 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViLU: Learning Vision-Language Uncertainties for Failure Prediction
Jul 10, 2025Reliable Uncertainty Quantification (UQ) and failure prediction remain open challenges for Vision-Language Models (VLMs). We introduce ViLU, a new Vision-Language Uncertainty quantification framework that contextualizes uncertainty estimates by leveraging all task-relevant textual representations. ViLU constructs an uncertainty-aware multi-modal representation by integrating the visual embedding, the predicted textual embedding, and an image-conditioned textual representation via cross-attention. Unlike traditional UQ methods based on loss prediction, ViLU trains an uncertainty predictor as a binary classifier to distinguish correct from incorrect predictions using a weighted binary cross-entropy loss, making it loss-agnostic. In particular, our proposed approach is well-suited for post-hoc settings, where only vision and text embeddings are available without direct access to the model itself. Extensive experiments on diverse datasets show the significant gains of our method compared to state-of-the-art failure prediction methods. We apply our method to standard classification datasets, such as ImageNet-1k, as well as large-scale image-caption datasets like CC12M and LAION-400M. Ablation studies highlight the critical role of our architecture and training in achieving effective uncertainty quantification. Our code is publicly available and can be found here: https://github.com/ykrmm/ViLU.
Zero-Shot Image Segmentation via Recursive Normalized Cut on Diffusion Features
Jun 05, 2024



Foundation models have emerged as powerful tools across various domains including language, vision, and multimodal tasks. While prior works have addressed unsupervised image segmentation, they significantly lag behind supervised models. In this paper, we use a diffusion UNet encoder as a foundation vision encoder and introduce DiffCut, an unsupervised zero-shot segmentation method that solely harnesses the output features from the final self-attention block. Through extensive experimentation, we demonstrate that the utilization of these diffusion features in a graph based segmentation algorithm, significantly outperforms previous state-of-the-art methods on zero-shot segmentation. Specifically, we leverage a recursive Normalized Cut algorithm that softly regulates the granularity of detected objects and produces well-defined segmentation maps that precisely capture intricate image details. Our work highlights the remarkably accurate semantic knowledge embedded within diffusion UNet encoders that could then serve as foundation vision encoders for downstream tasks. Project page at https://diffcut-segmentation.github.io
FreeSeg-Diff: Training-Free Open-Vocabulary Segmentation with Diffusion Models
Mar 29, 2024



Foundation models have exhibited unprecedented capabilities in tackling many domains and tasks. Models such as CLIP are currently widely used to bridge cross-modal representations, and text-to-image diffusion models are arguably the leading models in terms of realistic image generation. Image generative models are trained on massive datasets that provide them with powerful internal spatial representations. In this work, we explore the potential benefits of such representations, beyond image generation, in particular, for dense visual prediction tasks. We focus on the task of image segmentation, which is traditionally solved by training models on closed-vocabulary datasets, with pixel-level annotations. To avoid the annotation cost or training large diffusion models, we constraint our setup to be zero-shot and training-free. In a nutshell, our pipeline leverages different and relatively small-sized, open-source foundation models for zero-shot open-vocabulary segmentation. The pipeline is as follows: the image is passed to both a captioner model (i.e. BLIP) and a diffusion model (i.e., Stable Diffusion Model) to generate a text description and visual representation, respectively. The features are clustered and binarized to obtain class agnostic masks for each object. These masks are then mapped to a textual class, using the CLIP model to support open-vocabulary. Finally, we add a refinement step that allows to obtain a more precise segmentation mask. Our approach (dubbed FreeSeg-Diff), which does not rely on any training, outperforms many training-based approaches on both Pascal VOC and COCO datasets. In addition, we show very competitive results compared to the recent weakly-supervised segmentation approaches. We provide comprehensive experiments showing the superiority of diffusion model features compared to other pretrained models. Project page: https://bcorrad.github.io/freesegdiff/
VidEdit: Zero-Shot and Spatially Aware Text-Driven Video Editing
Jun 14, 2023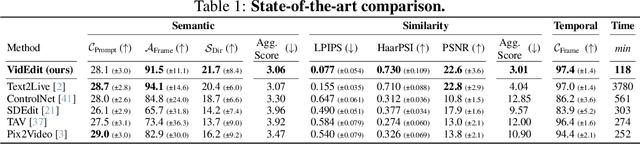
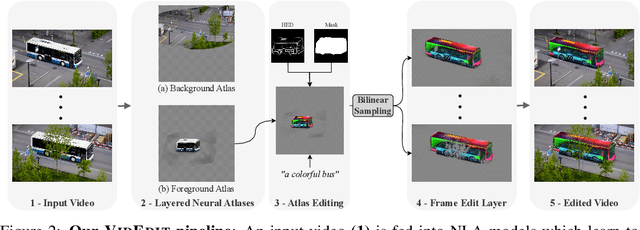
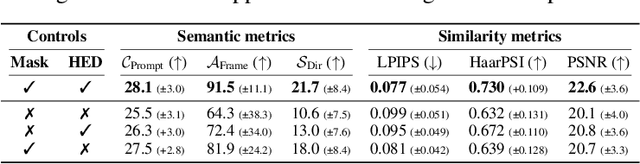
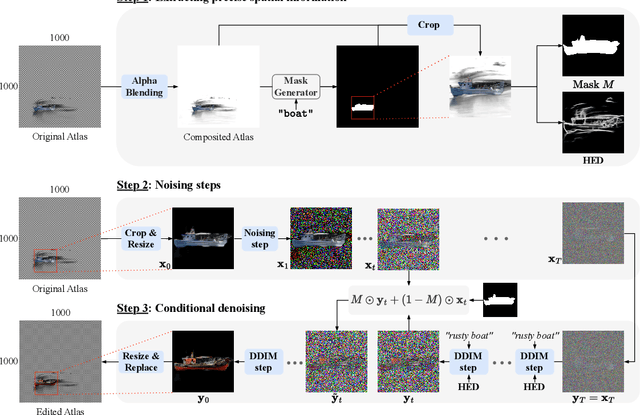
Recently, diffusion-based generative models have achieved remarkable success for image generation and edition. However, their use for video editing still faces important limitations. This paper introduces VidEdit, a novel method for zero-shot text-based video editing ensuring strong temporal and spatial consistency. Firstly, we propose to combine atlas-based and pre-trained text-to-image diffusion models to provide a training-free and efficient editing method, which by design fulfills temporal smoothness. Secondly, we leverage off-the-shelf panoptic segmenters along with edge detectors and adapt their use for conditioned diffusion-based atlas editing. This ensures a fine spatial control on targeted regions while strictly preserving the structure of the original video. Quantitative and qualitative experiments show that VidEdit outperforms state-of-the-art methods on DAVIS dataset, regarding semantic faithfulness, image preservation, and temporal consistency metrics. With this framework, processing a single video only takes approximately one minute, and it can generate multiple compatible edits based on a unique text prompt. Project web-page at https://videdit.github.io