 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEN-Guard: Correcting Generalization Failures for Deployable Federated Surgical AI
Jun 18, 2026Federated Learning (FL) in surgical video AI enables collaborative model training without sharing sensitive data. However, standard evaluation practices - selecting the "best" global model based only on validation data from participating hospitals - can lead to suboptimal deployment choices. We identify this critical failure mode as performance leakage, where the selected model overfits internal federation data and fails to generalize to unseen institutions. We propose GEN-Guard, a practical post-hoc framework to detect and correct generalization failures in federated surgical AI. It integrates Generalization Detection via Client-Blocked Evaluation (CBE), which validates performance on isolated client distributions to prevent performance leakage, and Generalization Correction through Disagreement-Aware Distillation (DAD), which learns adaptive feature-level corrections for cross-institutional robustness. Both components operate after standard FL convergence while providing robust support for zero-shot adaptation to unseen environments. We first quantify the severity of performance leakage, observing Model Selection Failures (MSFs) exceeding 80% under standard evaluation. GEN-Guard is evaluated on two multi-center clinical challenges: surgical phase recognition in laparoscopic cholecystectomy and polyp segmentation in colonoscopy. Across both datasets, GEN-Guard consistently corrects these failures, improving in-federation F1 scores by up to 2 points, unseen-institution performance by up to 3 points, and worst-case institutional performance by 3-9 points. Performance leakage represents a systematic and previously under-recognized risk in federated surgical AI. GEN-Guard provides a practical solution for detecting and correcting such failures. By improving cross-institutional robustness and zero-shot generalization, it strengthens the reliability of FL for real-world surgical deployment.
SurgTEMP: Temporal-Aware Surgical Video Question Answering with Text-guided Visual Memory for Laparoscopic Cholecystectomy
Apr 01, 2026Surgical procedures are inherently complex and risky, requiring extensive expertise and constant focus to well navigate evolving intraoperative scenes. Computer-assisted systems such as surgical visual question answering (VQA) offer promises for education and intraoperative support. Current surgical VQA research largely focuses on static frame analysis, overlooking rich temporal semantics. Surgical video question answering is further challenged by low visual contrast, its highly knowledge-driven nature, diverse analytical needs spanning scattered temporal windows, and the hierarchy from basic perception to high-level intraoperative assessment. To address these challenges, we propose SurgTEMP, a multimodal LLM framework featuring (i) a query-guided token selection module that builds hierarchical visual memory (spatial and temporal memory banks) and (ii) a Surgical Competency Progression (SCP) training scheme. Together, these components enable effective modeling of variable-length surgical videos while preserving procedure-relevant cues and temporal coherence, and better support diverse downstream assessment tasks. To support model development, we introduce CholeVidQA-32K, a surgical video question answering dataset comprising 32K open-ended QA pairs and 3,855 video segments (approximately 128 h total) from laparoscopic cholecystectomy. The dataset is organized into a three-level hierarchy -- Perception, Assessment, and Reasoning -- spanning 11 tasks from instrument/action/anatomy perception to Critical View of Safety (CVS), intraoperative difficulty, skill proficiency, and adverse event assessment. In comprehensive evaluations against state-of-the-art open-source multimodal and video LLMs (fine-tuned and zero-shot), SurgTEMP achieves substantial performance improvements, advancing the state of video-based surgical VQA.
Artificial Intelligence for the Assessment of Peritoneal Carcinosis during Diagnostic Laparoscopy for Advanced Ovarian Cancer
Dec 16, 2025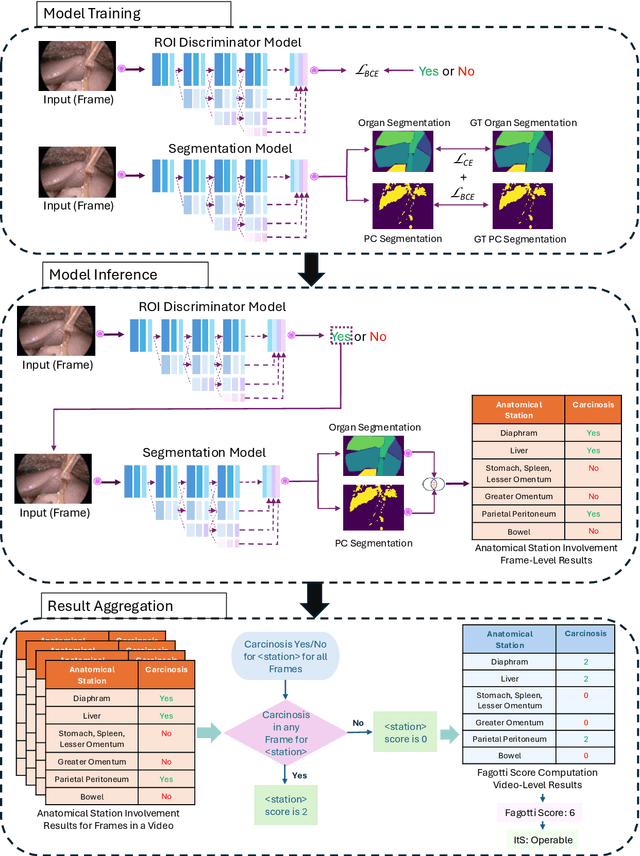
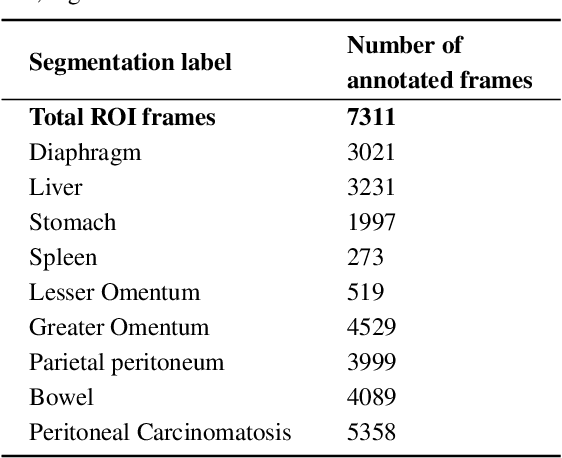


Advanced Ovarian Cancer (AOC) is often diagnosed at an advanced stage with peritoneal carcinosis (PC). Fagotti score (FS) assessment at diagnostic laparoscopy (DL) guides treatment planning by estimating surgical resectability, but its subjective and operator-dependent nature limits reproducibility and widespread use. Videos of patients undergoing DL with concomitant FS assessments at a referral center were retrospectively collected and divided into a development dataset, for data annotation, AI training and evaluation, and an independent test dataset, for internal validation. In the development dataset, FS-relevant frames were manually annotated for anatomical structures and PC. Deep learning models were trained to automatically identify FS-relevant frames, segment structures and PC, and predict video-level FS and indication to surgery (ItS). AI performance was evaluated using Dice score for segmentation, F1-scores for anatomical stations (AS) and ItS prediction, and root mean square error (RMSE) for final FS estimation. In the development dataset, the segmentation model trained on 7,311 frames, achieved Dice scores of 70$\pm$3% for anatomical structures and 56$\pm$3% for PC. Video-level AS classification achieved F1-scores of 74$\pm$3% and 73$\pm$4%, FS prediction showed normalized RMSE values of 1.39$\pm$0.18 and 1.15$\pm$0.08, and ItS reached F1-scores of 80$\pm$8% and 80$\pm$2% in the development (n=101) and independent test datasets (n=50), respectively. This is the first AI model to predict the feasibility of cytoreductive surgery providing automated FS estimation from DL videos. Its reproducible and reliable performance across datasets suggests that AI can support surgeons through standardized intraoperative tumor burden assessment and clinical decision-making in AOC.
Expert Consensus-based Video-Based Assessment Tool for Workflow Analysis in Minimally Invasive Colorectal Surgery: Development and Validation of ColoWorkflow
Nov 13, 2025



Minimally invasive colorectal surgery is characterized by procedural variability, a difficult learning curve, and complications that impact quality and outcomes. Video-based assessment (VBA) offers an opportunity to generate data-driven insights to reduce variability, optimize training, and improve surgical performance. However, existing tools for workflow analysis remain difficult to standardize and implement. This study aims to develop and validate a VBA tool for workflow analysis across minimally invasive colorectal procedures. A Delphi process was conducted to achieve consensus on generalizable workflow descriptors. The resulting framework informed the development of a new VBA tool, ColoWorkflow. Independent raters then applied ColoWorkflow to a multicentre video dataset of laparoscopic and robotic colorectal surgery (CRS). Applicability and inter-rater reliability were evaluated. Consensus was achieved for 10 procedure-agnostic phases and 34 procedure-specific steps describing CRS workflows. ColoWorkflow was developed and applied to 54 colorectal operative videos (left and right hemicolectomies, sigmoid and rectosigmoid resections, and total proctocolectomies) from five centres. The tool demonstrated broad applicability, with all but one label utilized. Inter-rater reliability was moderate, with mean Cohen's K of 0.71 for phases and 0.66 for steps. Most discrepancies arose at phase transitions and step boundary definitions. ColoWorkflow is the first consensus-based, validated VBA tool for comprehensive workflow analysis in minimally invasive CRS. It establishes a reproducible framework for video-based performance assessment, enabling benchmarking across institutions and supporting the development of artificial intelligence-driven workflow recognition. Its adoption may standardize training, accelerate competency acquisition, and advance data-informed surgical quality improvement.
Learning from Sparse Point Labels for Dense Carcinosis Localization in Advanced Ovarian Cancer Assessment
Jul 09, 2025Learning from sparse labels is a challenge commonplace in the medical domain. This is due to numerous factors, such as annotation cost, and is especially true for newly introduced tasks. When dense pixel-level annotations are needed, this becomes even more unfeasible. However, being able to learn from just a few annotations at the pixel-level, while extremely difficult and underutilized, can drive progress in studies where perfect annotations are not immediately available. This work tackles the challenge of learning the dense prediction task of keypoint localization from a few point annotations in the context of 2d carcinosis keypoint localization from laparoscopic video frames for diagnostic planning of advanced ovarian cancer patients. To enable this, we formulate the problem as a sparse heatmap regression from a few point annotations per image and propose a new loss function, called Crag and Tail loss, for efficient learning. Our proposed loss function effectively leverages positive sparse labels while minimizing the impact of false negatives or missed annotations. Through an extensive ablation study, we demonstrate the effectiveness of our approach in achieving accurate dense localization of carcinosis keypoints, highlighting its potential to advance research in scenarios where dense annotations are challenging to obtain.
Surgeons Awareness, Expectations, and Involvement with Artificial Intelligence: a Survey Pre and Post the GPT Era
Jun 09, 2025Artificial Intelligence (AI) is transforming medicine, with generative AI models like ChatGPT reshaping perceptions of its potential. This study examines surgeons' awareness, expectations, and involvement with AI in surgery through comparative surveys conducted in 2021 and 2024. Two cross-sectional surveys were distributed globally in 2021 and 2024, the first before an IRCAD webinar and the second during the annual EAES meeting. The surveys assessed demographics, AI awareness, expectations, involvement, and ethics (2024 only). The surveys collected a total of 671 responses from 98 countries, 522 in 2021 and 149 in 2024. Awareness of AI courses rose from 14.5% in 2021 to 44.6% in 2024, while course attendance increased from 12.9% to 23%. Despite this, familiarity with foundational AI concepts remained limited. Expectations for AI's role shifted in 2024, with hospital management gaining relevance. Ethical concerns gained prominence, with 87.2% of 2024 participants emphasizing accountability and transparency. Infrastructure limitations remained the primary obstacle to implementation. Interdisciplinary collaboration and structured training were identified as critical for successful AI adoption. Optimism about AI's transformative potential remained high, with 79.9% of respondents believing AI would positively impact surgery and 96.6% willing to integrate AI into their clinical practice. Surgeons' perceptions of AI are evolving, driven by the rise of generative AI and advancements in surgical data science. While enthusiasm for integration is strong, knowledge gaps and infrastructural challenges persist. Addressing these through education, ethical frameworks, and infrastructure development is essential.
Early Operative Difficulty Assessment in Laparoscopic Cholecystectomy via Snapshot-Centric Video Analysis
Feb 10, 2025Purpose: Laparoscopic cholecystectomy (LC) operative difficulty (LCOD) is highly variable and influences outcomes. Despite extensive LC studies in surgical workflow analysis, limited efforts explore LCOD using intraoperative video data. Early recog- nition of LCOD could allow prompt review by expert surgeons, enhance operating room (OR) planning, and improve surgical outcomes. Methods: We propose the clinical task of early LCOD assessment using limited video observations. We design SurgPrOD, a deep learning model to assess LCOD by analyzing features from global and local temporal resolutions (snapshots) of the observed LC video. Also, we propose a novel snapshot-centric attention (SCA) module, acting across snapshots, to enhance LCOD prediction. We introduce the CholeScore dataset, featuring video-level LCOD labels to validate our method. Results: We evaluate SurgPrOD on 3 LCOD assessment scales in the CholeScore dataset. On our new metric assessing early and stable correct predictions, SurgPrOD surpasses baselines by at least 0.22 points. SurgPrOD improves over baselines by at least 9 and 5 percentage points in F1 score and top1-accuracy, respectively, demonstrating its effectiveness in correct predictions. Conclusion: We propose a new task for early LCOD assessment and a novel model, SurgPrOD analyzing surgical video from global and local perspectives. Our results on the CholeScore dataset establishes a new benchmark to study LCOD using intraoperative video data.
Surgical Text-to-Image Generation
Jul 12, 2024



Acquiring surgical data for research and development is significantly hindered by high annotation costs and practical and ethical constraints. Utilizing synthetically generated images could offer a valuable alternative. In this work, we conduct an in-depth analysis on adapting text-to-image generative models for the surgical domain, leveraging the CholecT50 dataset, which provides surgical images annotated with surgical action triplets (instrument, verb, target). We investigate various language models and find T5 to offer more distinct features for differentiating surgical actions based on triplet-based textual inputs. Our analysis demonstrates strong alignment between long and triplet-based captions, supporting the use of triplet-based labels. We address the challenges in training text-to-image models on triplet-based captions without additional input signals by uncovering that triplet text embeddings are instrument-centric in the latent space and then, by designing an instrument-based class balancing technique to counteract the imbalance and skewness in the surgical data, improving training convergence. Extending Imagen, a diffusion-based generative model, we develop Surgical Imagen to generate photorealistic and activity-aligned surgical images from triplet-based textual prompts. We evaluate our model using diverse metrics, including human expert surveys and automated methods like FID and CLIP scores. We assess the model performance on key aspects: quality, alignment, reasoning, knowledge, and robustness, demonstrating the effectiveness of our approach in providing a realistic alternative to real data collection.
CycleSAM: One-Shot Surgical Scene Segmentation using Cycle-Consistent Feature Matching to Prompt SAM
Jul 09, 2024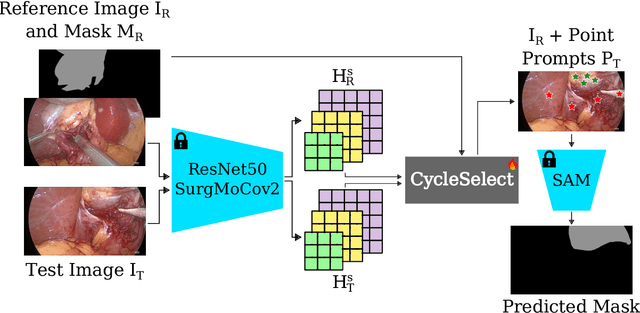
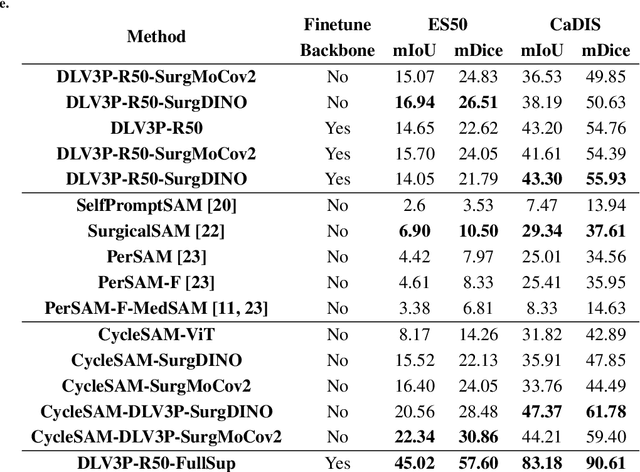

The recently introduced Segment-Anything Model (SAM) has the potential to greatly accelerate the development of segmentation models. However, directly applying SAM to surgical images has key limitations including (1) the requirement of image-specific prompts at test-time, thereby preventing fully automated segmentation, and (2) ineffectiveness due to substantial domain gap between natural and surgical images. In this work, we propose CycleSAM, an approach for one-shot surgical scene segmentation that uses the training image-mask pair at test-time to automatically identify points in the test images that correspond to each object class, which can then be used to prompt SAM to produce object masks. To produce high-fidelity matches, we introduce a novel spatial cycle-consistency constraint that enforces point proposals in the test image to rematch to points within the object foreground region in the training image. Then, to address the domain gap, rather than directly using the visual features from SAM, we employ a ResNet50 encoder pretrained on surgical images in a self-supervised fashion, thereby maintaining high label-efficiency. We evaluate CycleSAM for one-shot segmentation on two diverse surgical semantic segmentation datasets, comprehensively outperforming baseline approaches and reaching up to 50% of fully-supervised performance.
Optimizing Latent Graph Representations of Surgical Scenes for Zero-Shot Domain Transfer
Mar 11, 2024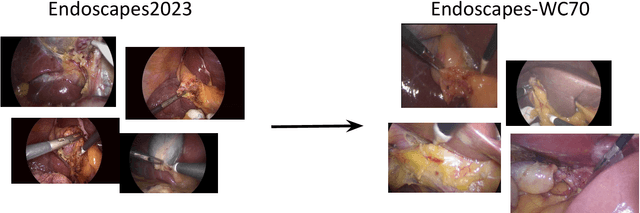
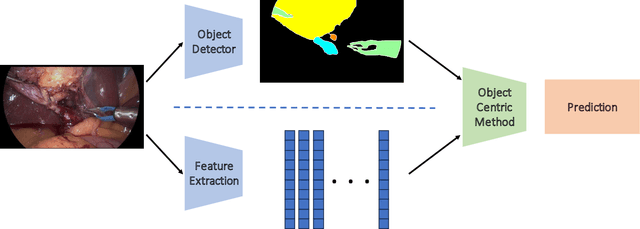

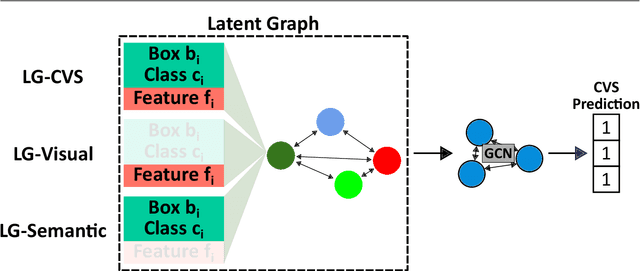
Purpose: Advances in deep learning have resulted in effective models for surgical video analysis; however, these models often fail to generalize across medical centers due to domain shift caused by variations in surgical workflow, camera setups, and patient demographics. Recently, object-centric learning has emerged as a promising approach for improved surgical scene understanding, capturing and disentangling visual and semantic properties of surgical tools and anatomy to improve downstream task performance. In this work, we conduct a multi-centric performance benchmark of object-centric approaches, focusing on Critical View of Safety assessment in laparoscopic cholecystectomy, then propose an improved approach for unseen domain generalization. Methods: We evaluate four object-centric approaches for domain generalization, establishing baseline performance. Next, leveraging the disentangled nature of object-centric representations, we dissect one of these methods through a series of ablations (e.g. ignoring either visual or semantic features for downstream classification). Finally, based on the results of these ablations, we develop an optimized method specifically tailored for domain generalization, LG-DG, that includes a novel disentanglement loss function. Results: Our optimized approach, LG-DG, achieves an improvement of 9.28% over the best baseline approach. More broadly, we show that object-centric approaches are highly effective for domain generalization thanks to their modular approach to representation learning. Conclusion: We investigate the use of object-centric methods for unseen domain generalization, identify method-agnostic factors critical for performance, and present an optimized approach that substantially outperforms existing methods.