 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJumpstarting Surgical Computer Vision
Dec 10, 2023



Purpose: General consensus amongst researchers and industry points to a lack of large, representative annotated datasets as the biggest obstacle to progress in the field of surgical data science. Self-supervised learning represents a solution to part of this problem, removing the reliance on annotations. However, the robustness of current self-supervised learning methods to domain shifts remains unclear, limiting our understanding of its utility for leveraging diverse sources of surgical data. Methods: In this work, we employ self-supervised learning to flexibly leverage diverse surgical datasets, thereby learning taskagnostic representations that can be used for various surgical downstream tasks. Based on this approach, to elucidate the impact of pre-training on downstream task performance, we explore 22 different pre-training dataset combinations by modulating three variables: source hospital, type of surgical procedure, and pre-training scale (number of videos). We then finetune the resulting model initializations on three diverse downstream tasks: namely, phase recognition and critical view of safety in laparoscopic cholecystectomy and phase recognition in laparoscopic hysterectomy. Results: Controlled experimentation highlights sizable boosts in performance across various tasks, datasets, and labeling budgets. However, this performance is intricately linked to the composition of the pre-training dataset, robustly proven through several study stages. Conclusion: The composition of pre-training datasets can severely affect the effectiveness of SSL methods for various downstream tasks and should critically inform future data collection efforts to scale the application of SSL methodologies. Keywords: Self-Supervised Learning, Transfer Learning, Surgical Computer Vision, Endoscopic Videos, Critical View of Safety, Phase Recognition
Preserving Privacy in Surgical Video Analysis Using Artificial Intelligence: A Deep Learning Classifier to Identify Out-of-Body Scenes in Endoscopic Videos
Jan 17, 2023Objective: To develop and validate a deep learning model for the identification of out-of-body images in endoscopic videos. Background: Surgical video analysis facilitates education and research. However, video recordings of endoscopic surgeries can contain privacy-sensitive information, especially if out-of-body scenes are recorded. Therefore, identification of out-of-body scenes in endoscopic videos is of major importance to preserve the privacy of patients and operating room staff. Methods: A deep learning model was trained and evaluated on an internal dataset of 12 different types of laparoscopic and robotic surgeries. External validation was performed on two independent multicentric test datasets of laparoscopic gastric bypass and cholecystectomy surgeries. All images extracted from the video datasets were annotated as inside or out-of-body. Model performance was evaluated compared to human ground truth annotations measuring the receiver operating characteristic area under the curve (ROC AUC). Results: The internal dataset consisting of 356,267 images from 48 videos and the two multicentric test datasets consisting of 54,385 and 58,349 images from 10 and 20 videos, respectively, were annotated. Compared to ground truth annotations, the model identified out-of-body images with 99.97% ROC AUC on the internal test dataset. Mean $\pm$ standard deviation ROC AUC on the multicentric gastric bypass dataset was 99.94$\pm$0.07% and 99.71$\pm$0.40% on the multicentric cholecystectomy dataset, respectively. Conclusion: The proposed deep learning model can reliably identify out-of-body images in endoscopic videos. The trained model is publicly shared. This facilitates privacy preservation in surgical video analysis.
Federated Cycling (FedCy): Semi-supervised Federated Learning of Surgical Phases
Mar 14, 2022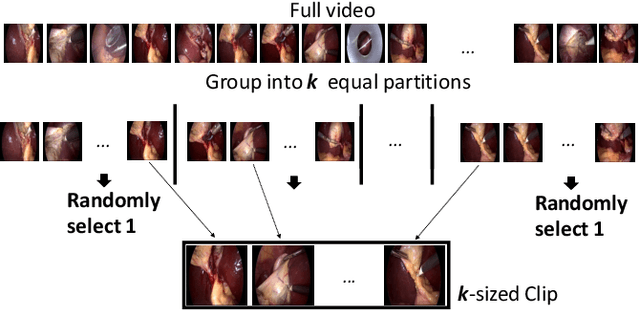
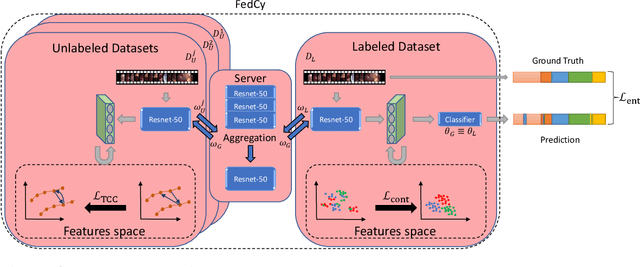
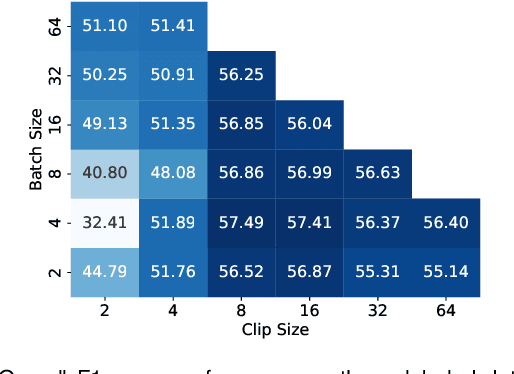
Recent advancements in deep learning methods bring computer-assistance a step closer to fulfilling promises of safer surgical procedures. However, the generalizability of such methods is often dependent on training on diverse datasets from multiple medical institutions, which is a restrictive requirement considering the sensitive nature of medical data. Recently proposed collaborative learning methods such as Federated Learning (FL) allow for training on remote datasets without the need to explicitly share data. Even so, data annotation still represents a bottleneck, particularly in medicine and surgery where clinical expertise is often required. With these constraints in mind, we propose FedCy, a federated semi-supervised learning (FSSL) method that combines FL and self-supervised learning to exploit a decentralized dataset of both labeled and unlabeled videos, thereby improving performance on the task of surgical phase recognition. By leveraging temporal patterns in the labeled data, FedCy helps guide unsupervised training on unlabeled data towards learning task-specific features for phase recognition. We demonstrate significant performance gains over state-of-the-art FSSL methods on the task of automatic recognition of surgical phases using a newly collected multi-institutional dataset of laparoscopic cholecystectomy videos. Furthermore, we demonstrate that our approach also learns more generalizable features when tested on data from an unseen domain.