 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Dense People Detection with Deep Learning and Depth images
Jul 14, 2020

This paper proposes a DNN-based system that detects multiple people from a single depth image. Our neural network processes a depth image and outputs a likelihood map in image coordinates, where each detection corresponds to a Gaussian-shaped local distribution, centered at the person's head. The likelihood map encodes both the number of detected people and their 2D image positions, and can be used to recover the 3D position of each person using the depth image and the camera calibration parameters. Our architecture is compact, using separated convolutions to increase performance, and runs in real-time with low budget GPUs. We use simulated data for initially training the network, followed by fine tuning with a relatively small amount of real data. We show this strategy to be effective, producing networks that generalize to work with scenes different from those used during training. We thoroughly compare our method against the existing state-of-the-art, including both classical and DNN-based solutions. Our method outperforms existing methods and can accurately detect people in scenes with significant occlusions.
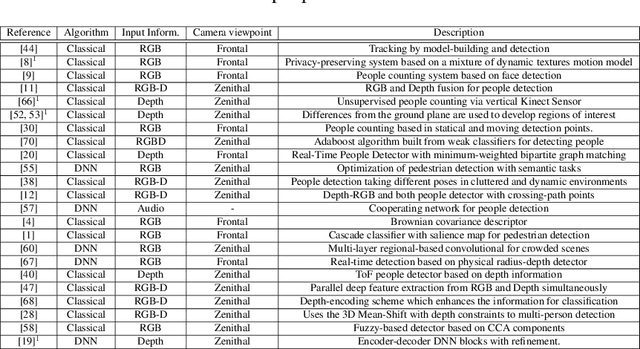
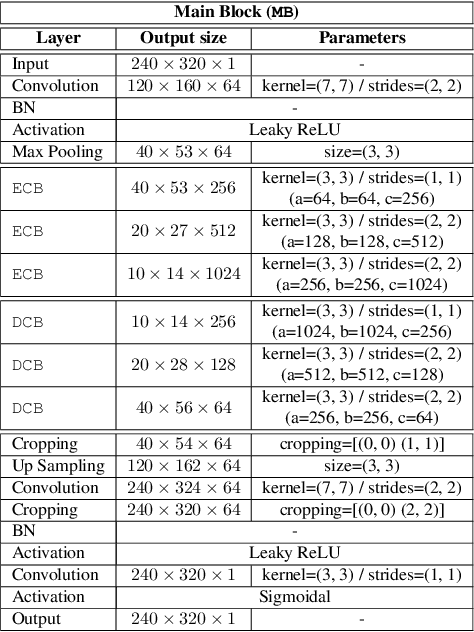
DPDnet: A Robust People Detector using Deep Learning with an Overhead Depth Camera
Jun 01, 2020



In this paper we propose a method based on deep learning that detects multiple people from a single overhead depth image with high reliability. Our neural network, called DPDnet, is based on two fully-convolutional encoder-decoder neural blocks based on residual layers. The Main Block takes a depth image as input and generates a pixel-wise confidence map, where each detected person in the image is represented by a Gaussian-like distribution. The refinement block combines the depth image and the output from the main block, to refine the confidence map. Both blocks are simultaneously trained end-to-end using depth images and head position labels. The experimental work shows that DPDNet outperforms state-of-the-art methods, with accuracies greater than 99% in three different publicly available datasets, without retraining not fine-tuning. In addition, the computational complexity of our proposal is independent of the number of people in the scene and runs in real time using conventional GPUs.