 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence for the Assessment of Peritoneal Carcinosis during Diagnostic Laparoscopy for Advanced Ovarian Cancer
Dec 16, 2025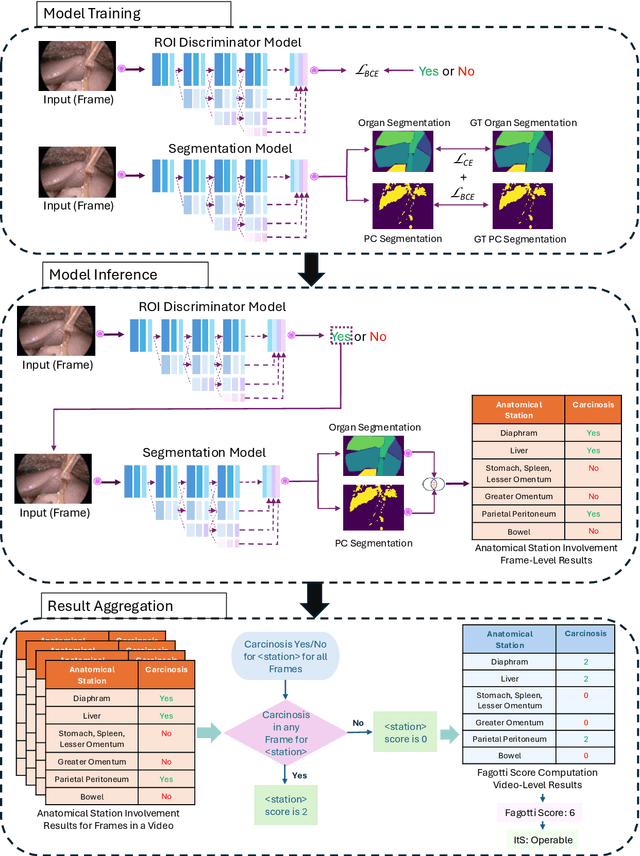
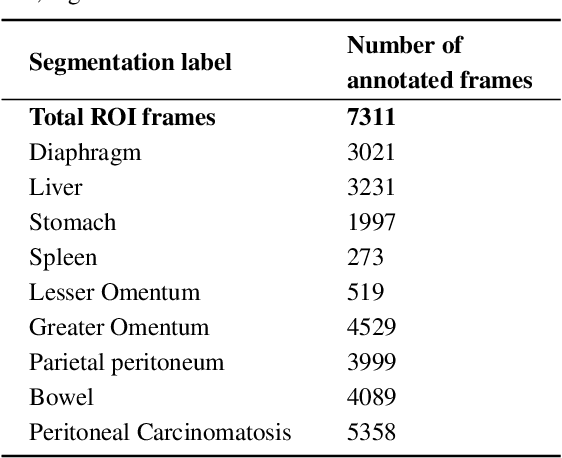


Advanced Ovarian Cancer (AOC) is often diagnosed at an advanced stage with peritoneal carcinosis (PC). Fagotti score (FS) assessment at diagnostic laparoscopy (DL) guides treatment planning by estimating surgical resectability, but its subjective and operator-dependent nature limits reproducibility and widespread use. Videos of patients undergoing DL with concomitant FS assessments at a referral center were retrospectively collected and divided into a development dataset, for data annotation, AI training and evaluation, and an independent test dataset, for internal validation. In the development dataset, FS-relevant frames were manually annotated for anatomical structures and PC. Deep learning models were trained to automatically identify FS-relevant frames, segment structures and PC, and predict video-level FS and indication to surgery (ItS). AI performance was evaluated using Dice score for segmentation, F1-scores for anatomical stations (AS) and ItS prediction, and root mean square error (RMSE) for final FS estimation. In the development dataset, the segmentation model trained on 7,311 frames, achieved Dice scores of 70$\pm$3% for anatomical structures and 56$\pm$3% for PC. Video-level AS classification achieved F1-scores of 74$\pm$3% and 73$\pm$4%, FS prediction showed normalized RMSE values of 1.39$\pm$0.18 and 1.15$\pm$0.08, and ItS reached F1-scores of 80$\pm$8% and 80$\pm$2% in the development (n=101) and independent test datasets (n=50), respectively. This is the first AI model to predict the feasibility of cytoreductive surgery providing automated FS estimation from DL videos. Its reproducible and reliable performance across datasets suggests that AI can support surgeons through standardized intraoperative tumor burden assessment and clinical decision-making in AOC.
Surgeons Awareness, Expectations, and Involvement with Artificial Intelligence: a Survey Pre and Post the GPT Era
Jun 09, 2025Artificial Intelligence (AI) is transforming medicine, with generative AI models like ChatGPT reshaping perceptions of its potential. This study examines surgeons' awareness, expectations, and involvement with AI in surgery through comparative surveys conducted in 2021 and 2024. Two cross-sectional surveys were distributed globally in 2021 and 2024, the first before an IRCAD webinar and the second during the annual EAES meeting. The surveys assessed demographics, AI awareness, expectations, involvement, and ethics (2024 only). The surveys collected a total of 671 responses from 98 countries, 522 in 2021 and 149 in 2024. Awareness of AI courses rose from 14.5% in 2021 to 44.6% in 2024, while course attendance increased from 12.9% to 23%. Despite this, familiarity with foundational AI concepts remained limited. Expectations for AI's role shifted in 2024, with hospital management gaining relevance. Ethical concerns gained prominence, with 87.2% of 2024 participants emphasizing accountability and transparency. Infrastructure limitations remained the primary obstacle to implementation. Interdisciplinary collaboration and structured training were identified as critical for successful AI adoption. Optimism about AI's transformative potential remained high, with 79.9% of respondents believing AI would positively impact surgery and 96.6% willing to integrate AI into their clinical practice. Surgeons' perceptions of AI are evolving, driven by the rise of generative AI and advancements in surgical data science. While enthusiasm for integration is strong, knowledge gaps and infrastructural challenges persist. Addressing these through education, ethical frameworks, and infrastructure development is essential.
The Endoscapes Dataset for Surgical Scene Segmentation, Object Detection, and Critical View of Safety Assessment: Official Splits and Benchmark
Dec 19, 2023



This technical report provides a detailed overview of Endoscapes, a dataset of laparoscopic cholecystectomy (LC) videos with highly intricate annotations targeted at automated assessment of the Critical View of Safety (CVS). Endoscapes comprises 201 LC videos with frames annotated sparsely but regularly with segmentation masks, bounding boxes, and CVS assessment by three different clinical experts. Altogether, there are 11090 frames annotated with CVS and 1933 frames annotated with tool and anatomy bounding boxes from the 201 videos, as well as an additional 422 frames from 50 of the 201 videos annotated with tool and anatomy segmentation masks. In this report, we provide detailed dataset statistics (size, class distribution, dataset splits, etc.) and a comprehensive performance benchmark for instance segmentation, object detection, and CVS prediction. The dataset and model checkpoints are publically available at https://github.com/CAMMA-public/Endoscapes.
Challenges in Multi-centric Generalization: Phase and Step Recognition in Roux-en-Y Gastric Bypass Surgery
Dec 18, 2023Most studies on surgical activity recognition utilizing Artificial intelligence (AI) have focused mainly on recognizing one type of activity from small and mono-centric surgical video datasets. It remains speculative whether those models would generalize to other centers. In this work, we introduce a large multi-centric multi-activity dataset consisting of 140 videos (MultiBypass140) of laparoscopic Roux-en-Y gastric bypass (LRYGB) surgeries performed at two medical centers: the University Hospital of Strasbourg (StrasBypass70) and Inselspital, Bern University Hospital (BernBypass70). The dataset has been fully annotated with phases and steps. Furthermore, we assess the generalizability and benchmark different deep learning models in 7 experimental studies: 1) Training and evaluation on BernBypass70; 2) Training and evaluation on StrasBypass70; 3) Training and evaluation on the MultiBypass140; 4) Training on BernBypass70, evaluation on StrasBypass70; 5) Training on StrasBypass70, evaluation on BernBypass70; Training on MultiBypass140, evaluation 6) on BernBypass70 and 7) on StrasBypass70. The model's performance is markedly influenced by the training data. The worst results were obtained in experiments 4) and 5) confirming the limited generalization capabilities of models trained on mono-centric data. The use of multi-centric training data, experiments 6) and 7), improves the generalization capabilities of the models, bringing them beyond the level of independent mono-centric training and validation (experiments 1) and 2)). MultiBypass140 shows considerable variation in surgical technique and workflow of LRYGB procedures between centers. Therefore, generalization experiments demonstrate a remarkable difference in model performance. These results highlight the importance of multi-centric datasets for AI model generalization to account for variance in surgical technique and workflows.
TRUSTED: The Paired 3D Transabdominal Ultrasound and CT Human Data for Kidney Segmentation and Registration Research
Oct 19, 2023Inter-modal image registration (IMIR) and image segmentation with abdominal Ultrasound (US) data has many important clinical applications, including image-guided surgery, automatic organ measurement and robotic navigation. However, research is severely limited by the lack of public datasets. We propose TRUSTED (the Tridimensional Renal Ultra Sound TomodEnsitometrie Dataset), comprising paired transabdominal 3DUS and CT kidney images from 48 human patients (96 kidneys), including segmentation, and anatomical landmark annotations by two experienced radiographers. Inter-rater segmentation agreement was over 94 (Dice score), and gold-standard segmentations were generated using the STAPLE algorithm. Seven anatomical landmarks were annotated, important for IMIR systems development and evaluation. To validate the dataset's utility, 5 competitive Deep Learning models for automatic kidney segmentation were benchmarked, yielding average DICE scores from 83.2% to 89.1% for CT, and 61.9% to 79.4% for US images. Three IMIR methods were benchmarked, and Coherent Point Drift performed best with an average Target Registration Error of 4.53mm. The TRUSTED dataset may be used freely researchers to develop and validate new segmentation and IMIR methods.
Weakly Supervised Temporal Convolutional Networks for Fine-grained Surgical Activity Recognition
Feb 21, 2023



Automatic recognition of fine-grained surgical activities, called steps, is a challenging but crucial task for intelligent intra-operative computer assistance. The development of current vision-based activity recognition methods relies heavily on a high volume of manually annotated data. This data is difficult and time-consuming to generate and requires domain-specific knowledge. In this work, we propose to use coarser and easier-to-annotate activity labels, namely phases, as weak supervision to learn step recognition with fewer step annotated videos. We introduce a step-phase dependency loss to exploit the weak supervision signal. We then employ a Single-Stage Temporal Convolutional Network (SS-TCN) with a ResNet-50 backbone, trained in an end-to-end fashion from weakly annotated videos, for temporal activity segmentation and recognition. We extensively evaluate and show the effectiveness of the proposed method on a large video dataset consisting of 40 laparoscopic gastric bypass procedures and the public benchmark CATARACTS containing 50 cataract surgeries.
Live Laparoscopic Video Retrieval with Compressed Uncertainty
Mar 08, 2022Searching through large volumes of medical data to retrieve relevant information is a challenging yet crucial task for clinical care. However the primitive and most common approach to retrieval, involving text in the form of keywords, is severely limited when dealing with complex media formats. Content-based retrieval offers a way to overcome this limitation, by using rich media as the query itself. Surgical video-to-video retrieval in particular is a new and largely unexplored research problem with high clinical value, especially in the real-time case: using real-time video hashing, search can be achieved directly inside of the operating room. Indeed, the process of hashing converts large data entries into compact binary arrays or hashes, enabling large-scale search operations at a very fast rate. However, due to fluctuations over the course of a video, not all bits in a given hash are equally reliable. In this work, we propose a method capable of mitigating this uncertainty while maintaining a light computational footprint. We present superior retrieval results (3-4 % top 10 mean average precision) on a multi-task evaluation protocol for surgery, using cholecystectomy phases, bypass phases, and coming from an entirely new dataset introduced here, critical events across six different surgery types. Success on this multi-task benchmark shows the generalizability of our approach for surgical video retrieval.
Temporally Constrained Neural Networks (TCNN): A framework for semi-supervised video semantic segmentation
Dec 27, 2021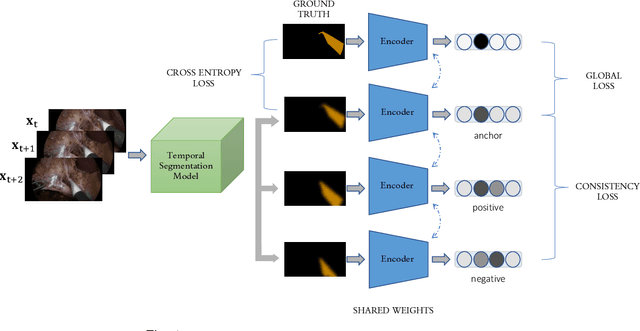
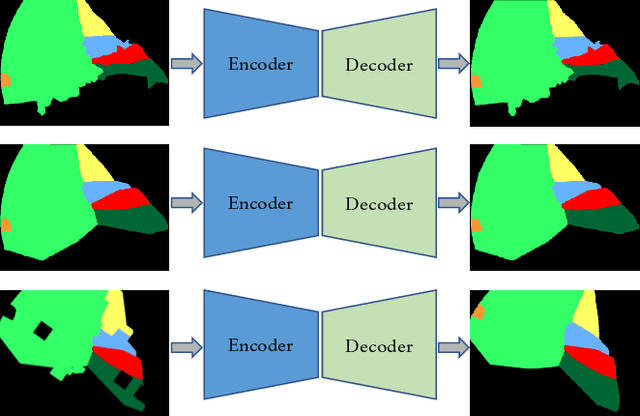
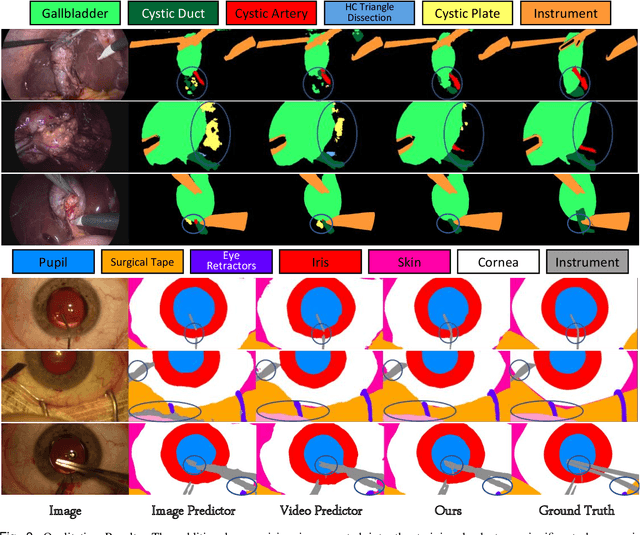
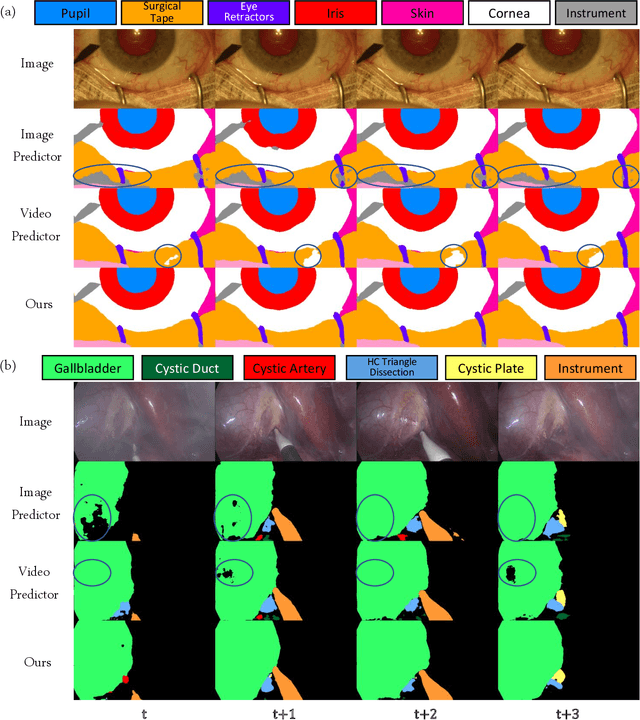
A major obstacle to building models for effective semantic segmentation, and particularly video semantic segmentation, is a lack of large and well annotated datasets. This bottleneck is particularly prohibitive in highly specialized and regulated fields such as medicine and surgery, where video semantic segmentation could have important applications but data and expert annotations are scarce. In these settings, temporal clues and anatomical constraints could be leveraged during training to improve performance. Here, we present Temporally Constrained Neural Networks (TCNN), a semi-supervised framework used for video semantic segmentation of surgical videos. In this work, we show that autoencoder networks can be used to efficiently provide both spatial and temporal supervisory signals to train deep learning models. We test our method on a newly introduced video dataset of laparoscopic cholecystectomy procedures, Endoscapes, and an adaptation of a public dataset of cataract surgeries, CaDIS. We demonstrate that lower-dimensional representations of predicted masks can be leveraged to provide a consistent improvement on both sparsely labeled datasets with no additional computational cost at inference time. Further, the TCNN framework is model-agnostic and can be used in conjunction with other model design choices with minimal additional complexity.
Rendezvous: Attention Mechanisms for the Recognition of Surgical Action Triplets in Endoscopic Videos
Sep 07, 2021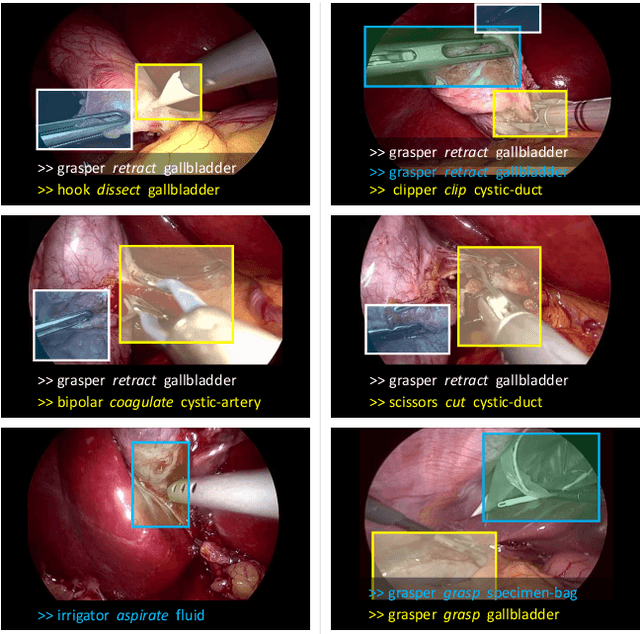
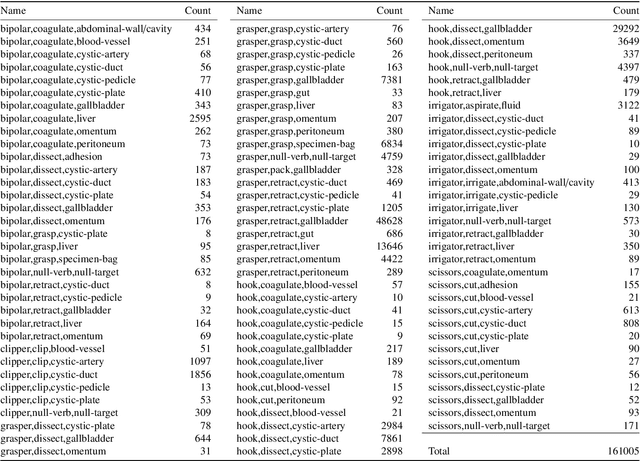
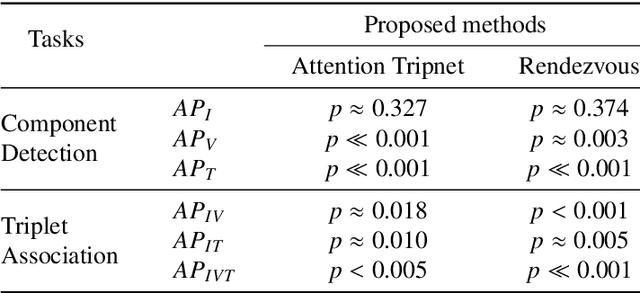
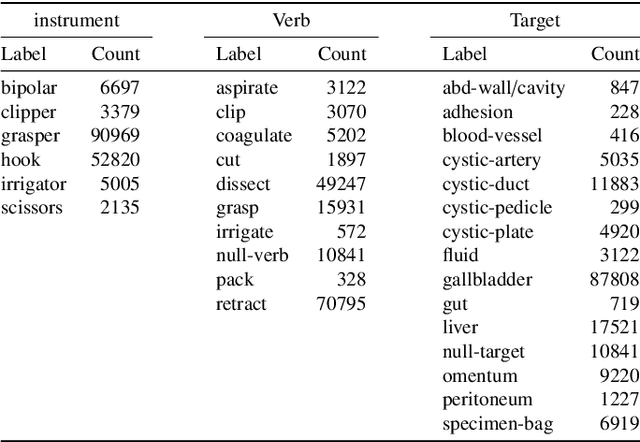
Out of all existing frameworks for surgical workflow analysis in endoscopic videos, action triplet recognition stands out as the only one aiming to provide truly fine-grained and comprehensive information on surgical activities. This information, presented as <instrument, verb, target> combinations, is highly challenging to be accurately identified. Triplet components can be difficult to recognize individually; in this task, it requires not only performing recognition simultaneously for all three triplet components, but also correctly establishing the data association between them. To achieve this task, we introduce our new model, the Rendezvous (RDV), which recognizes triplets directly from surgical videos by leveraging attention at two different levels. We first introduce a new form of spatial attention to capture individual action triplet components in a scene; called the Class Activation Guided Attention Mechanism (CAGAM). This technique focuses on the recognition of verbs and targets using activations resulting from instruments. To solve the association problem, our RDV model adds a new form of semantic attention inspired by Transformer networks. Using multiple heads of cross and self attentions, RDV is able to effectively capture relationships between instruments, verbs, and targets. We also introduce CholecT50 - a dataset of 50 endoscopic videos in which every frame has been annotated with labels from 100 triplet classes. Our proposed RDV model significantly improves the triplet prediction mAP by over 9% compared to the state-of-the-art methods on this dataset.
Multi-Task Temporal Convolutional Networks for Joint Recognition of Surgical Phases and Steps in Gastric Bypass Procedures
Feb 24, 2021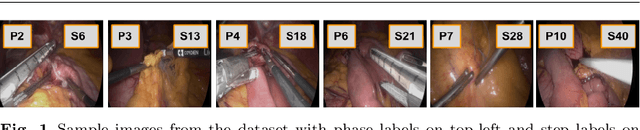
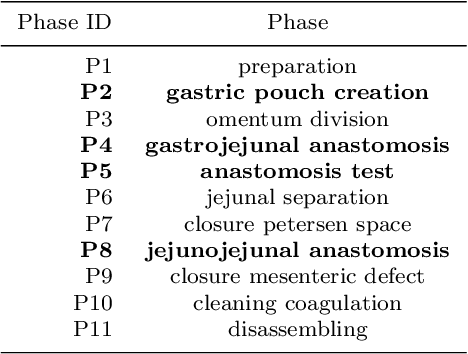


Purpose: Automatic segmentation and classification of surgical activity is crucial for providing advanced support in computer-assisted interventions and autonomous functionalities in robot-assisted surgeries. Prior works have focused on recognizing either coarse activities, such as phases, or fine-grained activities, such as gestures. This work aims at jointly recognizing two complementary levels of granularity directly from videos, namely phases and steps. Method: We introduce two correlated surgical activities, phases and steps, for the laparoscopic gastric bypass procedure. We propose a Multi-task Multi-Stage Temporal Convolutional Network (MTMS-TCN) along with a multi-task Convolutional Neural Network (CNN) training setup to jointly predict the phases and steps and benefit from their complementarity to better evaluate the execution of the procedure. We evaluate the proposed method on a large video dataset consisting of 40 surgical procedures (Bypass40). Results: We present experimental results from several baseline models for both phase and step recognition on the Bypass40 dataset. The proposed MTMS-TCN method outperforms in both phase and step recognition by 1-2% in accuracy, precision and recall, compared to single-task methods. Furthermore, for step recognition, MTMS-TCN achieves a superior performance of 3-6% compared to LSTM based models in accuracy, precision, and recall. Conclusion: In this work, we present a multi-task multi-stage temporal convolutional network for surgical activity recognition, which shows improved results compared to single-task models on the Bypass40 gastric bypass dataset with multi-level annotations. The proposed method shows that the joint modeling of phases and steps is beneficial to improve the overall recognition of each type of activity.