bern University Hospital (BernBypass70). The dataset has been fully annotated with phases and steps. Furthermore, we assess the generalizability and benchmark different deep learning models in 7 experimental studies: 1) Training and evaluation on BernBypass70; 2) Training and evaluation on StrasBypass70; 3) Training and evaluation on the MultiBypass140; 4) Training on BernBypass70, evaluation on StrasBypass70; 5) Training on StrasBypass70, evaluation on BernBypass70; Training on MultiBypass140, evaluation 6) on BernBypass70 and 7) on StrasBypass70. The model's performance is markedly influenced by the training data. The worst results were obtained in experiments 4) and 5) confirming the limited generalization capabilities of models trained on mono-centric data. The use of multi-centric training data, experiments 6) and 7), improves the generalization capabilities of the models, bringing them beyond the level of independent mono-centric training and validation (experiments 1) and 2)). MultiBypass140 shows considerable variation in surgical technique and workflow of LRYGB procedures between centers. Therefore, generalization experiments demonstrate a remarkable difference in model performance. These results highlight the importance of multi-centric datasets for AI model generalization to account for variance in surgical technique and workflows.
Autonomous Navigation for Robot-assisted Intraluminal and Endovascular Procedures: A Systematic Review
May 06, 2023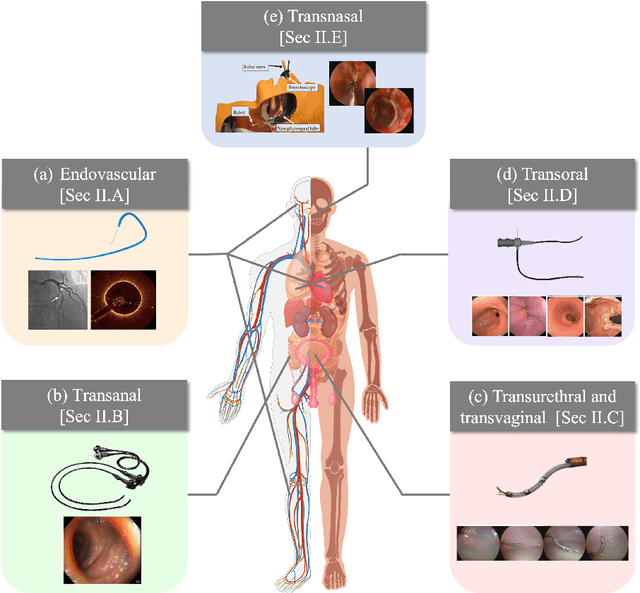
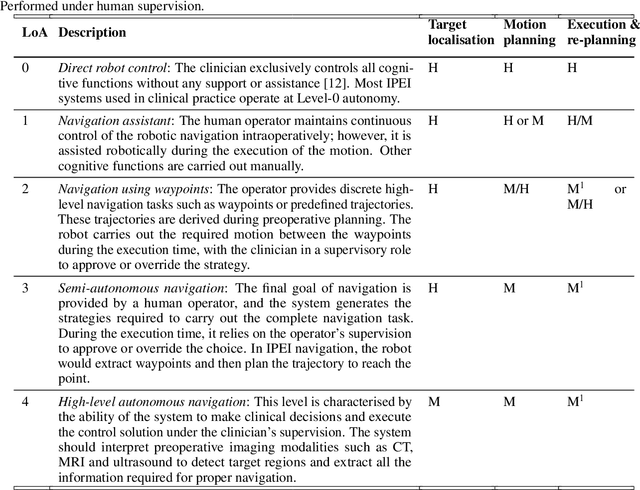
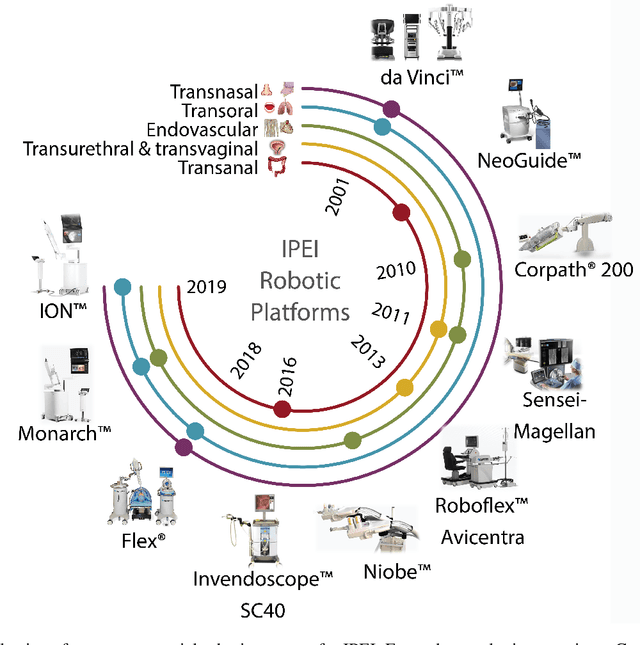

Increased demand for less invasive procedures has accelerated the adoption of Intraluminal Procedures (IP) and Endovascular Interventions (EI) performed through body lumens and vessels. As navigation through lumens and vessels is quite complex, interest grows to establish autonomous navigation techniques for IP and EI for reaching the target area. Current research efforts are directed toward increasing the Level of Autonomy (LoA) during the navigation phase. One key ingredient for autonomous navigation is Motion Planning (MP) techniques. This paper provides an overview of MP techniques categorizing them based on LoA. Our analysis investigates advances for the different clinical scenarios. Through a systematic literature analysis using the PRISMA method, the study summarizes relevant works and investigates the clinical aim, LoA, adopted MP techniques, and validation types. We identify the limitations of the corresponding MP methods and provide directions to improve the robustness of the algorithms in dynamic intraluminal environments. MP for IP and EI can be classified into four subgroups: node, sampling, optimization, and learning-based techniques, with a notable rise in learning-based approaches in recent years. One of the review's contributions is the identification of the limiting factors in IP and EI robotic systems hindering higher levels of autonomous navigation. In the future, navigation is bound to become more autonomous, placing the clinician in a supervisory position to improve control precision and reduce workload.
Constrained Reinforcement Learning and Formal Verification for Safe Colonoscopy Navigation
Mar 16, 2023



The field of robotic Flexible Endoscopes (FEs) has progressed significantly, offering a promising solution to reduce patient discomfort. However, the limited autonomy of most robotic FEs results in non-intuitive and challenging manoeuvres, constraining their application in clinical settings. While previous studies have employed lumen tracking for autonomous navigation, they fail to adapt to the presence of obstructions and sharp turns when the endoscope faces the colon wall. In this work, we propose a Deep Reinforcement Learning (DRL)-based navigation strategy that eliminates the need for lumen tracking. However, the use of DRL methods poses safety risks as they do not account for potential hazards associated with the actions taken. To ensure safety, we exploit a Constrained Reinforcement Learning (CRL) method to restrict the policy in a predefined safety regime. Moreover, we present a model selection strategy that utilises Formal Verification (FV) to choose a policy that is entirely safe before deployment. We validate our approach in a virtual colonoscopy environment and report that out of the 300 trained policies, we could identify three policies that are entirely safe. Our work demonstrates that CRL, combined with model selection through FV, can improve the robustness and safety of robotic behaviour in surgical applications.
Generalization of Auto-Regressive Hidden Markov Models to Non-Linear Dynamics and Non-Euclidean Observation Space
Feb 23, 2023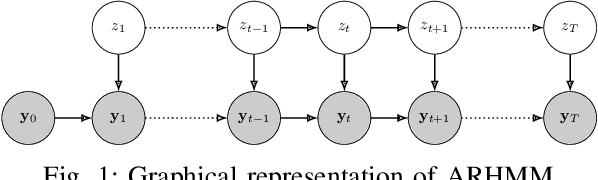
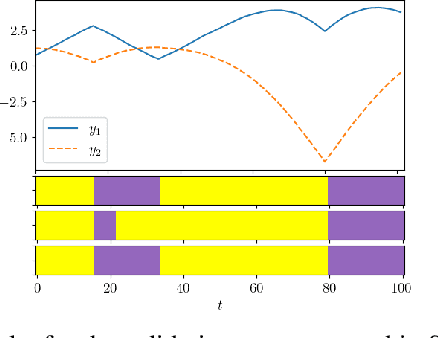
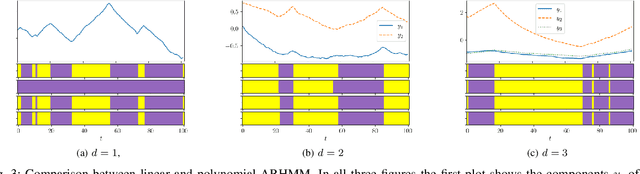
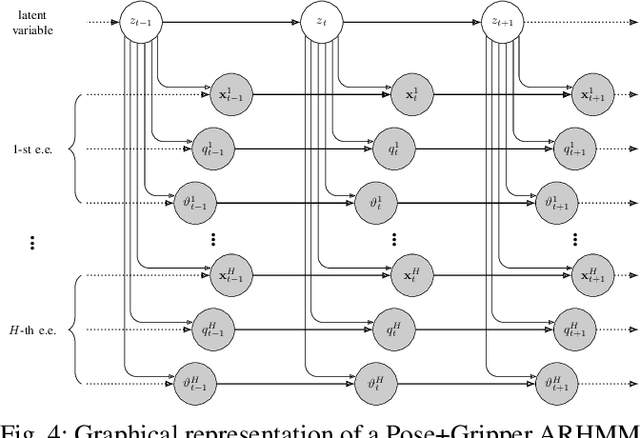
Latent variable models are widely used to perform unsupervised segmentation of time series in different context such as robotics, speech recognition, and economics. One of the most widely used latent variable model is the Auto-Regressive Hidden Markov Model (ARHMM), which combines a latent mode governed by a Markov chain dynamics with a linear Auto-Regressive dynamics of the observed state. In this work, we propose two generalizations of the ARHMM. First, we propose a more general AR dynamics in Cartesian space, described as a linear combination of non-linear basis functions. Second, we propose a linear dynamics in unit quaternion space, in order to properly describe orientations. These extensions allow to describe more complex dynamics of the observed state. Although this extension is proposed for the ARHMM, it can be easily extended to other latent variable models with AR dynamics in the observed space, such as Auto-Regressive Hidden semi-Markov Models.
Weakly Supervised Temporal Convolutional Networks for Fine-grained Surgical Activity Recognition
Feb 21, 2023



Automatic recognition of fine-grained surgical activities, called steps, is a challenging but crucial task for intelligent intra-operative computer assistance. The development of current vision-based activity recognition methods relies heavily on a high volume of manually annotated data. This data is difficult and time-consuming to generate and requires domain-specific knowledge. In this work, we propose to use coarser and easier-to-annotate activity labels, namely phases, as weak supervision to learn step recognition with fewer step annotated videos. We introduce a step-phase dependency loss to exploit the weak supervision signal. We then employ a Single-Stage Temporal Convolutional Network (SS-TCN) with a ResNet-50 backbone, trained in an end-to-end fashion from weakly annotated videos, for temporal activity segmentation and recognition. We extensively evaluate and show the effectiveness of the proposed method on a large video dataset consisting of 40 laparoscopic gastric bypass procedures and the public benchmark CATARACTS containing 50 cataract surgeries.
Logic programming for deliberative robotic task planning
Jan 18, 2023Over the last decade, the use of robots in production and daily life has increased. With increasingly complex tasks and interaction in different environments including humans, robots are required a higher level of autonomy for efficient deliberation. Task planning is a key element of deliberation. It combines elementary operations into a structured plan to satisfy a prescribed goal, given specifications on the robot and the environment. In this manuscript, we present a survey on recent advances in the application of logic programming to the problem of task planning. Logic programming offers several advantages compared to other approaches, including greater expressivity and interpretability which may aid in the development of safe and reliable robots. We analyze different planners and their suitability for specific robotic applications, based on expressivity in domain representation, computational efficiency and software implementation. In this way, we support the robotic designer in choosing the best tool for his application.
CIPCaD-Bench: Continuous Industrial Process datasets for benchmarking Causal Discovery methods
Aug 02, 2022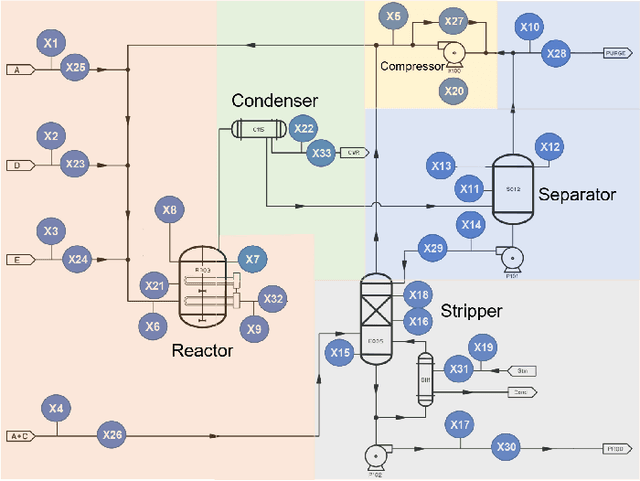
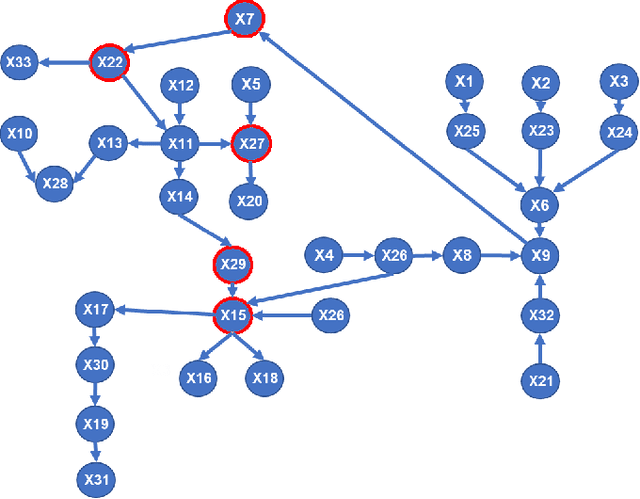
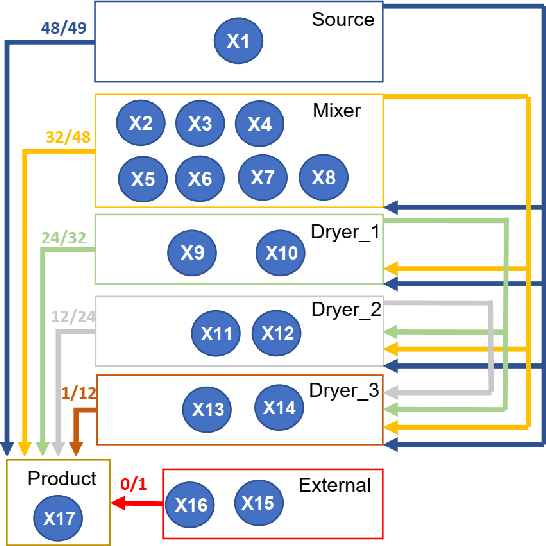
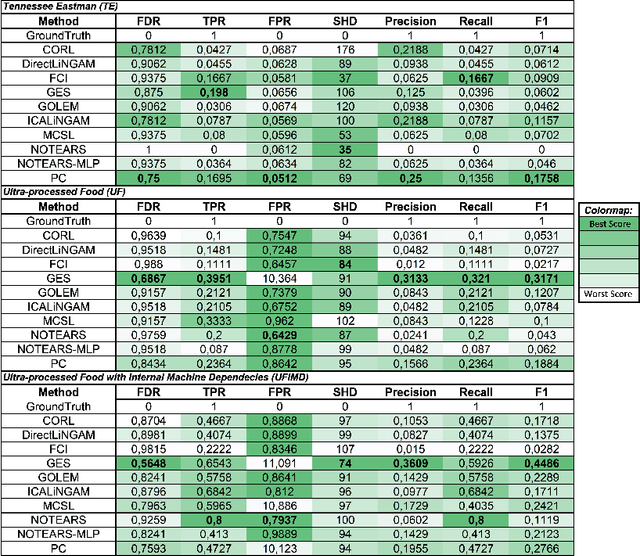
Causal relationships are commonly examined in manufacturing processes to support faults investigations, perform interventions, and make strategic decisions. Industry 4.0 has made available an increasing amount of data that enable data-driven Causal Discovery (CD). Considering the growing number of recently proposed CD methods, it is necessary to introduce strict benchmarking procedures on publicly available datasets since they represent the foundation for a fair comparison and validation of different methods. This work introduces two novel public datasets for CD in continuous manufacturing processes. The first dataset employs the well-known Tennessee Eastman simulator for fault detection and process control. The second dataset is extracted from an ultra-processed food manufacturing plant, and it includes a description of the plant, as well as multiple ground truths. These datasets are used to propose a benchmarking procedure based on different metrics and evaluated on a wide selection of CD algorithms. This work allows testing CD methods in realistic conditions enabling the selection of the most suitable method for specific target applications. The datasets are available at the following link: https://github.com/giovanniMen