 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting the ConvLSTM: Human Action Recognition using Raw Depth Video-Based Recurrent Neural Networks
Jun 13, 2020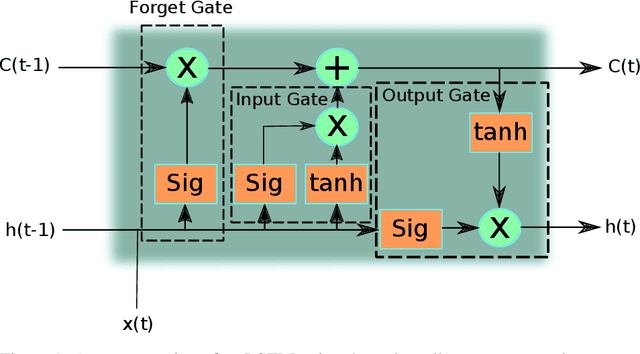


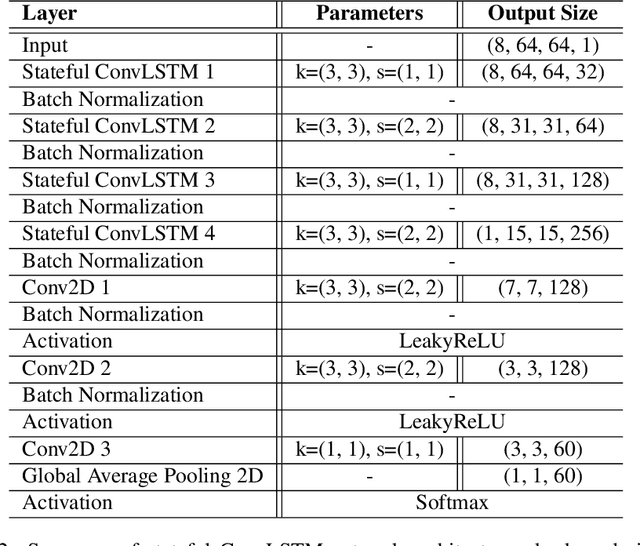
As in many other different fields, deep learning has become the main approach in most computer vision applications, such as scene understanding, object recognition, computer-human interaction or human action recognition (HAR). Research efforts within HAR have mainly focused on how to efficiently extract and process both spatial and temporal dependencies of video sequences. In this paper, we propose and compare, two neural networks based on the convolutional long short-term memory unit, namely ConvLSTM, with differences in the architecture and the long-term learning strategy. The former uses a video-length adaptive input data generator (\emph{stateless}) whereas the latter explores the \emph{stateful} ability of general recurrent neural networks but applied in the particular case of HAR. This stateful property allows the model to accumulate discriminative patterns from previous frames without compromising computer memory. Experimental results on the large-scale NTU RGB+D dataset show that the proposed models achieve competitive recognition accuracies with lower computational cost compared with state-of-the-art methods and prove that, in the particular case of videos, the rarely-used stateful mode of recurrent neural networks significantly improves the accuracy obtained with the standard mode. The recognition accuracies obtained are 75.26\% (CS) and 75.45\% (CV) for the stateless model, with an average time consumption per video of 0.21 s, and 80.43\% (CS) and 79.91\%(CV) with 0.89 s for the stateful version.
3DFCNN: Real-Time Action Recognition using 3D Deep Neural Networks with Raw Depth Information
Jun 13, 2020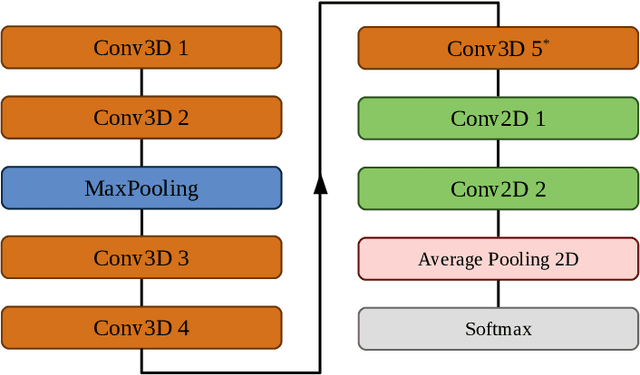
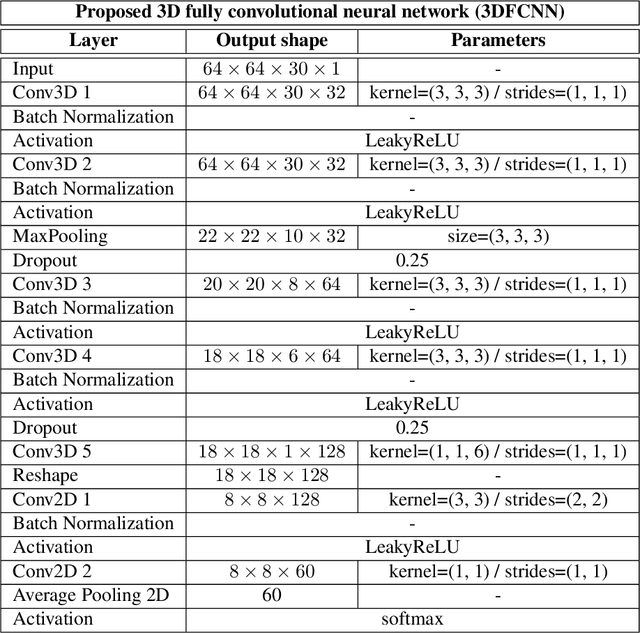

Human actions recognition is a fundamental task in artificial vision, that has earned a great importance in recent years due to its multiple applications in different areas. %, such as the study of human behavior, security or video surveillance. In this context, this paper describes an approach for real-time human action recognition from raw depth image-sequences, provided by an RGB-D camera. The proposal is based on a 3D fully convolutional neural network, named 3DFCNN, which automatically encodes spatio-temporal patterns from depth sequences without %any costly pre-processing. Furthermore, the described 3D-CNN allows %automatic features extraction and actions classification from the spatial and temporal encoded information of depth sequences. The use of depth data ensures that action recognition is carried out protecting people's privacy% allows recognizing the actions carried out by people, protecting their privacy%\sout{of them} , since their identities can not be recognized from these data. %\st{ from depth images.} 3DFCNN has been evaluated and its results compared to those from other state-of-the-art methods within three widely used %large-scale NTU RGB+D datasets, with different characteristics (resolution, sensor type, number of views, camera location, etc.). The obtained results allows validating the proposal, concluding that it outperforms several state-of-the-art approaches based on classical computer vision techniques. Furthermore, it achieves action recognition accuracy comparable to deep learning based state-of-the-art methods with a lower computational cost, which allows its use in real-time applications.