 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Endoscapes Dataset for Surgical Scene Segmentation, Object Detection, and Critical View of Safety Assessment: Official Splits and Benchmark
Dec 19, 2023



This technical report provides a detailed overview of Endoscapes, a dataset of laparoscopic cholecystectomy (LC) videos with highly intricate annotations targeted at automated assessment of the Critical View of Safety (CVS). Endoscapes comprises 201 LC videos with frames annotated sparsely but regularly with segmentation masks, bounding boxes, and CVS assessment by three different clinical experts. Altogether, there are 11090 frames annotated with CVS and 1933 frames annotated with tool and anatomy bounding boxes from the 201 videos, as well as an additional 422 frames from 50 of the 201 videos annotated with tool and anatomy segmentation masks. In this report, we provide detailed dataset statistics (size, class distribution, dataset splits, etc.) and a comprehensive performance benchmark for instance segmentation, object detection, and CVS prediction. The dataset and model checkpoints are publically available at https://github.com/CAMMA-public/Endoscapes.
Encoding Surgical Videos as Latent Spatiotemporal Graphs for Object and Anatomy-Driven Reasoning
Dec 11, 2023Recently, spatiotemporal graphs have emerged as a concise and elegant manner of representing video clips in an object-centric fashion, and have shown to be useful for downstream tasks such as action recognition. In this work, we investigate the use of latent spatiotemporal graphs to represent a surgical video in terms of the constituent anatomical structures and tools and their evolving properties over time. To build the graphs, we first predict frame-wise graphs using a pre-trained model, then add temporal edges between nodes based on spatial coherence and visual and semantic similarity. Unlike previous approaches, we incorporate long-term temporal edges in our graphs to better model the evolution of the surgical scene and increase robustness to temporary occlusions. We also introduce a novel graph-editing module that incorporates prior knowledge and temporal coherence to correct errors in the graph, enabling improved downstream task performance. Using our graph representations, we evaluate two downstream tasks, critical view of safety prediction and surgical phase recognition, obtaining strong results that demonstrate the quality and flexibility of the learned representations. Code is available at github.com/CAMMA-public/SurgLatentGraph.
Latent Graph Representations for Critical View of Safety Assessment
Dec 08, 2022



Assessing the critical view of safety in laparoscopic cholecystectomy requires accurate identification and localization of key anatomical structures, reasoning about their geometric relationships to one another, and determining the quality of their exposure. In this work, we propose to capture each of these aspects by modeling the surgical scene with a disentangled latent scene graph representation, which we can then process using a graph neural network. Unlike previous approaches using graph representations, we explicitly encode in our graphs semantic information such as object locations and shapes, class probabilities and visual features. We also incorporate an auxiliary image reconstruction objective to help train the latent graph representations. We demonstrate the value of these components through comprehensive ablation studies and achieve state-of-the-art results for critical view of safety prediction across multiple experimental settings.
Temporally Constrained Neural Networks (TCNN): A framework for semi-supervised video semantic segmentation
Dec 27, 2021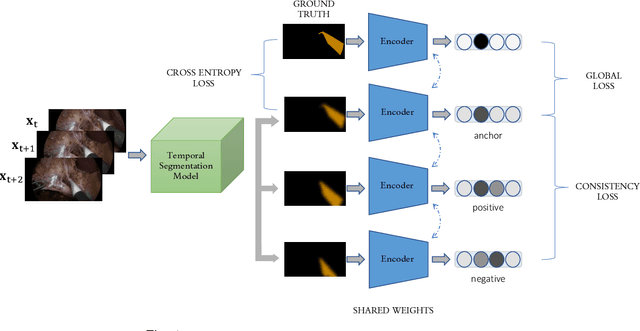
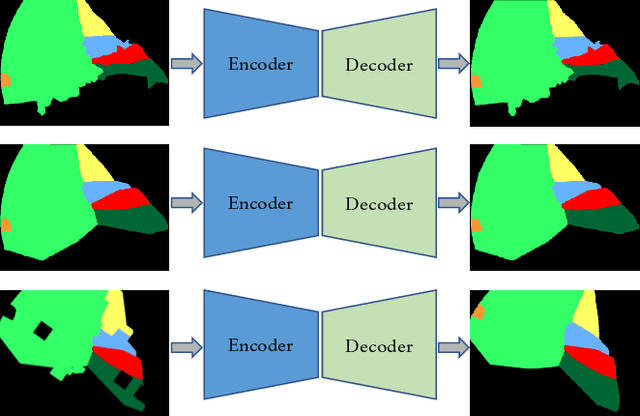
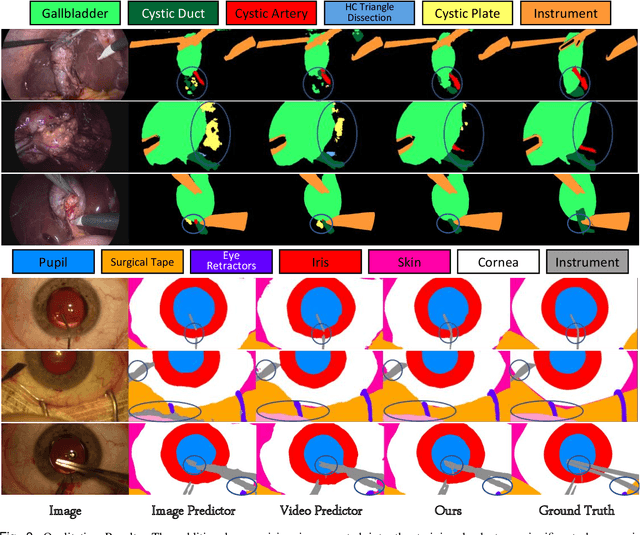
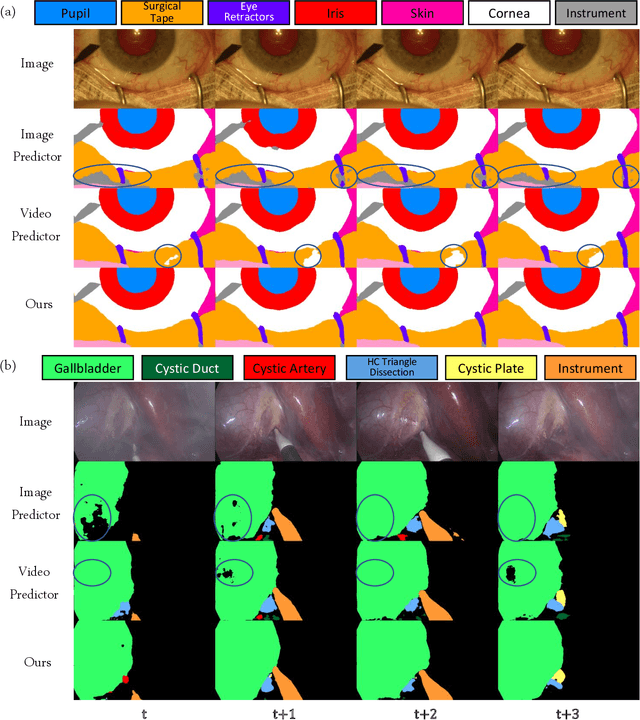
A major obstacle to building models for effective semantic segmentation, and particularly video semantic segmentation, is a lack of large and well annotated datasets. This bottleneck is particularly prohibitive in highly specialized and regulated fields such as medicine and surgery, where video semantic segmentation could have important applications but data and expert annotations are scarce. In these settings, temporal clues and anatomical constraints could be leveraged during training to improve performance. Here, we present Temporally Constrained Neural Networks (TCNN), a semi-supervised framework used for video semantic segmentation of surgical videos. In this work, we show that autoencoder networks can be used to efficiently provide both spatial and temporal supervisory signals to train deep learning models. We test our method on a newly introduced video dataset of laparoscopic cholecystectomy procedures, Endoscapes, and an adaptation of a public dataset of cataract surgeries, CaDIS. We demonstrate that lower-dimensional representations of predicted masks can be leveraged to provide a consistent improvement on both sparsely labeled datasets with no additional computational cost at inference time. Further, the TCNN framework is model-agnostic and can be used in conjunction with other model design choices with minimal additional complexity.
Surgical data science for safe cholecystectomy: a protocol for segmentation of hepatocystic anatomy and assessment of the critical view of safety
Jun 21, 2021
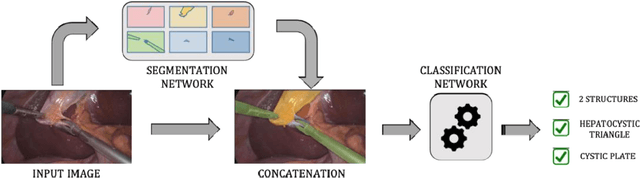
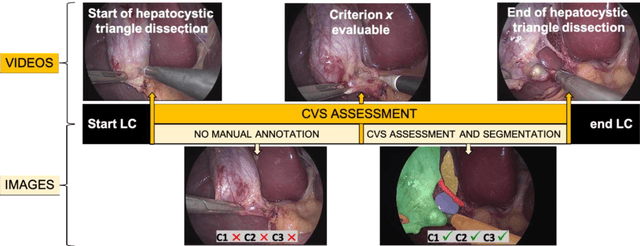
Minimally invasive image-guided surgery heavily relies on vision. Deep learning models for surgical video analysis could therefore support visual tasks such as assessing the critical view of safety (CVS) in laparoscopic cholecystectomy (LC), potentially contributing to surgical safety and efficiency. However, the performance, reliability and reproducibility of such models are deeply dependent on the quality of data and annotations used in their development. Here, we present a protocol, checklists, and visual examples to promote consistent annotation of hepatocystic anatomy and CVS criteria. We believe that sharing annotation guidelines can help build trustworthy multicentric datasets for assessing generalizability of performance, thus accelerating the clinical translation of deep learning models for surgical video analysis.