 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Image Segmentation via Recursive Normalized Cut on Diffusion Features
Jun 05, 2024



Foundation models have emerged as powerful tools across various domains including language, vision, and multimodal tasks. While prior works have addressed unsupervised image segmentation, they significantly lag behind supervised models. In this paper, we use a diffusion UNet encoder as a foundation vision encoder and introduce DiffCut, an unsupervised zero-shot segmentation method that solely harnesses the output features from the final self-attention block. Through extensive experimentation, we demonstrate that the utilization of these diffusion features in a graph based segmentation algorithm, significantly outperforms previous state-of-the-art methods on zero-shot segmentation. Specifically, we leverage a recursive Normalized Cut algorithm that softly regulates the granularity of detected objects and produces well-defined segmentation maps that precisely capture intricate image details. Our work highlights the remarkably accurate semantic knowledge embedded within diffusion UNet encoders that could then serve as foundation vision encoders for downstream tasks. Project page at https://diffcut-segmentation.github.io
VidEdit: Zero-Shot and Spatially Aware Text-Driven Video Editing
Jun 14, 2023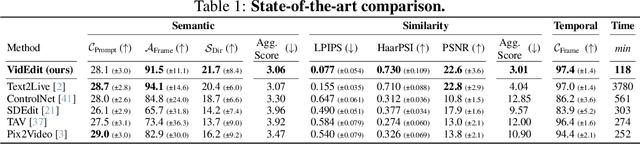
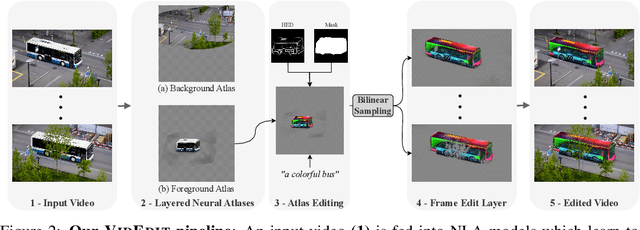
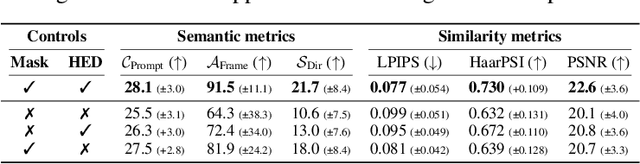
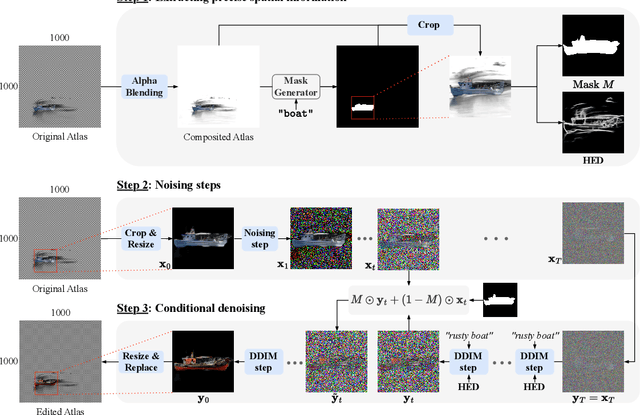
Recently, diffusion-based generative models have achieved remarkable success for image generation and edition. However, their use for video editing still faces important limitations. This paper introduces VidEdit, a novel method for zero-shot text-based video editing ensuring strong temporal and spatial consistency. Firstly, we propose to combine atlas-based and pre-trained text-to-image diffusion models to provide a training-free and efficient editing method, which by design fulfills temporal smoothness. Secondly, we leverage off-the-shelf panoptic segmenters along with edge detectors and adapt their use for conditioned diffusion-based atlas editing. This ensures a fine spatial control on targeted regions while strictly preserving the structure of the original video. Quantitative and qualitative experiments show that VidEdit outperforms state-of-the-art methods on DAVIS dataset, regarding semantic faithfulness, image preservation, and temporal consistency metrics. With this framework, processing a single video only takes approximately one minute, and it can generate multiple compatible edits based on a unique text prompt. Project web-page at https://videdit.github.io