 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAiGAS-dEVL-RC: An Adaptive Growing Neural Gas Model for Recurrently Drifting Unsupervised Data Streams
Apr 10, 2025


Concept drift and extreme verification latency pose significant challenges in data stream learning, particularly when dealing with recurring concept changes in dynamic environments. This work introduces a novel method based on the Growing Neural Gas (GNG) algorithm, designed to effectively handle abrupt recurrent drifts while adapting to incrementally evolving data distributions (incremental drifts). Leveraging the self-organizing and topological adaptability of GNG, the proposed approach maintains a compact yet informative memory structure, allowing it to efficiently store and retrieve knowledge of past or recurring concepts, even under conditions of delayed or sparse stream supervision. Our experiments highlight the superiority of our approach over existing data stream learning methods designed to cope with incremental non-stationarities and verification latency, demonstrating its ability to quickly adapt to new drifts, robustly manage recurring patterns, and maintain high predictive accuracy with a minimal memory footprint. Unlike other techniques that fail to leverage recurring knowledge, our proposed approach is proven to be a robust and efficient online learning solution for unsupervised drifting data flows.
World Models in Artificial Intelligence: Sensing, Learning, and Reasoning Like a Child
Mar 19, 2025World Models help Artificial Intelligence (AI) predict outcomes, reason about its environment, and guide decision-making. While widely used in reinforcement learning, they lack the structured, adaptive representations that even young children intuitively develop. Advancing beyond pattern recognition requires dynamic, interpretable frameworks inspired by Piaget's cognitive development theory. We highlight six key research areas -- physics-informed learning, neurosymbolic learning, continual learning, causal inference, human-in-the-loop AI, and responsible AI -- as essential for enabling true reasoning in AI. By integrating statistical learning with advances in these areas, AI can evolve from pattern recognition to genuine understanding, adaptation and reasoning capabilities.
Can transformative AI shape a new age for our civilization?: Navigating between speculation and reality
Dec 11, 2024Artificial Intelligence is widely regarded as a transformative force with the potential to redefine numerous sectors of human civilization. While Artificial Intelligence has evolved from speculative fiction to a pivotal element of technological progress, its role as a truly transformative agent, or transformative Artificial Intelligence, remains a subject of debate. This work explores the historical precedents of technological breakthroughs, examining whether Artificial Intelligence can achieve a comparable impact, and it delves into various ethical frameworks that shape the perception and development of Artificial Intelligence. Additionally, it considers the societal, technical, and regulatory challenges that must be addressed for Artificial Intelligence to become a catalyst for global change. We also examine not only the strategies and methodologies that could lead to transformative Artificial Intelligence but also the barriers that could ultimately make these goals unattainable. We end with a critical inquiry into whether reaching a transformative Artificial Intelligence might compel humanity to adopt an entirely new ethical approach, tailored to the complexities of advanced Artificial Intelligence. By addressing the ethical, social, and scientific dimensions of Artificial Intelligence's development, this work contributes to the broader discourse on the long-term implications of Artificial Intelligence and its capacity to drive civilization toward a new era of progress or, conversely, exacerbate existing inequalities and risks.
Resilience to the Flowing Unknown: an Open Set Recognition Framework for Data Streams
Oct 31, 2024Modern digital applications extensively integrate Artificial Intelligence models into their core systems, offering significant advantages for automated decision-making. However, these AI-based systems encounter reliability and safety challenges when handling continuously generated data streams in complex and dynamic scenarios. This work explores the concept of resilient AI systems, which must operate in the face of unexpected events, including instances that belong to patterns that have not been seen during the training process. This is an issue that regular closed-set classifiers commonly encounter in streaming scenarios, as they are designed to compulsory classify any new observation into one of the training patterns (i.e., the so-called \textit{over-occupied space} problem). In batch learning, the Open Set Recognition research area has consistently confronted this issue by requiring models to robustly uphold their classification performance when processing query instances from unknown patterns. In this context, this work investigates the application of an Open Set Recognition framework that combines classification and clustering to address the \textit{over-occupied space} problem in streaming scenarios. Specifically, we systematically devise a benchmark comprising different classification datasets with varying ratios of known to unknown classes. Experiments are presented on this benchmark to compare the performance of the proposed hybrid framework with that of individual incremental classifiers. Discussions held over the obtained results highlight situations where the proposed framework performs best, and delineate the limitations and hurdles encountered by incremental classifiers in effectively resolving the challenges posed by open-world streaming environments.
* 12 pages, 3 figures, an updated version of this article is published in LNAI,volume 14857 as part of the conference proceedings HAIS 2024
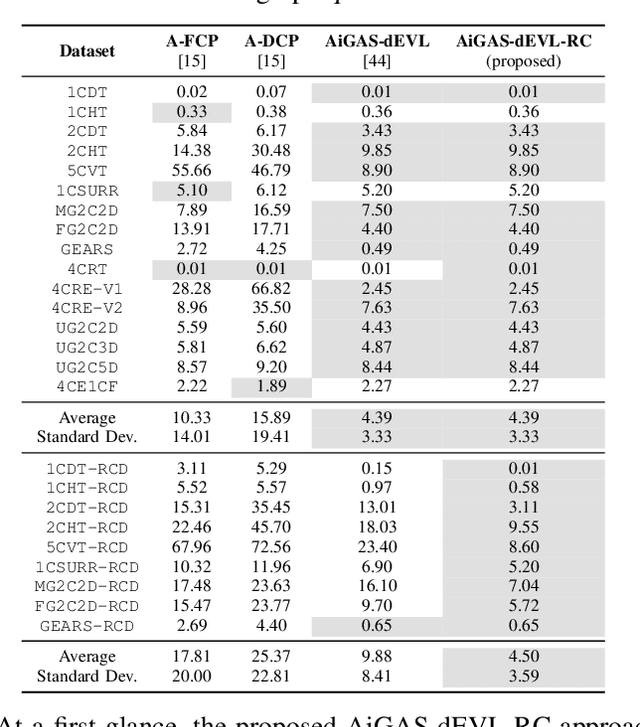
AiGAS-dEVL: An Adaptive Incremental Neural Gas Model for Drifting Data Streams under Extreme Verification Latency
Jul 07, 2024The ever-growing speed at which data are generated nowadays, together with the substantial cost of labeling processes cause Machine Learning models to face scenarios in which data are partially labeled. The extreme case where such a supervision is indefinitely unavailable is referred to as extreme verification latency. On the other hand, in streaming setups data flows are affected by exogenous factors that yield non-stationarities in the patterns (concept drift), compelling models learned incrementally from the data streams to adapt their modeled knowledge to the concepts within the stream. In this work we address the casuistry in which these two conditions occur together, by which adaptation mechanisms to accommodate drifts within the stream are challenged by the lack of supervision, requiring further mechanisms to track the evolution of concepts in the absence of verification. To this end we propose a novel approach, AiGAS-dEVL (Adaptive Incremental neural GAS model for drifting Streams under Extreme Verification Latency), which relies on growing neural gas to characterize the distributions of all concepts detected within the stream over time. Our approach exposes that the online analysis of the behavior of these prototypical points over time facilitates the definition of the evolution of concepts in the feature space, the detection of changes in their behavior, and the design of adaptation policies to mitigate the effect of such changes in the model. We assess the performance of AiGAS-dEVL over several synthetic datasets, comparing it to that of state-of-the-art approaches proposed in the recent past to tackle this stream learning setup. Our results reveal that AiGAS-dEVL performs competitively with respect to the rest of baselines, exhibiting a superior adaptability over several datasets in the benchmark while ensuring a simple and interpretable instance-based adaptation strategy.
Multiobjective Optimization Analysis for Finding Infrastructure-as-Code Deployment Configurations
Jan 18, 2024



Multiobjective optimization is a hot topic in the artificial intelligence and operations research communities. The design and development of multiobjective methods is a frequent task for researchers and practitioners. As a result of this vibrant activity, a myriad of techniques have been proposed in the literature to date, demonstrating a significant effectiveness for dealing with situations coming from a wide range of real-world areas. This paper is focused on a multiobjective problem related to optimizing Infrastructure-as-Code deployment configurations. The system implemented for solving this problem has been coined as IaC Optimizer Platform (IOP). Despite the fact that a prototypical version of the IOP has been introduced in the literature before, a deeper analysis focused on the resolution of the problem is needed, in order to determine which is the most appropriate multiobjective method for embedding in the IOP. The main motivation behind the analysis conducted in this work is to enhance the IOP performance as much as possible. This is a crucial aspect of this system, deeming that it will be deployed in a real environment, as it is being developed as part of a H2020 European project. Going deeper, we resort in this paper to nine different evolutionary computation-based multiobjective algorithms. For assessing the quality of the considered solvers, 12 different problem instances have been generated based on real-world settings. Results obtained by each method after 10 independent runs have been compared using Friedman's non-parametric tests. Findings reached from the tests carried out lad to the creation of a multi-algorithm system, capable of applying different techniques according to the user's needs.
Managing the unknown: a survey on Open Set Recognition and tangential areas
Dec 14, 2023

In real-world scenarios classification models are often required to perform robustly when predicting samples belonging to classes that have not appeared during its training stage. Open Set Recognition addresses this issue by devising models capable of detecting unknown classes from samples arriving during the testing phase, while maintaining a good level of performance in the classification of samples belonging to known classes. This review comprehensively overviews the recent literature related to Open Set Recognition, identifying common practices, limitations, and connections of this field with other machine learning research areas, such as continual learning, out-of-distribution detection, novelty detection, and uncertainty estimation. Our work also uncovers open problems and suggests several research directions that may motivate and articulate future efforts towards more safe Artificial Intelligence methods.
Optimizing IaC Configurations: a Case Study Using Nature-inspired Computing
Nov 15, 2023



In the last years, one of the fields of artificial intelligence that has been investigated the most is nature-inspired computing. The research done on this specific topic showcases the interest that sparks in researchers and practitioners, who put their focus on this paradigm because of the adaptability and ability of nature-inspired algorithms to reach high-quality outcomes on a wide range of problems. In fact, this kind of methods has been successfully applied to solve real-world problems in heterogeneous fields such as medicine, transportation, industry, or software engineering. Our main objective with this paper is to describe a tool based on nature-inspired computing for solving a specific software engineering problem. The problem faced consists of optimizing Infrastructure as Code deployment configurations. For this reason, the name of the system is IaC Optimizer Platform. A prototypical version of the IOP was described in previous works, in which the functionality of this platform was introduced. With this paper, we take a step forward by describing the final release of the IOP, highlighting its main contribution regarding the current state-of-the-art, and justifying the decisions made on its implementation. Also, we contextualize the IOP within the complete platform in which it is embedded, describing how a user can benefit from its use. To do that, we also present and solve a real-world use case.
On the Connection between Concept Drift and Uncertainty in Industrial Artificial Intelligence
Mar 14, 2023
AI-based digital twins are at the leading edge of the Industry 4.0 revolution, which are technologically empowered by the Internet of Things and real-time data analysis. Information collected from industrial assets is produced in a continuous fashion, yielding data streams that must be processed under stringent timing constraints. Such data streams are usually subject to non-stationary phenomena, causing that the data distribution of the streams may change, and thus the knowledge captured by models used for data analysis may become obsolete (leading to the so-called concept drift effect). The early detection of the change (drift) is crucial for updating the model's knowledge, which is challenging especially in scenarios where the ground truth associated to the stream data is not readily available. Among many other techniques, the estimation of the model's confidence has been timidly suggested in a few studies as a criterion for detecting drifts in unsupervised settings. The goal of this manuscript is to confirm and expose solidly the connection between the model's confidence in its output and the presence of a concept drift, showcasing it experimentally and advocating for a major consideration of uncertainty estimation in comparative studies to be reported in the future.
A Novel Explainable Out-of-Distribution Detection Approach for Spiking Neural Networks
Sep 30, 2022


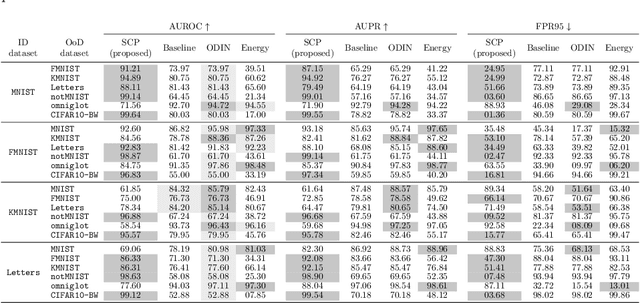
Research around Spiking Neural Networks has ignited during the last years due to their advantages when compared to traditional neural networks, including their efficient processing and inherent ability to model complex temporal dynamics. Despite these differences, Spiking Neural Networks face similar issues than other neural computation counterparts when deployed in real-world settings. This work addresses one of the practical circumstances that can hinder the trustworthiness of this family of models: the possibility of querying a trained model with samples far from the distribution of its training data (also referred to as Out-of-Distribution or OoD data). Specifically, this work presents a novel OoD detector that can identify whether test examples input to a Spiking Neural Network belong to the distribution of the data over which it was trained. For this purpose, we characterize the internal activations of the hidden layers of the network in the form of spike count patterns, which lay a basis for determining when the activations induced by a test instance is atypical. Furthermore, a local explanation method is devised to produce attribution maps revealing which parts of the input instance push most towards the detection of an example as an OoD sample. Experimental results are performed over several image classification datasets to compare the proposed detector to other OoD detection schemes from the literature. As the obtained results clearly show, the proposed detector performs competitively against such alternative schemes, and produces relevance attribution maps that conform to expectations for synthetically created OoD instances.