 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe OCR-PT-CT Project: Semi-Automatic Recognition of Ancient Egyptian Hieroglyphs Based on Metric Learning
Dec 30, 2025Digital humanities are significantly transforming how Egyptologists study ancient Egyptian texts. The OCR-PT-CT project proposes a recognition method for hieroglyphs based on images of Coffin Texts (CT) from Adriaan de Buck (1935-1961) and Pyramid Texts (PT) from Middle Kingdom coffins (James Allen, 2006). The system identifies hieroglyphs and transcribes them into Gardiner's codes. A web tool organizes them by spells and witnesses, storing the data in CSV format for integration with the MORTEXVAR dataset, which collects Coffin Texts with metadata, transliterations, and translations for research. Recognition has been addressed in two ways: a Mobilenet neural network trained on 140 hieroglyph classes achieved 93.87 \% accuracy but struggled with underrepresented classes. A novel Deep Metric Learning approach improves flexibility for new or data-limited signs, achieving 97.70 \% accuracy and recognizing more hieroglyphs. Due to its superior performance under class imbalance and adaptability, the final system adopts Deep Metric Learning as the default classifier.
Towards Dense People Detection with Deep Learning and Depth images
Jul 14, 2020
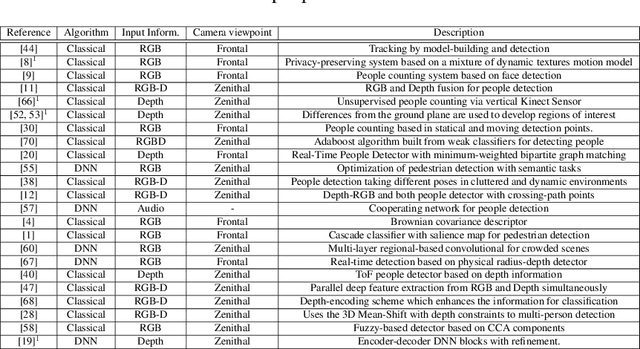

This paper proposes a DNN-based system that detects multiple people from a single depth image. Our neural network processes a depth image and outputs a likelihood map in image coordinates, where each detection corresponds to a Gaussian-shaped local distribution, centered at the person's head. The likelihood map encodes both the number of detected people and their 2D image positions, and can be used to recover the 3D position of each person using the depth image and the camera calibration parameters. Our architecture is compact, using separated convolutions to increase performance, and runs in real-time with low budget GPUs. We use simulated data for initially training the network, followed by fine tuning with a relatively small amount of real data. We show this strategy to be effective, producing networks that generalize to work with scenes different from those used during training. We thoroughly compare our method against the existing state-of-the-art, including both classical and DNN-based solutions. Our method outperforms existing methods and can accurately detect people in scenes with significant occlusions.
Exploiting the ConvLSTM: Human Action Recognition using Raw Depth Video-Based Recurrent Neural Networks
Jun 13, 2020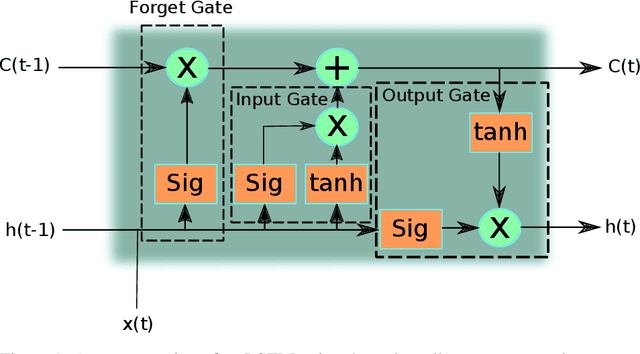


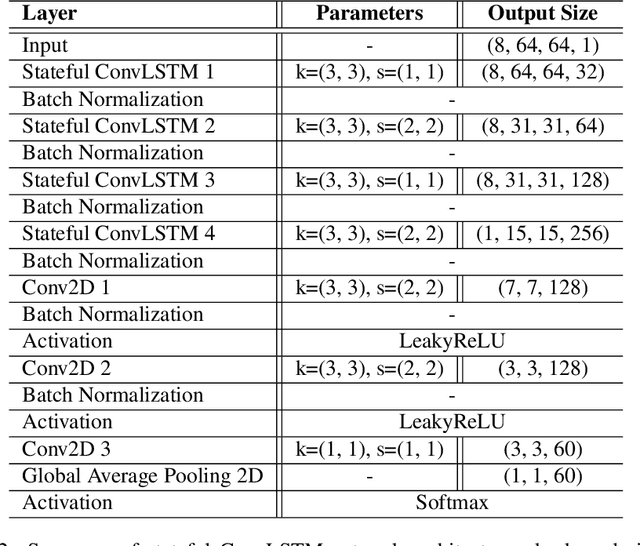
As in many other different fields, deep learning has become the main approach in most computer vision applications, such as scene understanding, object recognition, computer-human interaction or human action recognition (HAR). Research efforts within HAR have mainly focused on how to efficiently extract and process both spatial and temporal dependencies of video sequences. In this paper, we propose and compare, two neural networks based on the convolutional long short-term memory unit, namely ConvLSTM, with differences in the architecture and the long-term learning strategy. The former uses a video-length adaptive input data generator (\emph{stateless}) whereas the latter explores the \emph{stateful} ability of general recurrent neural networks but applied in the particular case of HAR. This stateful property allows the model to accumulate discriminative patterns from previous frames without compromising computer memory. Experimental results on the large-scale NTU RGB+D dataset show that the proposed models achieve competitive recognition accuracies with lower computational cost compared with state-of-the-art methods and prove that, in the particular case of videos, the rarely-used stateful mode of recurrent neural networks significantly improves the accuracy obtained with the standard mode. The recognition accuracies obtained are 75.26\% (CS) and 75.45\% (CV) for the stateless model, with an average time consumption per video of 0.21 s, and 80.43\% (CS) and 79.91\%(CV) with 0.89 s for the stateful version.
3DFCNN: Real-Time Action Recognition using 3D Deep Neural Networks with Raw Depth Information
Jun 13, 2020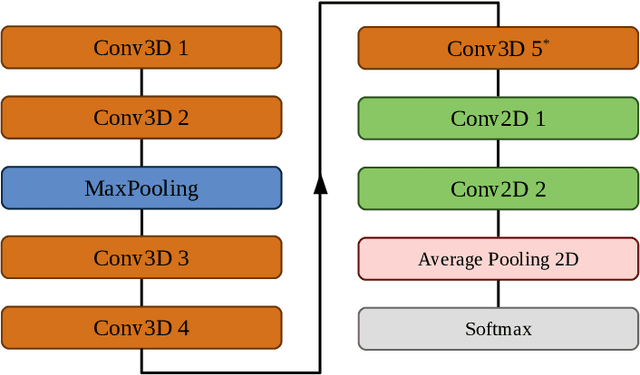
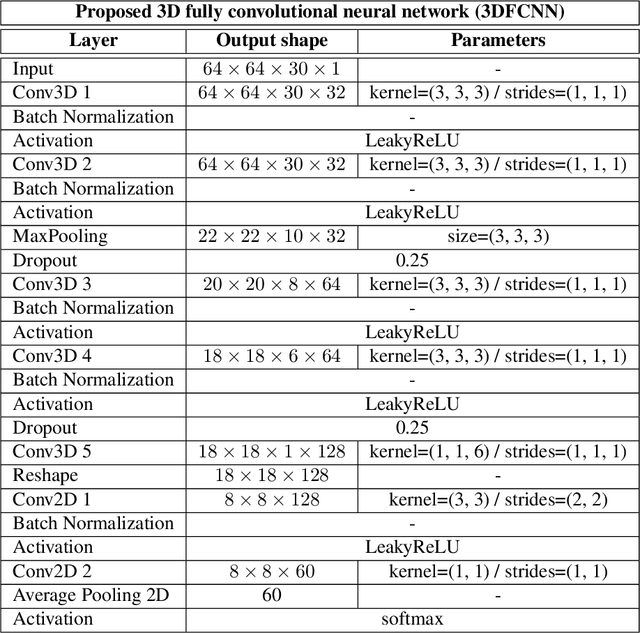
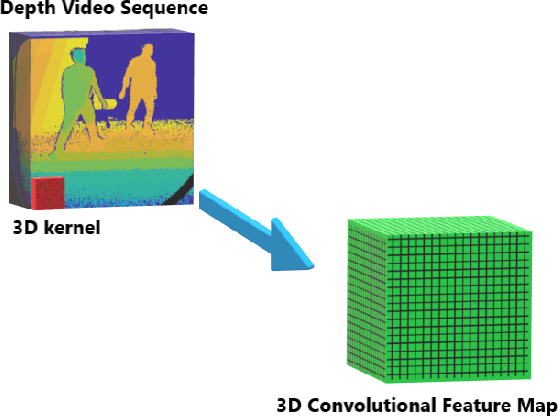

Human actions recognition is a fundamental task in artificial vision, that has earned a great importance in recent years due to its multiple applications in different areas. %, such as the study of human behavior, security or video surveillance. In this context, this paper describes an approach for real-time human action recognition from raw depth image-sequences, provided by an RGB-D camera. The proposal is based on a 3D fully convolutional neural network, named 3DFCNN, which automatically encodes spatio-temporal patterns from depth sequences without %any costly pre-processing. Furthermore, the described 3D-CNN allows %automatic features extraction and actions classification from the spatial and temporal encoded information of depth sequences. The use of depth data ensures that action recognition is carried out protecting people's privacy% allows recognizing the actions carried out by people, protecting their privacy%\sout{of them} , since their identities can not be recognized from these data. %\st{ from depth images.} 3DFCNN has been evaluated and its results compared to those from other state-of-the-art methods within three widely used %large-scale NTU RGB+D datasets, with different characteristics (resolution, sensor type, number of views, camera location, etc.). The obtained results allows validating the proposal, concluding that it outperforms several state-of-the-art approaches based on classical computer vision techniques. Furthermore, it achieves action recognition accuracy comparable to deep learning based state-of-the-art methods with a lower computational cost, which allows its use in real-time applications.
DPDnet: A Robust People Detector using Deep Learning with an Overhead Depth Camera
Jun 01, 2020



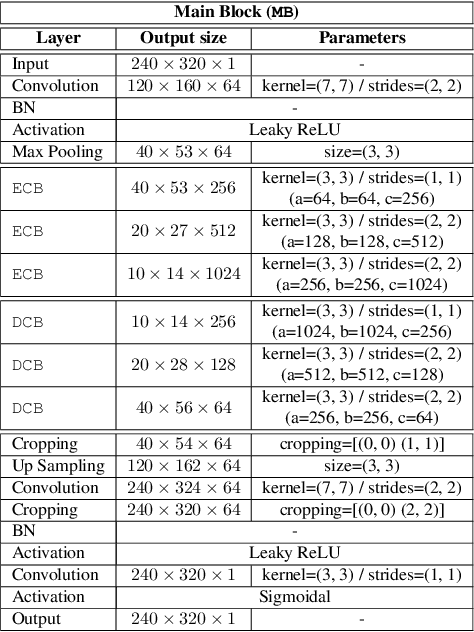
In this paper we propose a method based on deep learning that detects multiple people from a single overhead depth image with high reliability. Our neural network, called DPDnet, is based on two fully-convolutional encoder-decoder neural blocks based on residual layers. The Main Block takes a depth image as input and generates a pixel-wise confidence map, where each detected person in the image is represented by a Gaussian-like distribution. The refinement block combines the depth image and the output from the main block, to refine the confidence map. Both blocks are simultaneously trained end-to-end using depth images and head position labels. The experimental work shows that DPDNet outperforms state-of-the-art methods, with accuracies greater than 99% in three different publicly available datasets, without retraining not fine-tuning. In addition, the computational complexity of our proposal is independent of the number of people in the scene and runs in real time using conventional GPUs.
Deep Shape-from-Template: Wide-Baseline, Dense and Fast Registration and Deformable Reconstruction from a Single Image
Nov 27, 2018
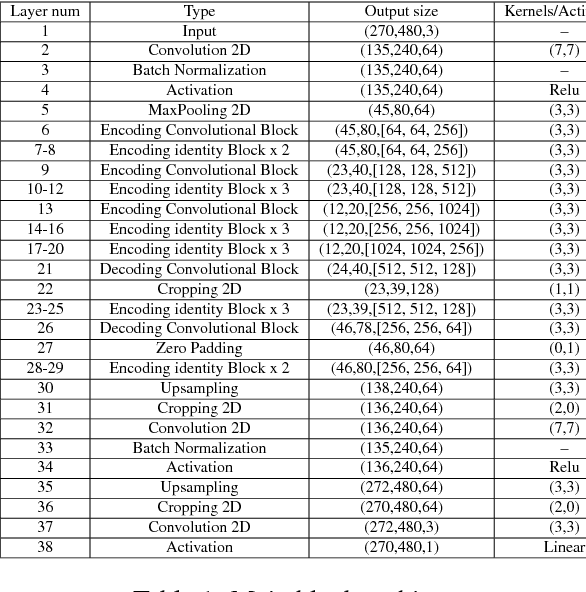

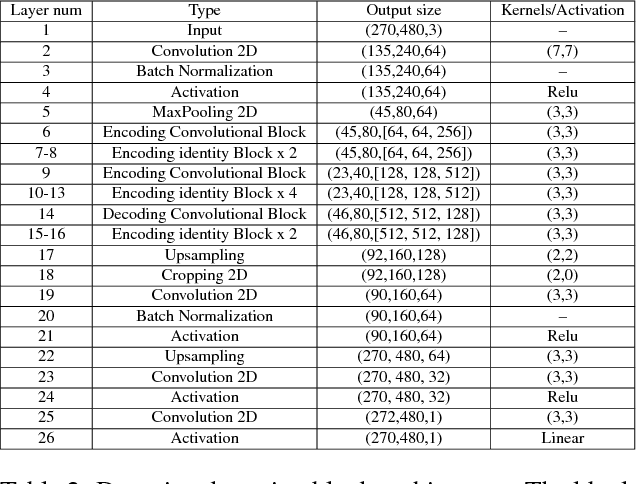
We present Deep Shape-from-Template (DeepSfT), a novel Deep Neural Network (DNN) method for solving real-time automatic registration and 3D reconstruction of a deformable object viewed in a single monocular image.DeepSfT advances the state-of-the-art in various aspects. Compared to existing DNN SfT methods, it is the first fully convolutional real-time approach that handles an arbitrary object geometry, topology and surface representation. It also does not require ground truth registration with real data and scales well to very complex object models with large numbers of elements. Compared to previous non-DNN SfT methods, it does not involve numerical optimization at run-time, and is a dense, wide-baseline solution that does not demand, and does not suffer from, feature-based matching. It is able to process a single image with significant deformation and viewpoint changes, and handles well the core challenges of occlusions, weak texture and blur. DeepSfT is based on residual encoder-decoder structures and refining blocks. It is trained end-to-end with a novel combination of supervised learning from simulated renderings of the object model and semi-supervised automatic fine-tuning using real data captured with a standard RGB-D camera. The cameras used for fine-tuning and run-time can be different, making DeepSfT practical for real-world use. We show that DeepSfT significantly outperforms state-of-the-art wide-baseline approaches for non-trivial templates, with quantitative and qualitative evaluation.