 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Shape-from-Template: Wide-Baseline, Dense and Fast Registration and Deformable Reconstruction from a Single Image
Paper and Code
Nov 27, 2018
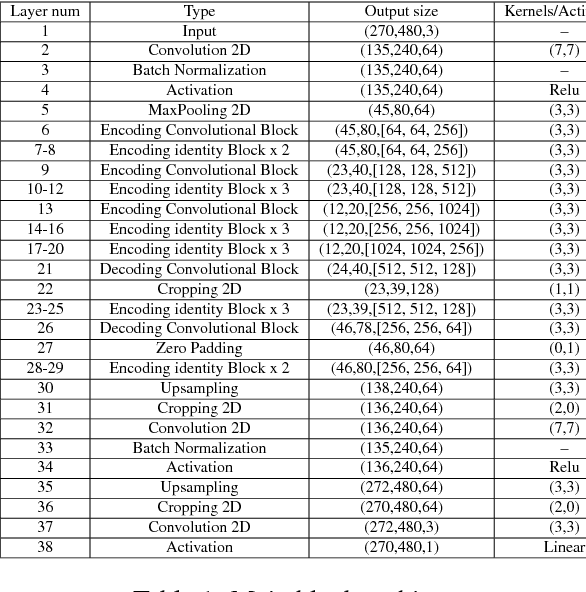

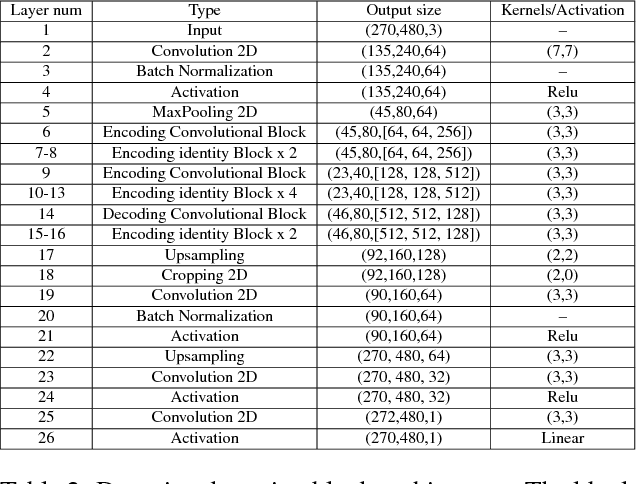
We present Deep Shape-from-Template (DeepSfT), a novel Deep Neural Network (DNN) method for solving real-time automatic registration and 3D reconstruction of a deformable object viewed in a single monocular image.DeepSfT advances the state-of-the-art in various aspects. Compared to existing DNN SfT methods, it is the first fully convolutional real-time approach that handles an arbitrary object geometry, topology and surface representation. It also does not require ground truth registration with real data and scales well to very complex object models with large numbers of elements. Compared to previous non-DNN SfT methods, it does not involve numerical optimization at run-time, and is a dense, wide-baseline solution that does not demand, and does not suffer from, feature-based matching. It is able to process a single image with significant deformation and viewpoint changes, and handles well the core challenges of occlusions, weak texture and blur. DeepSfT is based on residual encoder-decoder structures and refining blocks. It is trained end-to-end with a novel combination of supervised learning from simulated renderings of the object model and semi-supervised automatic fine-tuning using real data captured with a standard RGB-D camera. The cameras used for fine-tuning and run-time can be different, making DeepSfT practical for real-world use. We show that DeepSfT significantly outperforms state-of-the-art wide-baseline approaches for non-trivial templates, with quantitative and qualitative evaluation.