 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Uncalibrated Multi-View Video Anonymization in the Operating Room
Feb 02, 2026Privacy preservation is a prerequisite for using video data in Operating Room (OR) research. Effective anonymization relies on the exhaustive localization of every individual; even a single missed detection necessitates extensive manual correction. However, existing approaches face two critical scalability bottlenecks: (1) they usually require manual annotations of each new clinical site for high accuracy; (2) while multi-camera setups have been widely adopted to address single-view ambiguity, camera calibration is typically required whenever cameras are repositioned. To address these problems, we propose a novel self-supervised multi-view video anonymization framework consisting of whole-body person detection and whole-body pose estimation, without annotation or camera calibration. Our core strategy is to enhance the single-view detector by "retrieving" false negatives using temporal and multi-view context, and conducting self-supervised domain adaptation. We first run an off-the-shelf whole-body person detector in each view with a low-score threshold to gather candidate detections. Then, we retrieve the low-score false negatives that exhibit consistency with the high-score detections via tracking and self-supervised uncalibrated multi-view association. These recovered detections serve as pseudo labels to iteratively fine-tune the whole-body detector. Finally, we apply whole-body pose estimation on each detected person, and fine-tune the pose model using its own high-score predictions. Experiments on the 4D-OR dataset of simulated surgeries and our dataset of real surgeries show the effectiveness of our approach achieving over 97% recall. Moreover, we train a real-time whole-body detector using our pseudo labels, achieving comparable performance and highlighting our method's practical applicability. Code is available at https://github.com/CAMMA-public/OR_anonymization.
Artificial Intelligence for the Assessment of Peritoneal Carcinosis during Diagnostic Laparoscopy for Advanced Ovarian Cancer
Dec 16, 2025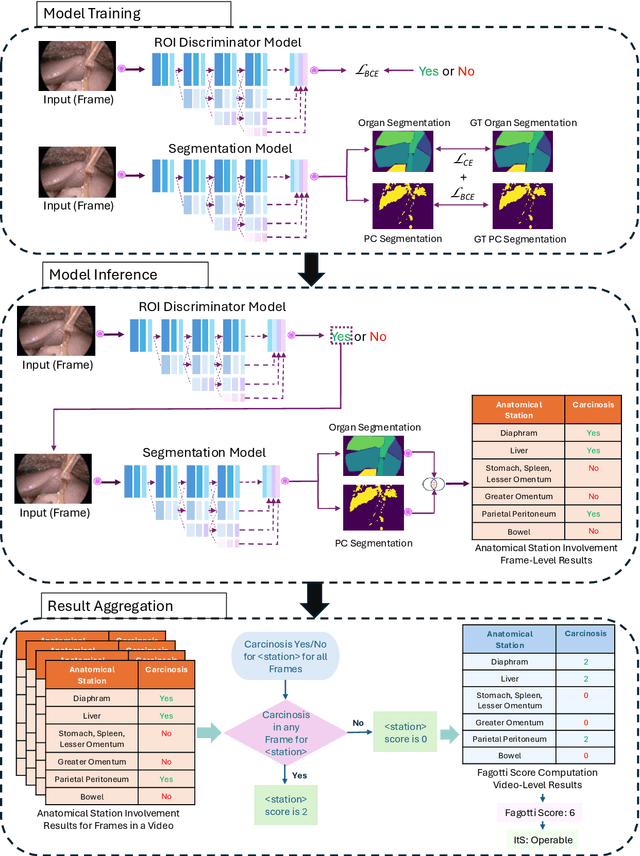
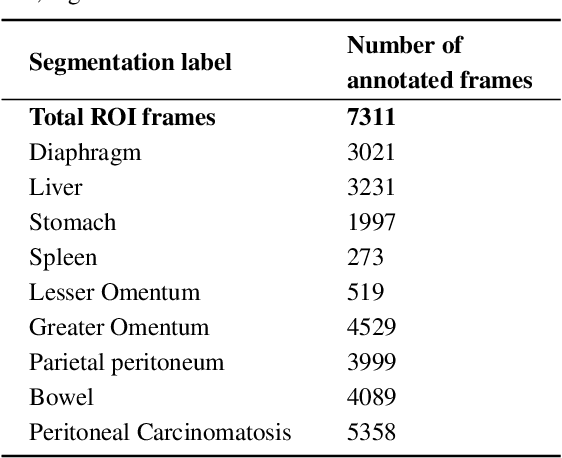


Advanced Ovarian Cancer (AOC) is often diagnosed at an advanced stage with peritoneal carcinosis (PC). Fagotti score (FS) assessment at diagnostic laparoscopy (DL) guides treatment planning by estimating surgical resectability, but its subjective and operator-dependent nature limits reproducibility and widespread use. Videos of patients undergoing DL with concomitant FS assessments at a referral center were retrospectively collected and divided into a development dataset, for data annotation, AI training and evaluation, and an independent test dataset, for internal validation. In the development dataset, FS-relevant frames were manually annotated for anatomical structures and PC. Deep learning models were trained to automatically identify FS-relevant frames, segment structures and PC, and predict video-level FS and indication to surgery (ItS). AI performance was evaluated using Dice score for segmentation, F1-scores for anatomical stations (AS) and ItS prediction, and root mean square error (RMSE) for final FS estimation. In the development dataset, the segmentation model trained on 7,311 frames, achieved Dice scores of 70$\pm$3% for anatomical structures and 56$\pm$3% for PC. Video-level AS classification achieved F1-scores of 74$\pm$3% and 73$\pm$4%, FS prediction showed normalized RMSE values of 1.39$\pm$0.18 and 1.15$\pm$0.08, and ItS reached F1-scores of 80$\pm$8% and 80$\pm$2% in the development (n=101) and independent test datasets (n=50), respectively. This is the first AI model to predict the feasibility of cytoreductive surgery providing automated FS estimation from DL videos. Its reproducible and reliable performance across datasets suggests that AI can support surgeons through standardized intraoperative tumor burden assessment and clinical decision-making in AOC.
Learning from Sparse Point Labels for Dense Carcinosis Localization in Advanced Ovarian Cancer Assessment
Jul 09, 2025Learning from sparse labels is a challenge commonplace in the medical domain. This is due to numerous factors, such as annotation cost, and is especially true for newly introduced tasks. When dense pixel-level annotations are needed, this becomes even more unfeasible. However, being able to learn from just a few annotations at the pixel-level, while extremely difficult and underutilized, can drive progress in studies where perfect annotations are not immediately available. This work tackles the challenge of learning the dense prediction task of keypoint localization from a few point annotations in the context of 2d carcinosis keypoint localization from laparoscopic video frames for diagnostic planning of advanced ovarian cancer patients. To enable this, we formulate the problem as a sparse heatmap regression from a few point annotations per image and propose a new loss function, called Crag and Tail loss, for efficient learning. Our proposed loss function effectively leverages positive sparse labels while minimizing the impact of false negatives or missed annotations. Through an extensive ablation study, we demonstrate the effectiveness of our approach in achieving accurate dense localization of carcinosis keypoints, highlighting its potential to advance research in scenarios where dense annotations are challenging to obtain.
The Endoscapes Dataset for Surgical Scene Segmentation, Object Detection, and Critical View of Safety Assessment: Official Splits and Benchmark
Dec 19, 2023



This technical report provides a detailed overview of Endoscapes, a dataset of laparoscopic cholecystectomy (LC) videos with highly intricate annotations targeted at automated assessment of the Critical View of Safety (CVS). Endoscapes comprises 201 LC videos with frames annotated sparsely but regularly with segmentation masks, bounding boxes, and CVS assessment by three different clinical experts. Altogether, there are 11090 frames annotated with CVS and 1933 frames annotated with tool and anatomy bounding boxes from the 201 videos, as well as an additional 422 frames from 50 of the 201 videos annotated with tool and anatomy segmentation masks. In this report, we provide detailed dataset statistics (size, class distribution, dataset splits, etc.) and a comprehensive performance benchmark for instance segmentation, object detection, and CVS prediction. The dataset and model checkpoints are publically available at https://github.com/CAMMA-public/Endoscapes.
Encoding Surgical Videos as Latent Spatiotemporal Graphs for Object and Anatomy-Driven Reasoning
Dec 11, 2023Recently, spatiotemporal graphs have emerged as a concise and elegant manner of representing video clips in an object-centric fashion, and have shown to be useful for downstream tasks such as action recognition. In this work, we investigate the use of latent spatiotemporal graphs to represent a surgical video in terms of the constituent anatomical structures and tools and their evolving properties over time. To build the graphs, we first predict frame-wise graphs using a pre-trained model, then add temporal edges between nodes based on spatial coherence and visual and semantic similarity. Unlike previous approaches, we incorporate long-term temporal edges in our graphs to better model the evolution of the surgical scene and increase robustness to temporary occlusions. We also introduce a novel graph-editing module that incorporates prior knowledge and temporal coherence to correct errors in the graph, enabling improved downstream task performance. Using our graph representations, we evaluate two downstream tasks, critical view of safety prediction and surgical phase recognition, obtaining strong results that demonstrate the quality and flexibility of the learned representations. Code is available at github.com/CAMMA-public/SurgLatentGraph.
CholecTriplet2022: Show me a tool and tell me the triplet -- an endoscopic vision challenge for surgical action triplet detection
Feb 13, 2023
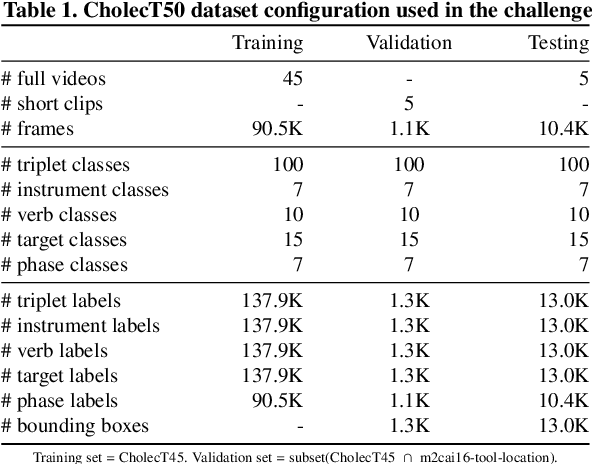
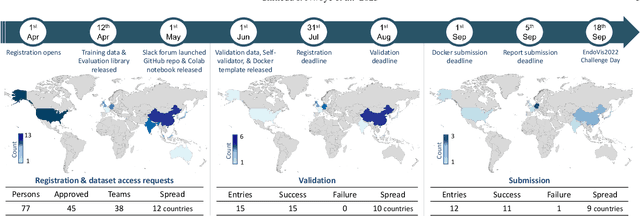
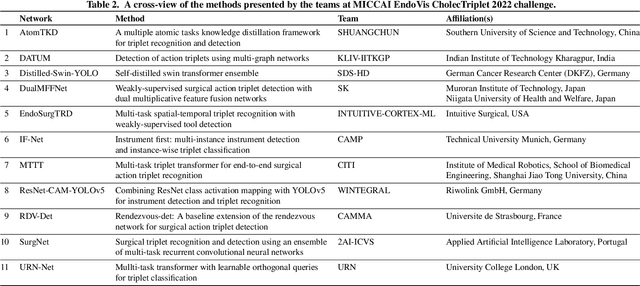
Formalizing surgical activities as triplets of the used instruments, actions performed, and target anatomies is becoming a gold standard approach for surgical activity modeling. The benefit is that this formalization helps to obtain a more detailed understanding of tool-tissue interaction which can be used to develop better Artificial Intelligence assistance for image-guided surgery. Earlier efforts and the CholecTriplet challenge introduced in 2021 have put together techniques aimed at recognizing these triplets from surgical footage. Estimating also the spatial locations of the triplets would offer a more precise intraoperative context-aware decision support for computer-assisted intervention. This paper presents the CholecTriplet2022 challenge, which extends surgical action triplet modeling from recognition to detection. It includes weakly-supervised bounding box localization of every visible surgical instrument (or tool), as the key actors, and the modeling of each tool-activity in the form of <instrument, verb, target> triplet. The paper describes a baseline method and 10 new deep learning algorithms presented at the challenge to solve the task. It also provides thorough methodological comparisons of the methods, an in-depth analysis of the obtained results, their significance, and useful insights for future research directions and applications in surgery.
Preserving Privacy in Surgical Video Analysis Using Artificial Intelligence: A Deep Learning Classifier to Identify Out-of-Body Scenes in Endoscopic Videos
Jan 17, 2023Objective: To develop and validate a deep learning model for the identification of out-of-body images in endoscopic videos. Background: Surgical video analysis facilitates education and research. However, video recordings of endoscopic surgeries can contain privacy-sensitive information, especially if out-of-body scenes are recorded. Therefore, identification of out-of-body scenes in endoscopic videos is of major importance to preserve the privacy of patients and operating room staff. Methods: A deep learning model was trained and evaluated on an internal dataset of 12 different types of laparoscopic and robotic surgeries. External validation was performed on two independent multicentric test datasets of laparoscopic gastric bypass and cholecystectomy surgeries. All images extracted from the video datasets were annotated as inside or out-of-body. Model performance was evaluated compared to human ground truth annotations measuring the receiver operating characteristic area under the curve (ROC AUC). Results: The internal dataset consisting of 356,267 images from 48 videos and the two multicentric test datasets consisting of 54,385 and 58,349 images from 10 and 20 videos, respectively, were annotated. Compared to ground truth annotations, the model identified out-of-body images with 99.97% ROC AUC on the internal test dataset. Mean $\pm$ standard deviation ROC AUC on the multicentric gastric bypass dataset was 99.94$\pm$0.07% and 99.71$\pm$0.40% on the multicentric cholecystectomy dataset, respectively. Conclusion: The proposed deep learning model can reliably identify out-of-body images in endoscopic videos. The trained model is publicly shared. This facilitates privacy preservation in surgical video analysis.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Real-Time Artificial Intelligence Assistance for Safe Laparoscopic Cholecystectomy: Early-Stage Clinical Evaluation
Dec 13, 2022
Artificial intelligence is set to be deployed in operating rooms to improve surgical care. This early-stage clinical evaluation shows the feasibility of concurrently attaining real-time, high-quality predictions from several deep neural networks for endoscopic video analysis deployed for assistance during three laparoscopic cholecystectomies.
Latent Graph Representations for Critical View of Safety Assessment
Dec 08, 2022



Assessing the critical view of safety in laparoscopic cholecystectomy requires accurate identification and localization of key anatomical structures, reasoning about their geometric relationships to one another, and determining the quality of their exposure. In this work, we propose to capture each of these aspects by modeling the surgical scene with a disentangled latent scene graph representation, which we can then process using a graph neural network. Unlike previous approaches using graph representations, we explicitly encode in our graphs semantic information such as object locations and shapes, class probabilities and visual features. We also incorporate an auxiliary image reconstruction objective to help train the latent graph representations. We demonstrate the value of these components through comprehensive ablation studies and achieve state-of-the-art results for critical view of safety prediction across multiple experimental settings.