 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgeons Awareness, Expectations, and Involvement with Artificial Intelligence: a Survey Pre and Post the GPT Era
Jun 09, 2025Artificial Intelligence (AI) is transforming medicine, with generative AI models like ChatGPT reshaping perceptions of its potential. This study examines surgeons' awareness, expectations, and involvement with AI in surgery through comparative surveys conducted in 2021 and 2024. Two cross-sectional surveys were distributed globally in 2021 and 2024, the first before an IRCAD webinar and the second during the annual EAES meeting. The surveys assessed demographics, AI awareness, expectations, involvement, and ethics (2024 only). The surveys collected a total of 671 responses from 98 countries, 522 in 2021 and 149 in 2024. Awareness of AI courses rose from 14.5% in 2021 to 44.6% in 2024, while course attendance increased from 12.9% to 23%. Despite this, familiarity with foundational AI concepts remained limited. Expectations for AI's role shifted in 2024, with hospital management gaining relevance. Ethical concerns gained prominence, with 87.2% of 2024 participants emphasizing accountability and transparency. Infrastructure limitations remained the primary obstacle to implementation. Interdisciplinary collaboration and structured training were identified as critical for successful AI adoption. Optimism about AI's transformative potential remained high, with 79.9% of respondents believing AI would positively impact surgery and 96.6% willing to integrate AI into their clinical practice. Surgeons' perceptions of AI are evolving, driven by the rise of generative AI and advancements in surgical data science. While enthusiasm for integration is strong, knowledge gaps and infrastructural challenges persist. Addressing these through education, ethical frameworks, and infrastructure development is essential.
TRUSTED: The Paired 3D Transabdominal Ultrasound and CT Human Data for Kidney Segmentation and Registration Research
Oct 19, 2023Inter-modal image registration (IMIR) and image segmentation with abdominal Ultrasound (US) data has many important clinical applications, including image-guided surgery, automatic organ measurement and robotic navigation. However, research is severely limited by the lack of public datasets. We propose TRUSTED (the Tridimensional Renal Ultra Sound TomodEnsitometrie Dataset), comprising paired transabdominal 3DUS and CT kidney images from 48 human patients (96 kidneys), including segmentation, and anatomical landmark annotations by two experienced radiographers. Inter-rater segmentation agreement was over 94 (Dice score), and gold-standard segmentations were generated using the STAPLE algorithm. Seven anatomical landmarks were annotated, important for IMIR systems development and evaluation. To validate the dataset's utility, 5 competitive Deep Learning models for automatic kidney segmentation were benchmarked, yielding average DICE scores from 83.2% to 89.1% for CT, and 61.9% to 79.4% for US images. Three IMIR methods were benchmarked, and Coherent Point Drift performed best with an average Target Registration Error of 4.53mm. The TRUSTED dataset may be used freely researchers to develop and validate new segmentation and IMIR methods.
Full Contextual Attention for Multi-resolution Transformers in Semantic Segmentation
Dec 15, 2022



Transformers have proved to be very effective for visual recognition tasks. In particular, vision transformers construct compressed global representations through self-attention and learnable class tokens. Multi-resolution transformers have shown recent successes in semantic segmentation but can only capture local interactions in high-resolution feature maps. This paper extends the notion of global tokens to build GLobal Attention Multi-resolution (GLAM) transformers. GLAM is a generic module that can be integrated into most existing transformer backbones. GLAM includes learnable global tokens, which unlike previous methods can model interactions between all image regions, and extracts powerful representations during training. Extensive experiments show that GLAM-Swin or GLAM-Swin-UNet exhibit substantially better performances than their vanilla counterparts on ADE20K and Cityscapes. Moreover, GLAM can be used to segment large 3D medical images, and GLAM-nnFormer achieves new state-of-the-art performance on the BCV dataset.
Memory transformers for full context and high-resolution 3D Medical Segmentation
Oct 11, 2022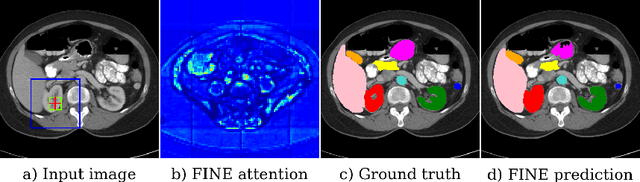
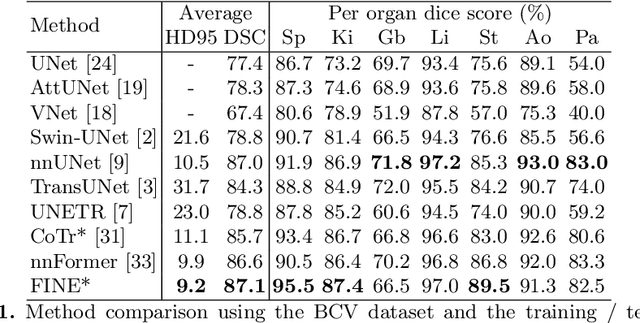
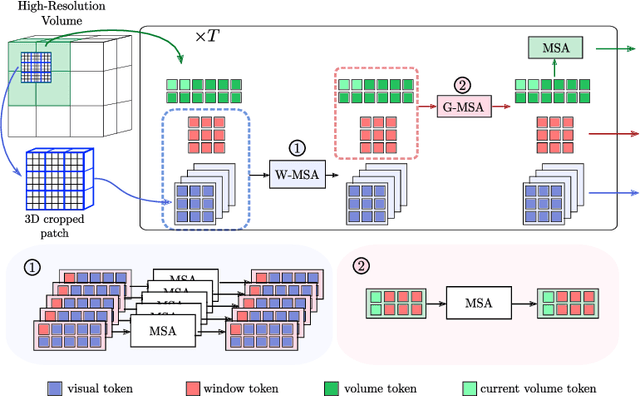

Transformer models achieve state-of-the-art results for image segmentation. However, achieving long-range attention, necessary to capture global context, with high-resolution 3D images is a fundamental challenge. This paper introduces the Full resolutIoN mEmory (FINE) transformer to overcome this issue. The core idea behind FINE is to learn memory tokens to indirectly model full range interactions while scaling well in both memory and computational costs. FINE introduces memory tokens at two levels: the first one allows full interaction between voxels within local image regions (patches), the second one allows full interactions between all regions of the 3D volume. Combined, they allow full attention over high resolution images, e.g. 512 x 512 x 256 voxels and above. Experiments on the BCV image segmentation dataset shows better performances than state-of-the-art CNN and transformer baselines, highlighting the superiority of our full attention mechanism compared to recent transformer baselines, e.g. CoTr, and nnFormer.
Surgical Data Science -- from Concepts to Clinical Translation
Oct 30, 2020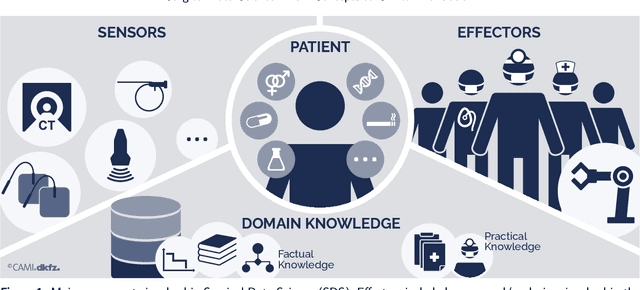
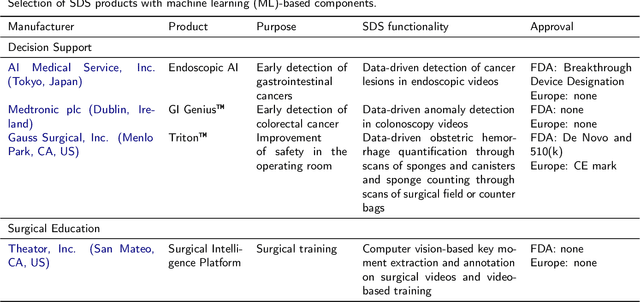
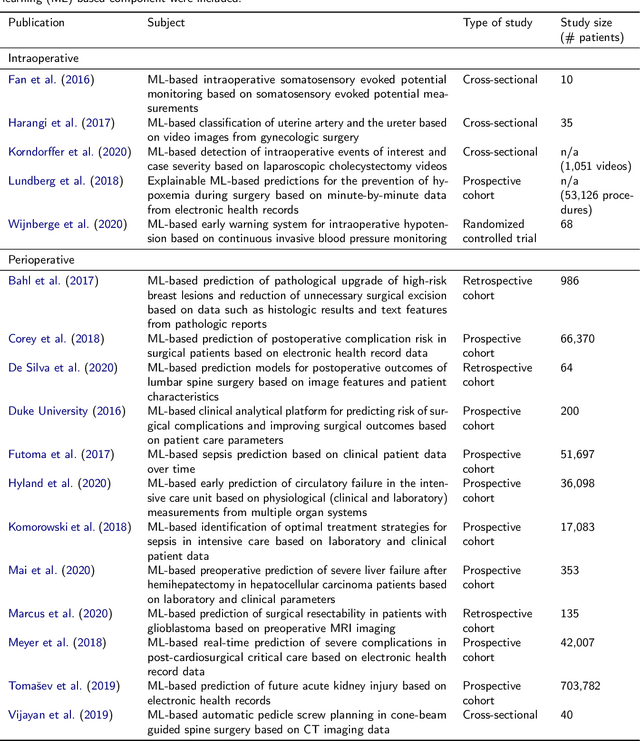
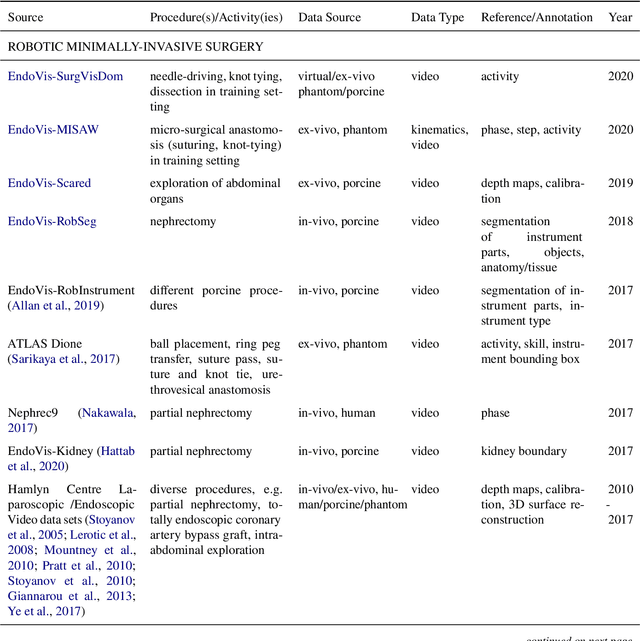
Recent developments in data science in general and machine learning in particular have transformed the way experts envision the future of surgery. Surgical data science is a new research field that aims to improve the quality of interventional healthcare through the capture, organization, analysis and modeling of data. While an increasing number of data-driven approaches and clinical applications have been studied in the fields of radiological and clinical data science, translational success stories are still lacking in surgery. In this publication, we shed light on the underlying reasons and provide a roadmap for future advances in the field. Based on an international workshop involving leading researchers in the field of surgical data science, we review current practice, key achievements and initiatives as well as available standards and tools for a number of topics relevant to the field, namely (1) technical infrastructure for data acquisition, storage and access in the presence of regulatory constraints, (2) data annotation and sharing and (3) data analytics. Drawing from this extensive review, we present current challenges for technology development and (4) describe a roadmap for faster clinical translation and exploitation of the full potential of surgical data science.
Deep Shape-from-Template: Wide-Baseline, Dense and Fast Registration and Deformable Reconstruction from a Single Image
Nov 27, 2018
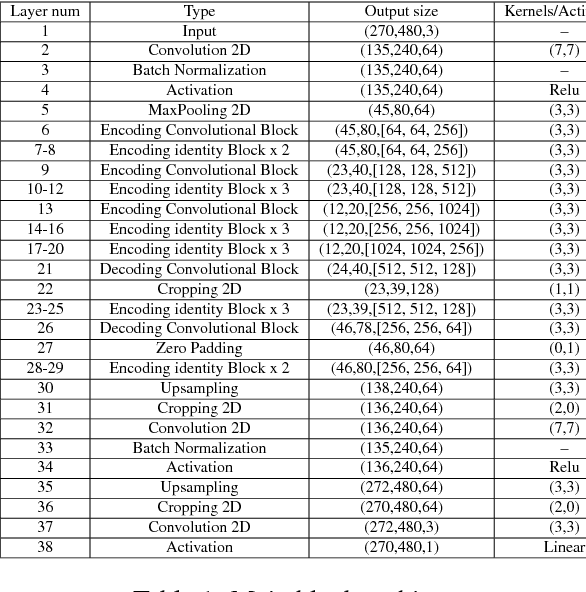

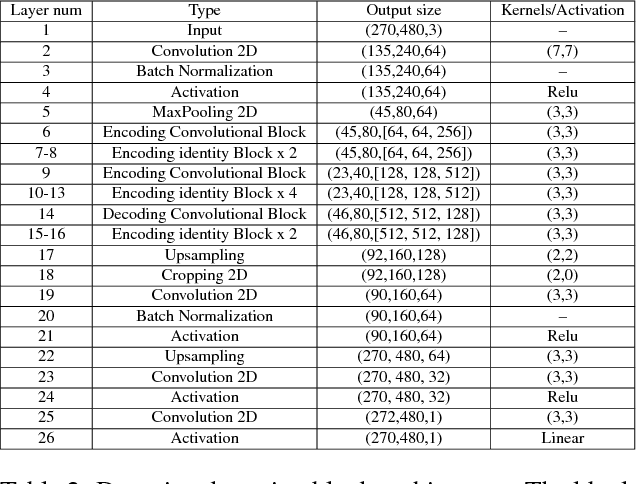
We present Deep Shape-from-Template (DeepSfT), a novel Deep Neural Network (DNN) method for solving real-time automatic registration and 3D reconstruction of a deformable object viewed in a single monocular image.DeepSfT advances the state-of-the-art in various aspects. Compared to existing DNN SfT methods, it is the first fully convolutional real-time approach that handles an arbitrary object geometry, topology and surface representation. It also does not require ground truth registration with real data and scales well to very complex object models with large numbers of elements. Compared to previous non-DNN SfT methods, it does not involve numerical optimization at run-time, and is a dense, wide-baseline solution that does not demand, and does not suffer from, feature-based matching. It is able to process a single image with significant deformation and viewpoint changes, and handles well the core challenges of occlusions, weak texture and blur. DeepSfT is based on residual encoder-decoder structures and refining blocks. It is trained end-to-end with a novel combination of supervised learning from simulated renderings of the object model and semi-supervised automatic fine-tuning using real data captured with a standard RGB-D camera. The cameras used for fine-tuning and run-time can be different, making DeepSfT practical for real-world use. We show that DeepSfT significantly outperforms state-of-the-art wide-baseline approaches for non-trivial templates, with quantitative and qualitative evaluation.
SLAM based Quasi Dense Reconstruction For Minimally Invasive Surgery Scenes
May 25, 2017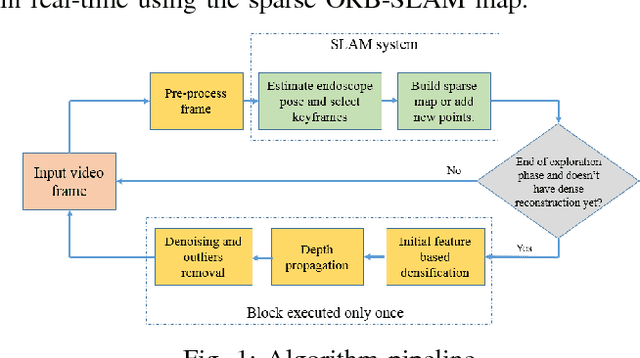
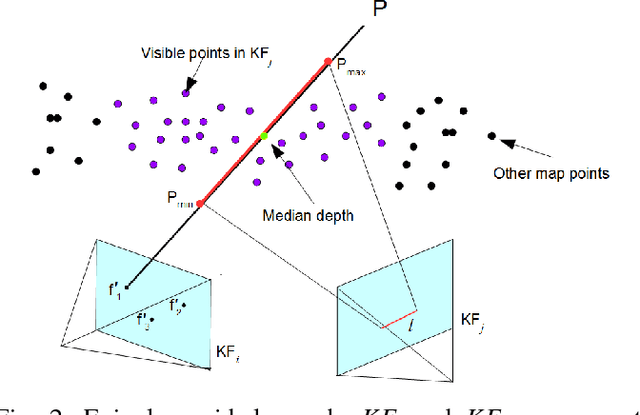
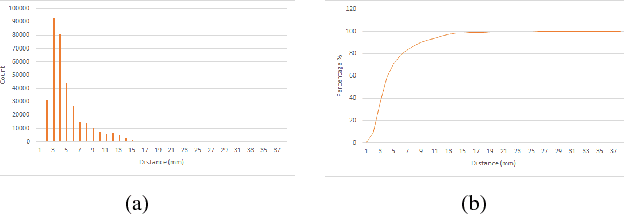
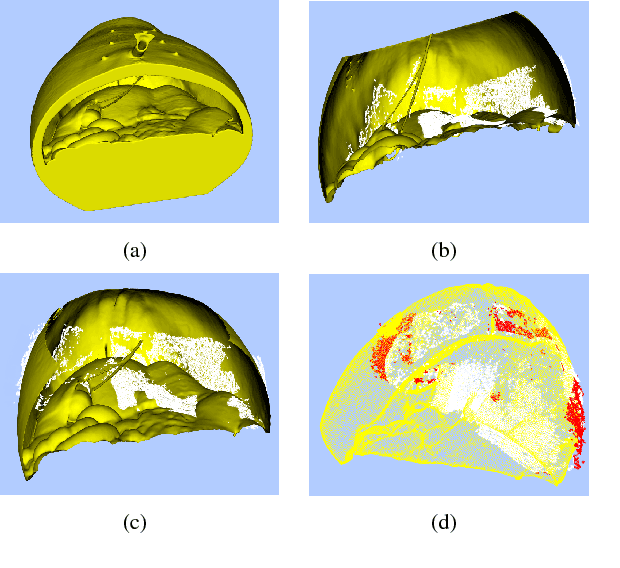
Recovering surgical scene structure in laparoscope surgery is crucial step for surgical guidance and augmented reality applications. In this paper, a quasi dense reconstruction algorithm of surgical scene is proposed. This is based on a state-of-the-art SLAM system, and is exploiting the initial exploration phase that is typically performed by the surgeon at the beginning of the surgery. We show how to convert the sparse SLAM map to a quasi dense scene reconstruction, using pairs of keyframe images and correlation-based featureless patch matching. We have validated the approach with a live porcine experiment using Computed Tomography as ground truth, yielding a Root Mean Squared Error of 4.9mm.