 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multi-algorithm approach for operational human resources workload balancing in a last mile urban delivery system
Dec 24, 2025Efficient workload assignment to the workforce is critical in last-mile package delivery systems. In this context, traditional methods of assigning package deliveries to workers based on geographical proximity can be inefficient and surely guide to an unbalanced workload distribution among delivery workers. In this paper, we look at the problem of operational human resources workload balancing in last-mile urban package delivery systems. The idea is to consider the effort workload to optimize the system, i.e., the optimization process is now focused on improving the delivery time, so that the workload balancing is complete among all the staff. This process should correct significant decompensations in workload among delivery workers in a given zone. Specifically, we propose a multi-algorithm approach to tackle this problem. The proposed approach takes as input a set of delivery points and a defined number of workers, and then assigns packages to workers, in such a way that it ensures that each worker completes a similar amount of work per day. The proposed algorithms use a combination of distance and workload considerations to optimize the allocation of packages to workers. In this sense, the distance between the delivery points and the location of each worker is also taken into account. The proposed multi-algorithm methodology includes different versions of k-means, evolutionary approaches, recursive assignments based on k-means initialization with different problem encodings, and a hybrid evolutionary ensemble algorithm. We have illustrated the performance of the proposed approach in a real-world problem in an urban last-mile package delivery workforce operating at Azuqueca de Henares, Spain.
CoSeNet: A Novel Approach for Optimal Segmentation of Correlation Matrices
Dec 24, 2025In this paper, we propose a novel approach for the optimal identification of correlated segments in noisy correlation matrices. The proposed model is known as CoSeNet (Correlation Seg-mentation Network) and is based on a four-layer algorithmic architecture that includes several processing layers: input, formatting, re-scaling, and segmentation layer. The proposed model can effectively identify correlated segments in such matrices, better than previous approaches for similar problems. Internally, the proposed model utilizes an overlapping technique and uses pre-trained Machine Learning (ML) algorithms, which makes it robust and generalizable. CoSeNet approach also includes a method that optimizes the parameters of the re-scaling layer using a heuristic algorithm and fitness based on a Window Difference-based metric. The output of the model is a binary noise-free matrix representing optimal segmentation as well as its seg-mentation points and can be used in a variety of applications, obtaining compromise solutions between efficiency, memory, and speed of the proposed deployment model.
Randomization-based Machine Learning in Renewable Energy Prediction Problems: Critical Literature Review, New Results and Perspectives
Mar 26, 2021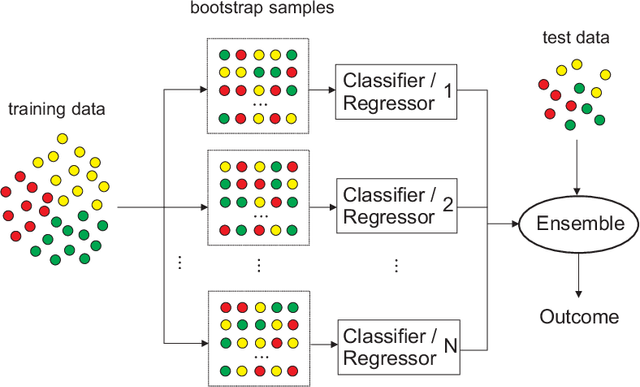
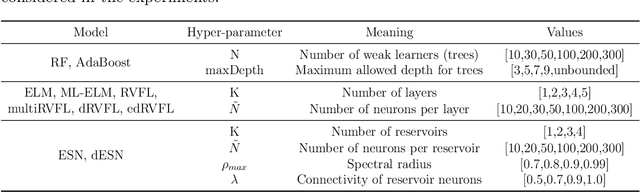
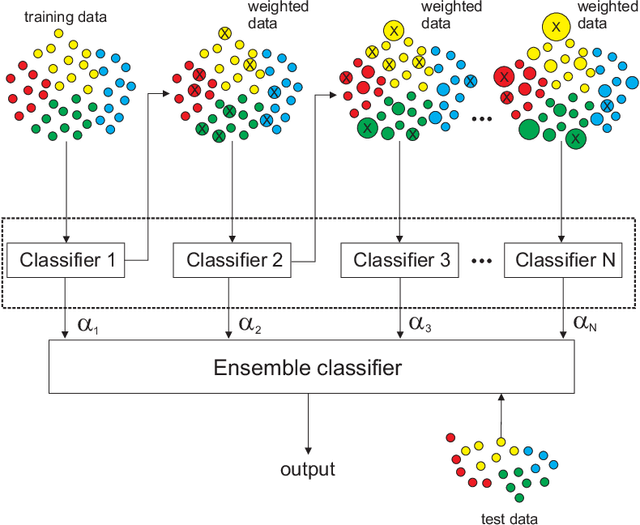

Randomization-based Machine Learning methods for prediction are currently a hot topic in Artificial Intelligence, due to their excellent performance in many prediction problems, with a bounded computation time. The application of randomization-based approaches to renewable energy prediction problems has been massive in the last few years, including many different types of randomization-based approaches, their hybridization with other techniques and also the description of new versions of classical randomization-based algorithms, including deep and ensemble approaches. In this paper we review the most important characteristics of randomization-based machine learning approaches and their application to renewable energy prediction problems. We describe the most important methods and algorithms of this family of modeling methods, and perform a critical literature review, examining prediction problems related to solar, wind, marine/ocean and hydro-power renewable sources. We support our critical analysis with an extensive experimental study, comprising real-world problems related to solar, wind and hydro-power energy, where randomization-based algorithms are found to achieve superior results at a significantly lower computational cost than other modeling counterparts. We end our survey with a prospect of the most important challenges and research directions that remain open this field, along with an outlook motivating further research efforts in this exciting research field.
Towards Dense People Detection with Deep Learning and Depth images
Jul 14, 2020
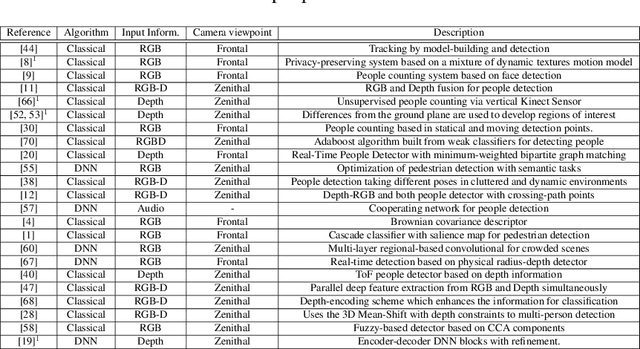

This paper proposes a DNN-based system that detects multiple people from a single depth image. Our neural network processes a depth image and outputs a likelihood map in image coordinates, where each detection corresponds to a Gaussian-shaped local distribution, centered at the person's head. The likelihood map encodes both the number of detected people and their 2D image positions, and can be used to recover the 3D position of each person using the depth image and the camera calibration parameters. Our architecture is compact, using separated convolutions to increase performance, and runs in real-time with low budget GPUs. We use simulated data for initially training the network, followed by fine tuning with a relatively small amount of real data. We show this strategy to be effective, producing networks that generalize to work with scenes different from those used during training. We thoroughly compare our method against the existing state-of-the-art, including both classical and DNN-based solutions. Our method outperforms existing methods and can accurately detect people in scenes with significant occlusions.
3DFCNN: Real-Time Action Recognition using 3D Deep Neural Networks with Raw Depth Information
Jun 13, 2020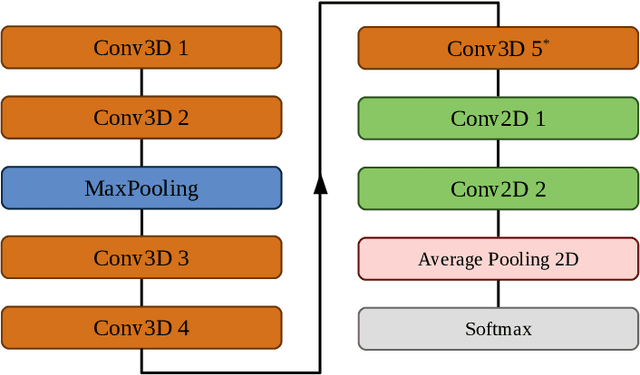
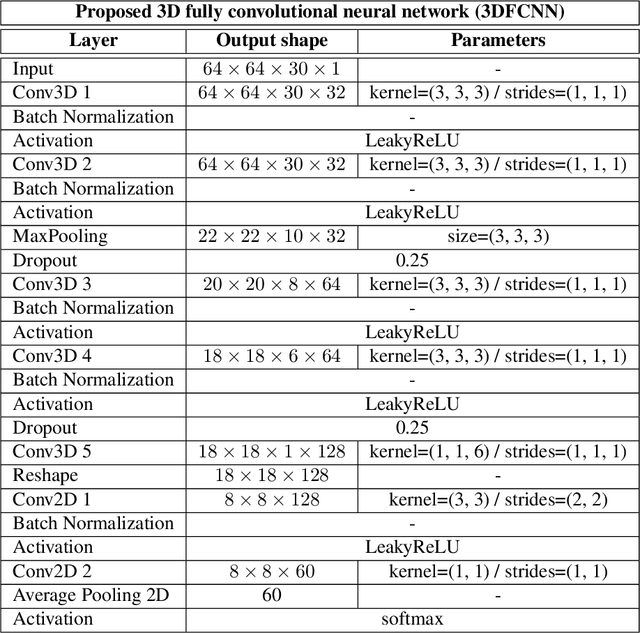
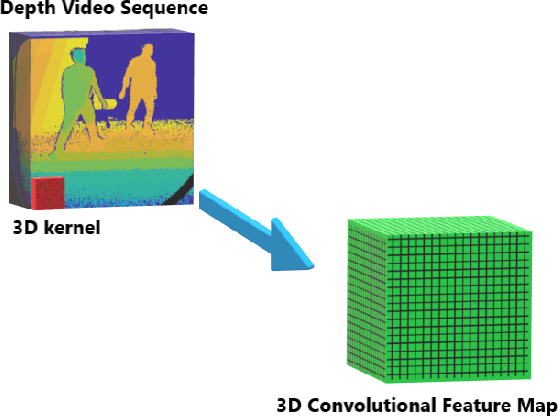

Human actions recognition is a fundamental task in artificial vision, that has earned a great importance in recent years due to its multiple applications in different areas. %, such as the study of human behavior, security or video surveillance. In this context, this paper describes an approach for real-time human action recognition from raw depth image-sequences, provided by an RGB-D camera. The proposal is based on a 3D fully convolutional neural network, named 3DFCNN, which automatically encodes spatio-temporal patterns from depth sequences without %any costly pre-processing. Furthermore, the described 3D-CNN allows %automatic features extraction and actions classification from the spatial and temporal encoded information of depth sequences. The use of depth data ensures that action recognition is carried out protecting people's privacy% allows recognizing the actions carried out by people, protecting their privacy%\sout{of them} , since their identities can not be recognized from these data. %\st{ from depth images.} 3DFCNN has been evaluated and its results compared to those from other state-of-the-art methods within three widely used %large-scale NTU RGB+D datasets, with different characteristics (resolution, sensor type, number of views, camera location, etc.). The obtained results allows validating the proposal, concluding that it outperforms several state-of-the-art approaches based on classical computer vision techniques. Furthermore, it achieves action recognition accuracy comparable to deep learning based state-of-the-art methods with a lower computational cost, which allows its use in real-time applications.
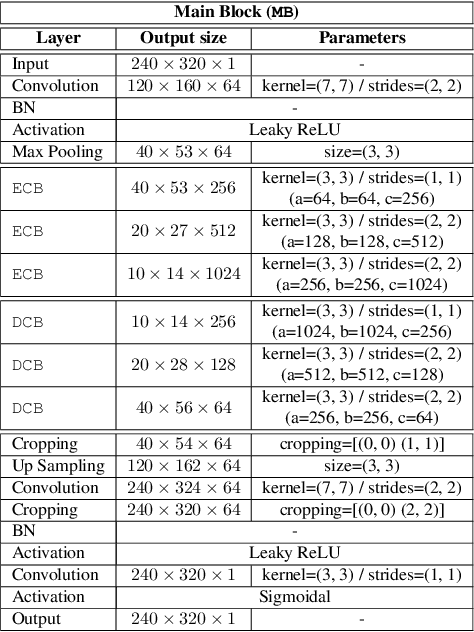
DPDnet: A Robust People Detector using Deep Learning with an Overhead Depth Camera
Jun 01, 2020



In this paper we propose a method based on deep learning that detects multiple people from a single overhead depth image with high reliability. Our neural network, called DPDnet, is based on two fully-convolutional encoder-decoder neural blocks based on residual layers. The Main Block takes a depth image as input and generates a pixel-wise confidence map, where each detected person in the image is represented by a Gaussian-like distribution. The refinement block combines the depth image and the output from the main block, to refine the confidence map. Both blocks are simultaneously trained end-to-end using depth images and head position labels. The experimental work shows that DPDNet outperforms state-of-the-art methods, with accuracies greater than 99% in three different publicly available datasets, without retraining not fine-tuning. In addition, the computational complexity of our proposal is independent of the number of people in the scene and runs in real time using conventional GPUs.
Deep Shape-from-Template: Wide-Baseline, Dense and Fast Registration and Deformable Reconstruction from a Single Image
Nov 27, 2018
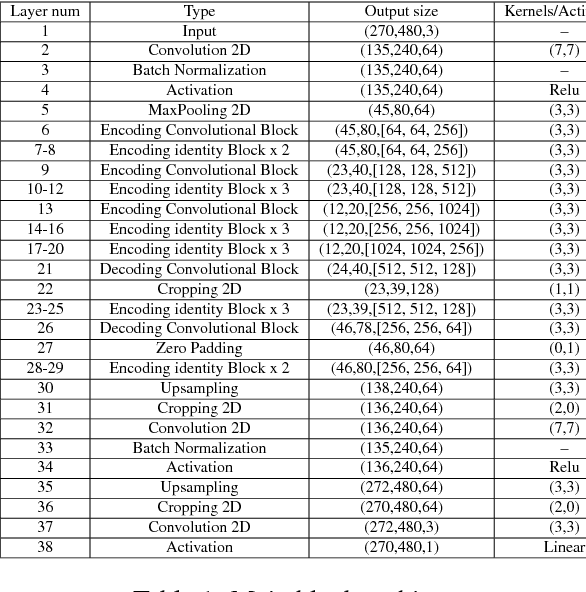

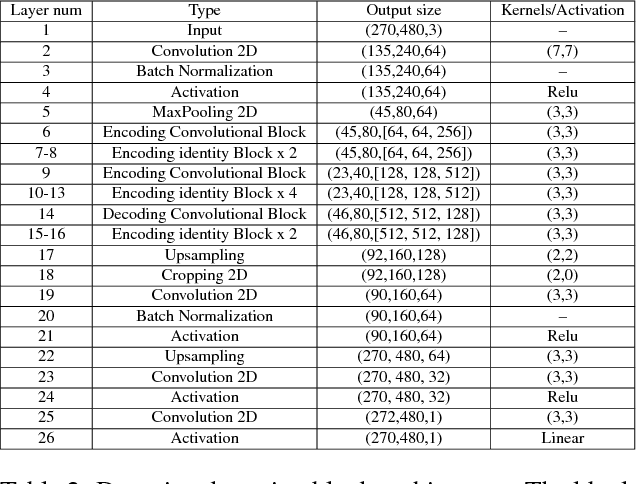
We present Deep Shape-from-Template (DeepSfT), a novel Deep Neural Network (DNN) method for solving real-time automatic registration and 3D reconstruction of a deformable object viewed in a single monocular image.DeepSfT advances the state-of-the-art in various aspects. Compared to existing DNN SfT methods, it is the first fully convolutional real-time approach that handles an arbitrary object geometry, topology and surface representation. It also does not require ground truth registration with real data and scales well to very complex object models with large numbers of elements. Compared to previous non-DNN SfT methods, it does not involve numerical optimization at run-time, and is a dense, wide-baseline solution that does not demand, and does not suffer from, feature-based matching. It is able to process a single image with significant deformation and viewpoint changes, and handles well the core challenges of occlusions, weak texture and blur. DeepSfT is based on residual encoder-decoder structures and refining blocks. It is trained end-to-end with a novel combination of supervised learning from simulated renderings of the object model and semi-supervised automatic fine-tuning using real data captured with a standard RGB-D camera. The cameras used for fine-tuning and run-time can be different, making DeepSfT practical for real-world use. We show that DeepSfT significantly outperforms state-of-the-art wide-baseline approaches for non-trivial templates, with quantitative and qualitative evaluation.
Solutions of Quadratic First-Order ODEs applied to Computer Vision Problems
Jun 27, 2018



This article is a study about the existence and the uniqueness of solutions of a specific quadratic first-order ODE that frequently appears in multiple reconstruction problems. It is called the \emph{planar-perspective equation} due to the duality with the geometric problem of reconstruction of planar-perspective curves from their modulus. Solutions of the \emph{planar-perspective equation} are related with planar curves parametrized with perspective parametrization due to this geometric interpretation. The article proves the existence of only two local solutions to the \emph{initial value problem} with \emph{regular initial conditions} and a maximum of two analytic solutions with \emph{critical initial conditions}. The article also gives theorems to extend the local definition domain where the existence of both solutions are guaranteed. It introduces the \emph{maximal depth function} as a function that upper-bound all possible solutions of the \emph{planar-perspective equation} and contains all its possible \emph{critical points}. Finally, the article describes the \emph{maximal-depth solution problem} that consists of finding the solution of the referred equation that has maximum the depth and proves its uniqueness. It is an important problem as it does not need initial conditions to obtain the unique solution and its the frequent solution that practical algorithms of the state-of-the-art give.