 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Design Framework for operationalizing Trustworthy Artificial Intelligence in Healthcare: Requirements, Tradeoffs and Challenges for its Clinical Adoption
Apr 27, 2025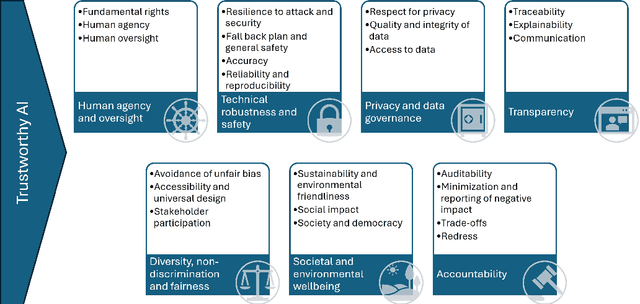



Artificial Intelligence (AI) holds great promise for transforming healthcare, particularly in disease diagnosis, prognosis, and patient care. The increasing availability of digital medical data, such as images, omics, biosignals, and electronic health records, combined with advances in computing, has enabled AI models to approach expert-level performance. However, widespread clinical adoption remains limited, primarily due to challenges beyond technical performance, including ethical concerns, regulatory barriers, and lack of trust. To address these issues, AI systems must align with the principles of Trustworthy AI (TAI), which emphasize human agency and oversight, algorithmic robustness, privacy and data governance, transparency, bias and discrimination avoidance, and accountability. Yet, the complexity of healthcare processes (e.g., screening, diagnosis, prognosis, and treatment) and the diversity of stakeholders (clinicians, patients, providers, regulators) complicate the integration of TAI principles. To bridge the gap between TAI theory and practical implementation, this paper proposes a design framework to support developers in embedding TAI principles into medical AI systems. Thus, for each stakeholder identified across various healthcare processes, we propose a disease-agnostic collection of requirements that medical AI systems should incorporate to adhere to the principles of TAI. Additionally, we examine the challenges and tradeoffs that may arise when applying these principles in practice. To ground the discussion, we focus on cardiovascular diseases, a field marked by both high prevalence and active AI innovation, and demonstrate how TAI principles have been applied and where key obstacles persist.
AiGAS-dEVL-RC: An Adaptive Growing Neural Gas Model for Recurrently Drifting Unsupervised Data Streams
Apr 10, 2025

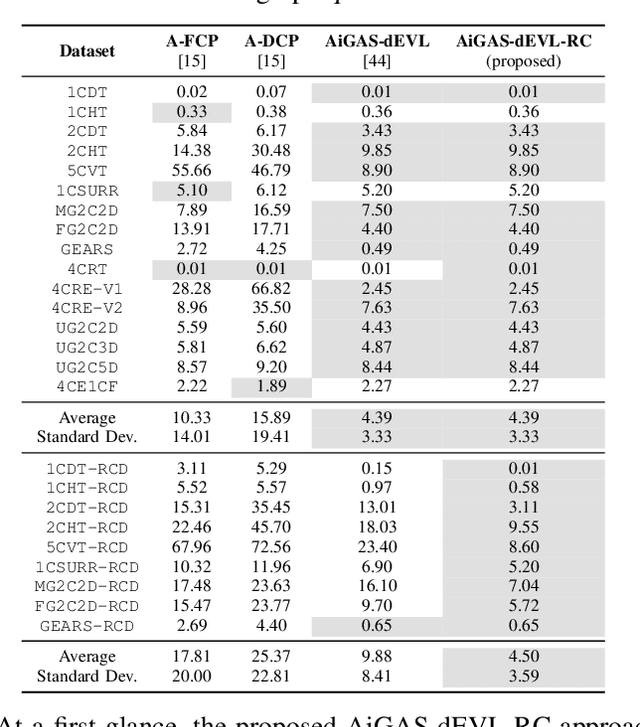

Concept drift and extreme verification latency pose significant challenges in data stream learning, particularly when dealing with recurring concept changes in dynamic environments. This work introduces a novel method based on the Growing Neural Gas (GNG) algorithm, designed to effectively handle abrupt recurrent drifts while adapting to incrementally evolving data distributions (incremental drifts). Leveraging the self-organizing and topological adaptability of GNG, the proposed approach maintains a compact yet informative memory structure, allowing it to efficiently store and retrieve knowledge of past or recurring concepts, even under conditions of delayed or sparse stream supervision. Our experiments highlight the superiority of our approach over existing data stream learning methods designed to cope with incremental non-stationarities and verification latency, demonstrating its ability to quickly adapt to new drifts, robustly manage recurring patterns, and maintain high predictive accuracy with a minimal memory footprint. Unlike other techniques that fail to leverage recurring knowledge, our proposed approach is proven to be a robust and efficient online learning solution for unsupervised drifting data flows.
World Models in Artificial Intelligence: Sensing, Learning, and Reasoning Like a Child
Mar 19, 2025World Models help Artificial Intelligence (AI) predict outcomes, reason about its environment, and guide decision-making. While widely used in reinforcement learning, they lack the structured, adaptive representations that even young children intuitively develop. Advancing beyond pattern recognition requires dynamic, interpretable frameworks inspired by Piaget's cognitive development theory. We highlight six key research areas -- physics-informed learning, neurosymbolic learning, continual learning, causal inference, human-in-the-loop AI, and responsible AI -- as essential for enabling true reasoning in AI. By integrating statistical learning with advances in these areas, AI can evolve from pattern recognition to genuine understanding, adaptation and reasoning capabilities.
The Paradox of Success in Evolutionary and Bioinspired Optimization: Revisiting Critical Issues, Key Studies, and Methodological Pathways
Jan 13, 2025
Evolutionary and bioinspired computation are crucial for efficiently addressing complex optimization problems across diverse application domains. By mimicking processes observed in nature, like evolution itself, these algorithms offer innovative solutions beyond the reach of traditional optimization methods. They excel at finding near-optimal solutions in large, complex search spaces, making them invaluable in numerous fields. However, both areas are plagued by challenges at their core, including inadequate benchmarking, problem-specific overfitting, insufficient theoretical grounding, and superfluous proposals justified only by their biological metaphor. This overview recapitulates and analyzes in depth the criticisms concerning the lack of innovation and rigor in experimental studies within the field. To this end, we examine the judgmental positions of the existing literature in an informed attempt to guide the research community toward directions of solid contribution and advancement in these areas. We summarize guidelines for the design of evolutionary and bioinspired optimizers, the development of experimental comparisons, and the derivation of novel proposals that take a step further in the field. We provide a brief note on automating the process of creating these algorithms, which may help align metaheuristic optimization research with its primary objective (solving real-world problems), provided that our identified pathways are followed. Our conclusions underscore the need for a sustained push towards innovation and the enforcement of methodological rigor in prospective studies to fully realize the potential of these advanced computational techniques.
Can transformative AI shape a new age for our civilization?: Navigating between speculation and reality
Dec 11, 2024Artificial Intelligence is widely regarded as a transformative force with the potential to redefine numerous sectors of human civilization. While Artificial Intelligence has evolved from speculative fiction to a pivotal element of technological progress, its role as a truly transformative agent, or transformative Artificial Intelligence, remains a subject of debate. This work explores the historical precedents of technological breakthroughs, examining whether Artificial Intelligence can achieve a comparable impact, and it delves into various ethical frameworks that shape the perception and development of Artificial Intelligence. Additionally, it considers the societal, technical, and regulatory challenges that must be addressed for Artificial Intelligence to become a catalyst for global change. We also examine not only the strategies and methodologies that could lead to transformative Artificial Intelligence but also the barriers that could ultimately make these goals unattainable. We end with a critical inquiry into whether reaching a transformative Artificial Intelligence might compel humanity to adopt an entirely new ethical approach, tailored to the complexities of advanced Artificial Intelligence. By addressing the ethical, social, and scientific dimensions of Artificial Intelligence's development, this work contributes to the broader discourse on the long-term implications of Artificial Intelligence and its capacity to drive civilization toward a new era of progress or, conversely, exacerbate existing inequalities and risks.
On the Inherent Robustness of One-Stage Object Detection against Out-of-Distribution Data
Nov 07, 2024



Robustness is a fundamental aspect for developing safe and trustworthy models, particularly when they are deployed in the open world. In this work we analyze the inherent capability of one-stage object detectors to robustly operate in the presence of out-of-distribution (OoD) data. Specifically, we propose a novel detection algorithm for detecting unknown objects in image data, which leverages the features extracted by the model from each sample. Differently from other recent approaches in the literature, our proposal does not require retraining the object detector, thereby allowing for the use of pretrained models. Our proposed OoD detector exploits the application of supervised dimensionality reduction techniques to mitigate the effects of the curse of dimensionality on the features extracted by the model. Furthermore, it utilizes high-resolution feature maps to identify potential unknown objects in an unsupervised fashion. Our experiments analyze the Pareto trade-off between the performance detecting known and unknown objects resulting from different algorithmic configurations and inference confidence thresholds. We also compare the performance of our proposed algorithm to that of logits-based post-hoc OoD methods, as well as possible fusion strategies. Finally, we discuss on the competitiveness of all tested methods against state-of-the-art OoD approaches for object detection models over the recently published Unknown Object Detection benchmark. The obtained results verify that the performance of avant-garde post-hoc OoD detectors can be further improved when combined with our proposed algorithm.
A Collaborative Content Moderation Framework for Toxicity Detection based on Conformalized Estimates of Annotation Disagreement
Nov 07, 2024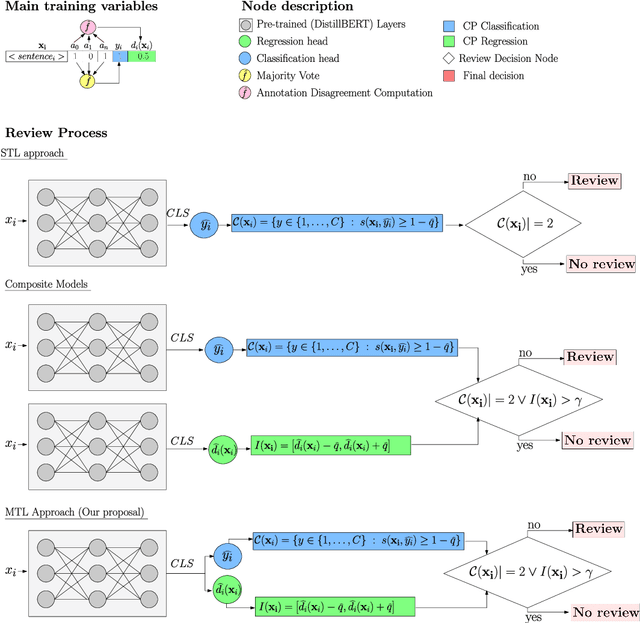
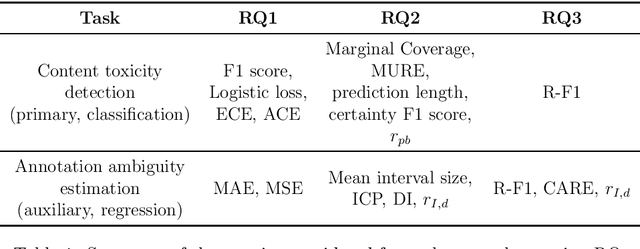
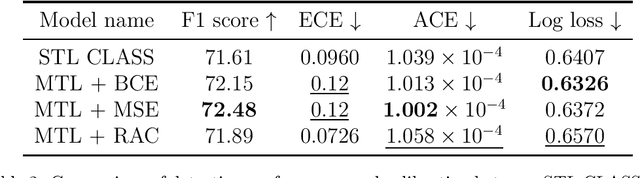
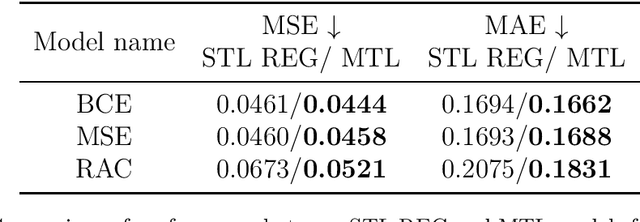
Content moderation typically combines the efforts of human moderators and machine learning models. However, these systems often rely on data where significant disagreement occurs during moderation, reflecting the subjective nature of toxicity perception. Rather than dismissing this disagreement as noise, we interpret it as a valuable signal that highlights the inherent ambiguity of the content,an insight missed when only the majority label is considered. In this work, we introduce a novel content moderation framework that emphasizes the importance of capturing annotation disagreement. Our approach uses multitask learning, where toxicity classification serves as the primary task and annotation disagreement is addressed as an auxiliary task. Additionally, we leverage uncertainty estimation techniques, specifically Conformal Prediction, to account for both the ambiguity in comment annotations and the model's inherent uncertainty in predicting toxicity and disagreement.The framework also allows moderators to adjust thresholds for annotation disagreement, offering flexibility in determining when ambiguity should trigger a review. We demonstrate that our joint approach enhances model performance, calibration, and uncertainty estimation, while offering greater parameter efficiency and improving the review process in comparison to single-task methods.
A Machine Learning Approach for the Efficient Estimation of Ground-Level Air Temperature in Urban Areas
Nov 05, 2024

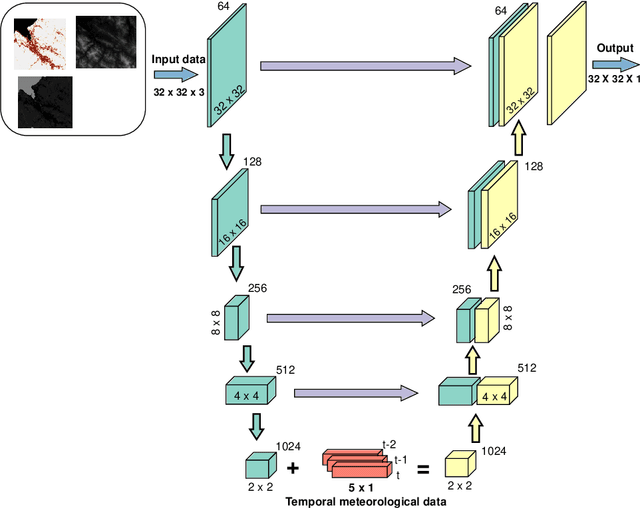

The increasingly populated cities of the 21st Century face the challenge of being sustainable and resilient spaces for their inhabitants. However, climate change, among other problems, makes these objectives difficult to achieve. The Urban Heat Island (UHI) phenomenon that occurs in cities, increasing their thermal stress, is one of the stumbling blocks to achieve a more sustainable city. The ability to estimate temperatures with a high degree of accuracy allows for the identification of the highest priority areas in cities where urban improvements need to be made to reduce thermal discomfort. In this work we explore the usefulness of image-to-image deep neural networks (DNNs) for correlating spatial and meteorological variables of a urban area with street-level air temperature. The air temperature at street-level is estimated both spatially and temporally for a specific use case, and compared with existing, well-established numerical models. Based on the obtained results, deep neural networks are confirmed to be faster and less computationally expensive alternative for ground-level air temperature compared to numerical models.
Resilience to the Flowing Unknown: an Open Set Recognition Framework for Data Streams
Oct 31, 2024Modern digital applications extensively integrate Artificial Intelligence models into their core systems, offering significant advantages for automated decision-making. However, these AI-based systems encounter reliability and safety challenges when handling continuously generated data streams in complex and dynamic scenarios. This work explores the concept of resilient AI systems, which must operate in the face of unexpected events, including instances that belong to patterns that have not been seen during the training process. This is an issue that regular closed-set classifiers commonly encounter in streaming scenarios, as they are designed to compulsory classify any new observation into one of the training patterns (i.e., the so-called \textit{over-occupied space} problem). In batch learning, the Open Set Recognition research area has consistently confronted this issue by requiring models to robustly uphold their classification performance when processing query instances from unknown patterns. In this context, this work investigates the application of an Open Set Recognition framework that combines classification and clustering to address the \textit{over-occupied space} problem in streaming scenarios. Specifically, we systematically devise a benchmark comprising different classification datasets with varying ratios of known to unknown classes. Experiments are presented on this benchmark to compare the performance of the proposed hybrid framework with that of individual incremental classifiers. Discussions held over the obtained results highlight situations where the proposed framework performs best, and delineate the limitations and hurdles encountered by incremental classifiers in effectively resolving the challenges posed by open-world streaming environments.
* 12 pages, 3 figures, an updated version of this article is published in LNAI,volume 14857 as part of the conference proceedings HAIS 2024
On the Black-box Explainability of Object Detection Models for Safe and Trustworthy Industrial Applications
Oct 28, 2024



In the realm of human-machine interaction, artificial intelligence has become a powerful tool for accelerating data modeling tasks. Object detection methods have achieved outstanding results and are widely used in critical domains like autonomous driving and video surveillance. However, their adoption in high-risk applications, where errors may cause severe consequences, remains limited. Explainable Artificial Intelligence (XAI) methods aim to address this issue, but many existing techniques are model-specific and designed for classification tasks, making them less effective for object detection and difficult for non-specialists to interpret. In this work we focus on model-agnostic XAI methods for object detection models and propose D-MFPP, an extension of the Morphological Fragmental Perturbation Pyramid (MFPP), which uses segmentation-based mask generation. Additionally, we introduce D-Deletion, a novel metric combining faithfulness and localization, adapted specifically to meet the unique demands of object detectors. We evaluate these methods on real-world industrial and robotic datasets, examining the influence of parameters such as the number of masks, model size, and image resolution on the quality of explanations. Our experiments use single-stage object detection models applied to two safety-critical robotic environments: i) a shared human-robot workspace where safety is of paramount importance, and ii) an assembly area of battery kits, where safety is critical due to the potential for damage among high-risk components. Our findings evince that D-Deletion effectively gauges the performance of explanations when multiple elements of the same class appear in the same scene, while D-MFPP provides a promising alternative to D-RISE when fewer masks are used.