 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAFTED: Decoupled Asymmetric Fusion of Tabular and Echocardiographic Data for Cardiac Hypertension Diagnosis
Sep 19, 2025Multimodal data fusion is a key approach for enhancing diagnosis in medical applications. We propose an asymmetric fusion strategy starting from a primary modality and integrating secondary modalities by disentangling shared and modality-specific information. Validated on a dataset of 239 patients with echocardiographic time series and tabular records, our model outperforms existing methods, achieving an AUC over 90%. This improvement marks a crucial benchmark for clinical use.
ViLU: Learning Vision-Language Uncertainties for Failure Prediction
Jul 10, 2025Reliable Uncertainty Quantification (UQ) and failure prediction remain open challenges for Vision-Language Models (VLMs). We introduce ViLU, a new Vision-Language Uncertainty quantification framework that contextualizes uncertainty estimates by leveraging all task-relevant textual representations. ViLU constructs an uncertainty-aware multi-modal representation by integrating the visual embedding, the predicted textual embedding, and an image-conditioned textual representation via cross-attention. Unlike traditional UQ methods based on loss prediction, ViLU trains an uncertainty predictor as a binary classifier to distinguish correct from incorrect predictions using a weighted binary cross-entropy loss, making it loss-agnostic. In particular, our proposed approach is well-suited for post-hoc settings, where only vision and text embeddings are available without direct access to the model itself. Extensive experiments on diverse datasets show the significant gains of our method compared to state-of-the-art failure prediction methods. We apply our method to standard classification datasets, such as ImageNet-1k, as well as large-scale image-caption datasets like CC12M and LAION-400M. Ablation studies highlight the critical role of our architecture and training in achieving effective uncertainty quantification. Our code is publicly available and can be found here: https://github.com/ykrmm/ViLU.
GalLoP: Learning Global and Local Prompts for Vision-Language Models
Jul 01, 2024



Prompt learning has been widely adopted to efficiently adapt vision-language models (VLMs), e.g. CLIP, for few-shot image classification. Despite their success, most prompt learning methods trade-off between classification accuracy and robustness, e.g. in domain generalization or out-of-distribution (OOD) detection. In this work, we introduce Global-Local Prompts (GalLoP), a new prompt learning method that learns multiple diverse prompts leveraging both global and local visual features. The training of the local prompts relies on local features with an enhanced vision-text alignment. To focus only on pertinent features, this local alignment is coupled with a sparsity strategy in the selection of the local features. We enforce diversity on the set of prompts using a new ``prompt dropout'' technique and a multiscale strategy on the local prompts. GalLoP outperforms previous prompt learning methods on accuracy on eleven datasets in different few shots settings and with various backbones. Furthermore, GalLoP shows strong robustness performances in both domain generalization and OOD detection, even outperforming dedicated OOD detection methods. Code and instructions to reproduce our results will be open-sourced.
Energy Correction Model in the Feature Space for Out-of-Distribution Detection
Mar 15, 2024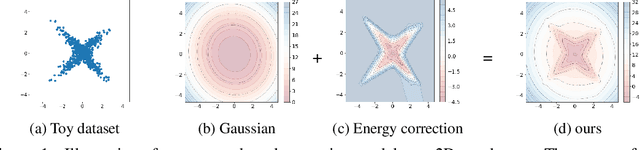

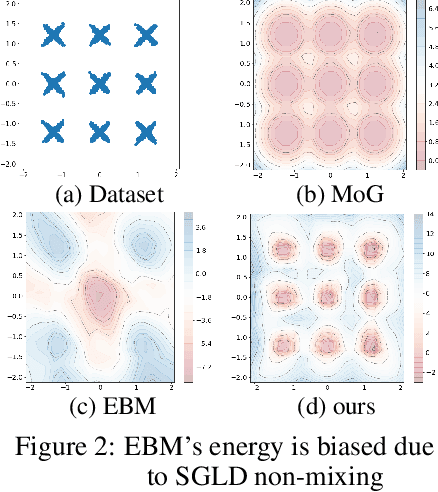

In this work, we study the out-of-distribution (OOD) detection problem through the use of the feature space of a pre-trained deep classifier. We show that learning the density of in-distribution (ID) features with an energy-based models (EBM) leads to competitive detection results. However, we found that the non-mixing of MCMC sampling during the EBM's training undermines its detection performance. To overcome this an energy-based correction of a mixture of class-conditional Gaussian distributions. We obtains favorable results when compared to a strong baseline like the KNN detector on the CIFAR-10/CIFAR-100 OOD detection benchmarks.
Optimization of Rank Losses for Image Retrieval
Sep 15, 2023In image retrieval, standard evaluation metrics rely on score ranking, \eg average precision (AP), recall at k (R@k), normalized discounted cumulative gain (NDCG). In this work we introduce a general framework for robust and decomposable rank losses optimization. It addresses two major challenges for end-to-end training of deep neural networks with rank losses: non-differentiability and non-decomposability. Firstly we propose a general surrogate for ranking operator, SupRank, that is amenable to stochastic gradient descent. It provides an upperbound for rank losses and ensures robust training. Secondly, we use a simple yet effective loss function to reduce the decomposability gap between the averaged batch approximation of ranking losses and their values on the whole training set. We apply our framework to two standard metrics for image retrieval: AP and R@k. Additionally we apply our framework to hierarchical image retrieval. We introduce an extension of AP, the hierarchical average precision $\mathcal{H}$-AP, and optimize it as well as the NDCG. Finally we create the first hierarchical landmarks retrieval dataset. We use a semi-automatic pipeline to create hierarchical labels, extending the large scale Google Landmarks v2 dataset. The hierarchical dataset is publicly available at https://github.com/cvdfoundation/google-landmark. Code will be released at https://github.com/elias-ramzi/SupRank.
Leveraging Vision-Language Foundation Models for Fine-Grained Downstream Tasks
Jul 13, 2023



Vision-language foundation models such as CLIP have shown impressive zero-shot performance on many tasks and datasets, especially thanks to their free-text inputs. However, they struggle to handle some downstream tasks, such as fine-grained attribute detection and localization. In this paper, we propose a multitask fine-tuning strategy based on a positive/negative prompt formulation to further leverage the capacities of the vision-language foundation models. Using the CLIP architecture as baseline, we show strong improvements on bird fine-grained attribute detection and localization tasks, while also increasing the classification performance on the CUB200-2011 dataset. We provide source code for reproducibility purposes: it is available at https://github.com/FactoDeepLearning/MultitaskVLFM.
VidEdit: Zero-Shot and Spatially Aware Text-Driven Video Editing
Jun 14, 2023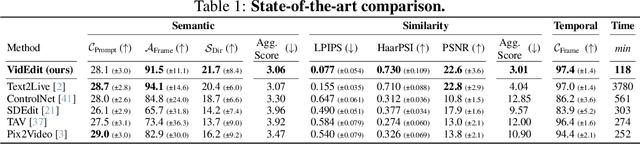
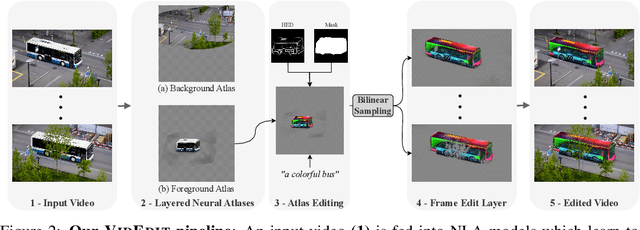
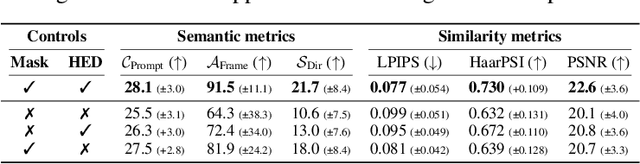
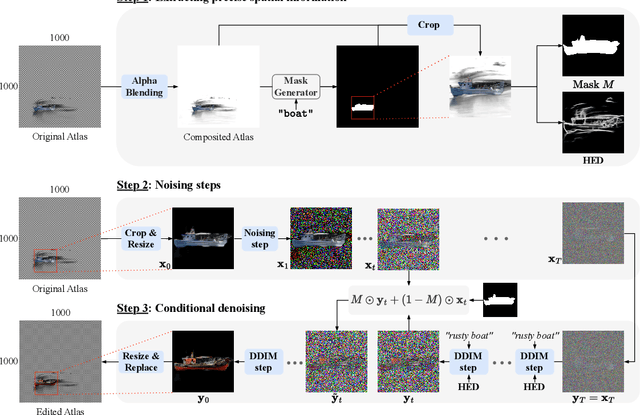
Recently, diffusion-based generative models have achieved remarkable success for image generation and edition. However, their use for video editing still faces important limitations. This paper introduces VidEdit, a novel method for zero-shot text-based video editing ensuring strong temporal and spatial consistency. Firstly, we propose to combine atlas-based and pre-trained text-to-image diffusion models to provide a training-free and efficient editing method, which by design fulfills temporal smoothness. Secondly, we leverage off-the-shelf panoptic segmenters along with edge detectors and adapt their use for conditioned diffusion-based atlas editing. This ensures a fine spatial control on targeted regions while strictly preserving the structure of the original video. Quantitative and qualitative experiments show that VidEdit outperforms state-of-the-art methods on DAVIS dataset, regarding semantic faithfulness, image preservation, and temporal consistency metrics. With this framework, processing a single video only takes approximately one minute, and it can generate multiple compatible edits based on a unique text prompt. Project web-page at https://videdit.github.io
Hybrid Energy Based Model in the Feature Space for Out-of-Distribution Detection
Jun 01, 2023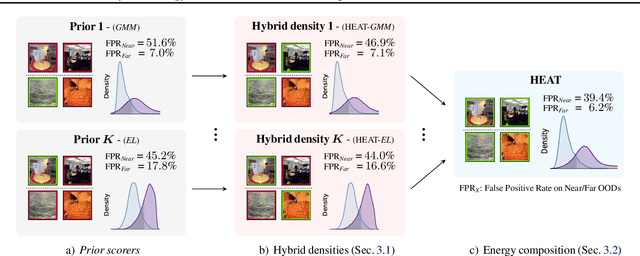


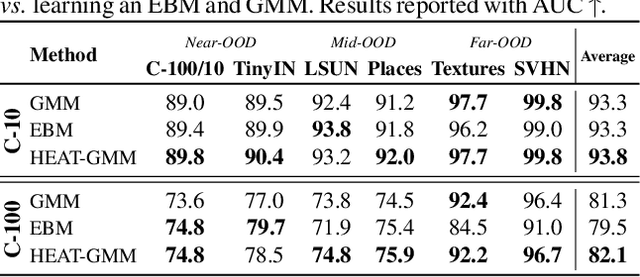
Out-of-distribution (OOD) detection is a critical requirement for the deployment of deep neural networks. This paper introduces the HEAT model, a new post-hoc OOD detection method estimating the density of in-distribution (ID) samples using hybrid energy-based models (EBM) in the feature space of a pre-trained backbone. HEAT complements prior density estimators of the ID density, e.g. parametric models like the Gaussian Mixture Model (GMM), to provide an accurate yet robust density estimation. A second contribution is to leverage the EBM framework to provide a unified density estimation and to compose several energy terms. Extensive experiments demonstrate the significance of the two contributions. HEAT sets new state-of-the-art OOD detection results on the CIFAR-10 / CIFAR-100 benchmark as well as on the large-scale Imagenet benchmark. The code is available at: https://github.com/MarcLafon/heatood.
Memory transformers for full context and high-resolution 3D Medical Segmentation
Oct 11, 2022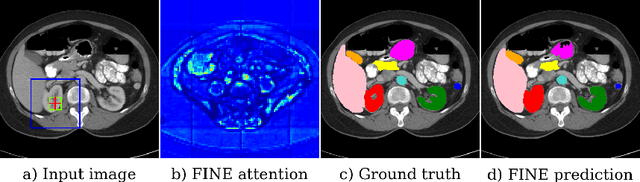
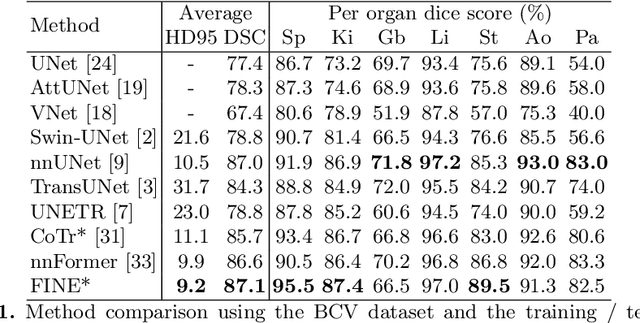
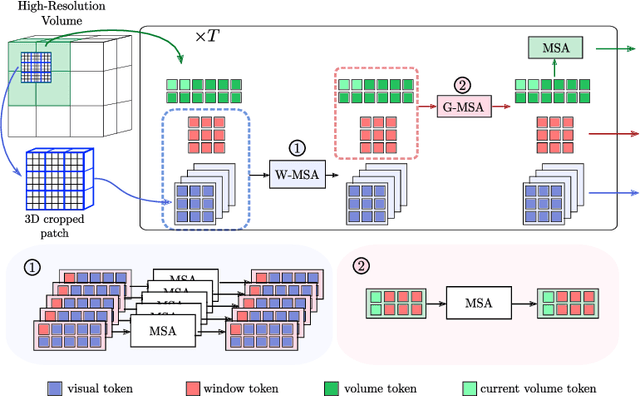

Transformer models achieve state-of-the-art results for image segmentation. However, achieving long-range attention, necessary to capture global context, with high-resolution 3D images is a fundamental challenge. This paper introduces the Full resolutIoN mEmory (FINE) transformer to overcome this issue. The core idea behind FINE is to learn memory tokens to indirectly model full range interactions while scaling well in both memory and computational costs. FINE introduces memory tokens at two levels: the first one allows full interaction between voxels within local image regions (patches), the second one allows full interactions between all regions of the 3D volume. Combined, they allow full attention over high resolution images, e.g. 512 x 512 x 256 voxels and above. Experiments on the BCV image segmentation dataset shows better performances than state-of-the-art CNN and transformer baselines, highlighting the superiority of our full attention mechanism compared to recent transformer baselines, e.g. CoTr, and nnFormer.
Complementing Brightness Constancy with Deep Networks for Optical Flow Prediction
Jul 12, 2022State-of-the-art methods for optical flow estimation rely on deep learning, which require complex sequential training schemes to reach optimal performances on real-world data. In this work, we introduce the COMBO deep network that explicitly exploits the brightness constancy (BC) model used in traditional methods. Since BC is an approximate physical model violated in several situations, we propose to train a physically-constrained network complemented with a data-driven network. We introduce a unique and meaningful flow decomposition between the physical prior and the data-driven complement, including an uncertainty quantification of the BC model. We derive a joint training scheme for learning the different components of the decomposition ensuring an optimal cooperation, in a supervised but also in a semi-supervised context. Experiments show that COMBO can improve performances over state-of-the-art supervised networks, e.g. RAFT, reaching state-of-the-art results on several benchmarks. We highlight how COMBO can leverage the BC model and adapt to its limitations. Finally, we show that our semi-supervised method can significantly simplify the training procedure.