 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Learning Objectives of Vision-Language Reward Models
Dec 20, 2025Learning generalizable reward functions is a core challenge in embodied intelligence. Recent work leverages contrastive vision language models (VLMs) to obtain dense, domain-agnostic rewards without human supervision. These methods adapt VLMs into reward models through increasingly complex learning objectives, yet meaningful comparison remains difficult due to differences in training data, architectures, and evaluation settings. In this work, we isolate the impact of the learning objective by evaluating recent VLM-based reward models under a unified framework with identical backbones, finetuning data, and evaluation environments. Using Meta-World tasks, we assess modeling accuracy by measuring consistency with ground truth reward and correlation with expert progress. Remarkably, we show that a simple triplet loss outperforms state-of-the-art methods, suggesting that much of the improvements in recent approaches could be attributed to differences in data and architectures.
DAFTED: Decoupled Asymmetric Fusion of Tabular and Echocardiographic Data for Cardiac Hypertension Diagnosis
Sep 19, 2025Multimodal data fusion is a key approach for enhancing diagnosis in medical applications. We propose an asymmetric fusion strategy starting from a primary modality and integrating secondary modalities by disentangling shared and modality-specific information. Validated on a dataset of 239 patients with echocardiographic time series and tabular records, our model outperforms existing methods, achieving an AUC over 90%. This improvement marks a crucial benchmark for clinical use.
ViLU: Learning Vision-Language Uncertainties for Failure Prediction
Jul 10, 2025Reliable Uncertainty Quantification (UQ) and failure prediction remain open challenges for Vision-Language Models (VLMs). We introduce ViLU, a new Vision-Language Uncertainty quantification framework that contextualizes uncertainty estimates by leveraging all task-relevant textual representations. ViLU constructs an uncertainty-aware multi-modal representation by integrating the visual embedding, the predicted textual embedding, and an image-conditioned textual representation via cross-attention. Unlike traditional UQ methods based on loss prediction, ViLU trains an uncertainty predictor as a binary classifier to distinguish correct from incorrect predictions using a weighted binary cross-entropy loss, making it loss-agnostic. In particular, our proposed approach is well-suited for post-hoc settings, where only vision and text embeddings are available without direct access to the model itself. Extensive experiments on diverse datasets show the significant gains of our method compared to state-of-the-art failure prediction methods. We apply our method to standard classification datasets, such as ImageNet-1k, as well as large-scale image-caption datasets like CC12M and LAION-400M. Ablation studies highlight the critical role of our architecture and training in achieving effective uncertainty quantification. Our code is publicly available and can be found here: https://github.com/ykrmm/ViLU.
UP-ROM : Uncertainty-Aware and Parametrised dynamic Reduced-Order Model, application to unsteady flows
Mar 29, 2025



Reduced order models (ROMs) play a critical role in fluid mechanics by providing low-cost predictions, making them an attractive tool for engineering applications. However, for ROMs to be widely applicable, they must not only generalise well across different regimes, but also provide a measure of confidence in their predictions. While recent data-driven approaches have begun to address nonlinear reduction techniques to improve predictions in transient environments, challenges remain in terms of robustness and parametrisation. In this work, we present a nonlinear reduction strategy specifically designed for transient flows that incorporates parametrisation and uncertainty quantification. Our reduction strategy features a variational auto-encoder (VAE) that uses variational inference for confidence measurement. We use a latent space transformer that incorporates recent advances in attention mechanisms to predict dynamical systems. Attention's versatility in learning sequences and capturing their dependence on external parameters enhances generalisation across a wide range of dynamics. Prediction, coupled with confidence, enables more informed decision making and addresses the need for more robust models. In addition, this confidence is used to cost-effectively sample the parameter space, improving model performance a priori across the entire parameter space without requiring evaluation data for the entire domain.
VIPER: Visual Perception and Explainable Reasoning for Sequential Decision-Making
Mar 19, 2025While Large Language Models (LLMs) excel at reasoning on text and Vision-Language Models (VLMs) are highly effective for visual perception, applying those models for visual instruction-based planning remains a widely open problem. In this paper, we introduce VIPER, a novel framework for multimodal instruction-based planning that integrates VLM-based perception with LLM-based reasoning. Our approach uses a modular pipeline where a frozen VLM generates textual descriptions of image observations, which are then processed by an LLM policy to predict actions based on the task goal. We fine-tune the reasoning module using behavioral cloning and reinforcement learning, improving our agent's decision-making capabilities. Experiments on the ALFWorld benchmark show that VIPER significantly outperforms state-of-the-art visual instruction-based planners while narrowing the gap with purely text-based oracles. By leveraging text as an intermediate representation, VIPER also enhances explainability, paving the way for a fine-grained analysis of perception and reasoning components.
Reinforcement Learning for Aligning Large Language Models Agents with Interactive Environments: Quantifying and Mitigating Prompt Overfitting
Oct 29, 2024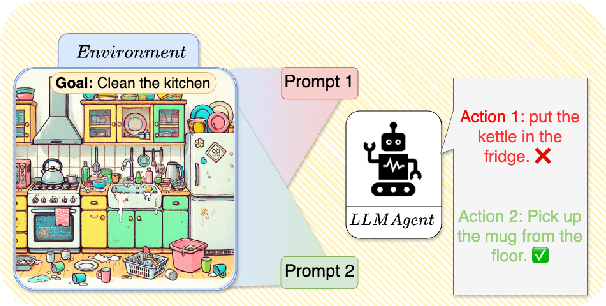
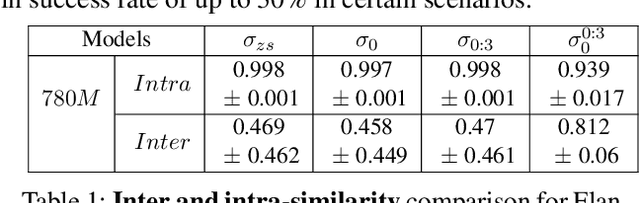
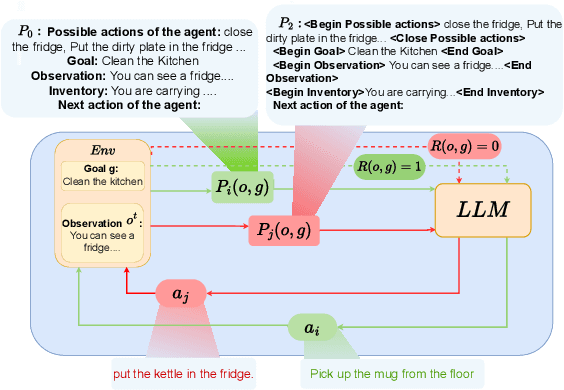
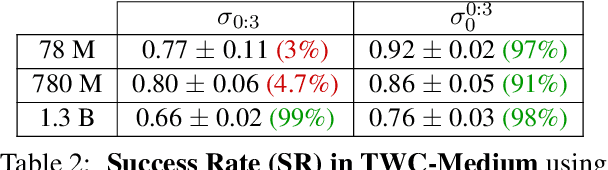
Reinforcement learning (RL) is a promising approach for aligning large language models (LLMs) knowledge with sequential decision-making tasks. However, few studies have thoroughly investigated the impact on LLM agents capabilities of fine-tuning them with RL in a specific environment. In this paper, we propose a novel framework to analyze the sensitivity of LLMs to prompt formulations following RL training in a textual environment. Our findings reveal that the performance of LLMs degrades when faced with prompt formulations different from those used during the RL training phase. Besides, we analyze the source of this sensitivity by examining the model's internal representations and salient tokens. Finally, we propose to use a contrastive loss to mitigate this sensitivity and improve the robustness and generalization capabilities of LLMs.
Supra-Laplacian Encoding for Transformer on Dynamic Graphs
Sep 26, 2024



Fully connected Graph Transformers (GT) have rapidly become prominent in the static graph community as an alternative to Message-Passing models, which suffer from a lack of expressivity, oversquashing, and under-reaching. However, in a dynamic context, by interconnecting all nodes at multiple snapshots with self-attention, GT loose both structural and temporal information. In this work, we introduce Supra-LAplacian encoding for spatio-temporal TransformErs (SLATE), a new spatio-temporal encoding to leverage the GT architecture while keeping spatio-temporal information. Specifically, we transform Discrete Time Dynamic Graphs into multi-layer graphs and take advantage of the spectral properties of their associated supra-Laplacian matrix. Our second contribution explicitly model nodes' pairwise relationships with a cross-attention mechanism, providing an accurate edge representation for dynamic link prediction. SLATE outperforms numerous state-of-the-art methods based on Message-Passing Graph Neural Networks combined with recurrent models (e.g LSTM), and Dynamic Graph Transformers, on 9 datasets. Code and instructions to reproduce our results will be open-sourced.
Temporal receptive field in dynamic graph learning: A comprehensive analysis
Jul 19, 2024



Dynamic link prediction is a critical task in the analysis of evolving networks, with applications ranging from recommender systems to economic exchanges. However, the concept of the temporal receptive field, which refers to the temporal context that models use for making predictions, has been largely overlooked and insufficiently analyzed in existing research. In this study, we present a comprehensive analysis of the temporal receptive field in dynamic graph learning. By examining multiple datasets and models, we formalize the role of temporal receptive field and highlight their crucial influence on predictive accuracy. Our results demonstrate that appropriately chosen temporal receptive field can significantly enhance model performance, while for some models, overly large windows may introduce noise and reduce accuracy. We conduct extensive benchmarking to validate our findings, ensuring that all experiments are fully reproducible. Code is available at https://github.com/ykrmm/BenchmarkTW .
ITEM: Improving Training and Evaluation of Message-Passing based GNNs for top-k recommendation
Jul 03, 2024



Graph Neural Networks (GNNs), especially message-passing-based models, have become prominent in top-k recommendation tasks, outperforming matrix factorization models due to their ability to efficiently aggregate information from a broader context. Although GNNs are evaluated with ranking-based metrics, e.g NDCG@k and Recall@k, they remain largely trained with proxy losses, e.g the BPR loss. In this work we explore the use of ranking loss functions to directly optimize the evaluation metrics, an area not extensively investigated in the GNN community for collaborative filtering. We take advantage of smooth approximations of the rank to facilitate end-to-end training of GNNs and propose a Personalized PageRank-based negative sampling strategy tailored for ranking loss functions. Moreover, we extend the evaluation of GNN models for top-k recommendation tasks with an inductive user-centric protocol, providing a more accurate reflection of real-world applications. Our proposed method significantly outperforms the standard BPR loss and more advanced losses across four datasets and four recent GNN architectures while also exhibiting faster training. Demonstrating the potential of ranking loss functions in improving GNN training for collaborative filtering tasks.
Physics-Informed Model and Hybrid Planning for Efficient Dyna-Style Reinforcement Learning
Jul 02, 2024



Applying reinforcement learning (RL) to real-world applications requires addressing a trade-off between asymptotic performance, sample efficiency, and inference time. In this work, we demonstrate how to address this triple challenge by leveraging partial physical knowledge about the system dynamics. Our approach involves learning a physics-informed model to boost sample efficiency and generating imaginary trajectories from this model to learn a model-free policy and Q-function. Furthermore, we propose a hybrid planning strategy, combining the learned policy and Q-function with the learned model to enhance time efficiency in planning. Through practical demonstrations, we illustrate that our method improves the compromise between sample efficiency, time efficiency, and performance over state-of-the-art methods.