 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Case for Model Science: Verify, Explore, Steer, Refine
May 31, 2026We argue that the AI community is now ready to move beyond benchmarking and consolidate scattered efforts in model analysis into a systematic discipline, a direction we term Model Science. Complex AI models now serve billions of users, yet our understanding of how they work lags far behind our ability to deploy them. Decades of benchmark-driven research have delivered remarkable progress: extensive leaderboards, a wide range of performance metrics, tracking capability gains across diverse tasks; yet this success has also revealed the limits of benchmarks as they tell us whether models perform but not why they succeed or fail, they miss critical failure modes, such as hallucinations or shortcuts. Precedents from established sciences point the way forward: cognitive science shows that understanding complex systems requires complementary levels of analysis; neuroscience demonstrates that deep study of single cases reveals what population studies miss; medicine teaches that specialised training must develop alongside research practice; and agriculture models how shared infrastructure and principles enable cumulative progress. These lessons inform three foundations for Model Science. First, we propose to consolidate research around four functional perspectives: Verify, Explore, Steer, and Refine that address complementary questions about model behaviour. Second, we discuss the required infrastructure for cumulative knowledge: catalogues of datasets, models and findings. Third, we highlight the need for deep analysis of individual model instances, not just model families, because single cases can reveal what population studies miss.
OSCAR: Open-Set CAD Retrieval from a Language Prompt and a Single Image
Jan 12, 20266D object pose estimation plays a crucial role in scene understanding for applications such as robotics and augmented reality. To support the needs of ever-changing object sets in such context, modern zero-shot object pose estimators were developed to not require object-specific training but only rely on CAD models. Such models are hard to obtain once deployed, and a continuously changing and growing set of objects makes it harder to reliably identify the instance model of interest. To address this challenge, we introduce an Open-Set CAD Retrieval from a Language Prompt and a Single Image (OSCAR), a novel training-free method that retrieves a matching object model from an unlabeled 3D object database. During onboarding, OSCAR generates multi-view renderings of database models and annotates them with descriptive captions using an image captioning model. At inference, GroundedSAM detects the queried object in the input image, and multi-modal embeddings are computed for both the Region-of-Interest and the database captions. OSCAR employs a two-stage retrieval: text-based filtering using CLIP identifies candidate models, followed by image-based refinement using DINOv2 to select the most visually similar object. In our experiments we demonstrate that OSCAR outperforms all state-of-the-art methods on the cross-domain 3D model retrieval benchmark MI3DOR. Furthermore, we demonstrate OSCAR's direct applicability in automating object model sourcing for 6D object pose estimation. We propose using the most similar object model for pose estimation if the exact instance is not available and show that OSCAR achieves an average precision of 90.48\% during object retrieval on the YCB-V object dataset. Moreover, we demonstrate that the most similar object model can be utilized for pose estimation using Megapose achieving better results than a reconstruction-based approach.
World Models in Artificial Intelligence: Sensing, Learning, and Reasoning Like a Child
Mar 19, 2025World Models help Artificial Intelligence (AI) predict outcomes, reason about its environment, and guide decision-making. While widely used in reinforcement learning, they lack the structured, adaptive representations that even young children intuitively develop. Advancing beyond pattern recognition requires dynamic, interpretable frameworks inspired by Piaget's cognitive development theory. We highlight six key research areas -- physics-informed learning, neurosymbolic learning, continual learning, causal inference, human-in-the-loop AI, and responsible AI -- as essential for enabling true reasoning in AI. By integrating statistical learning with advances in these areas, AI can evolve from pattern recognition to genuine understanding, adaptation and reasoning capabilities.
Be Careful When Evaluating Explanations Regarding Ground Truth
Nov 08, 2023



Evaluating explanations of image classifiers regarding ground truth, e.g. segmentation masks defined by human perception, primarily evaluates the quality of the models under consideration rather than the explanation methods themselves. Driven by this observation, we propose a framework for $\textit{jointly}$ evaluating the robustness of safety-critical systems that $\textit{combine}$ a deep neural network with an explanation method. These are increasingly used in real-world applications like medical image analysis or robotics. We introduce a fine-tuning procedure to (mis)align model$\unicode{x2013}$explanation pipelines with ground truth and use it to quantify the potential discrepancy between worst and best-case scenarios of human alignment. Experiments across various model architectures and post-hoc local interpretation methods provide insights into the robustness of vision transformers and the overall vulnerability of such AI systems to potential adversarial attacks.
Explainable Artificial Intelligence (XAI) 2.0: A Manifesto of Open Challenges and Interdisciplinary Research Directions
Oct 30, 2023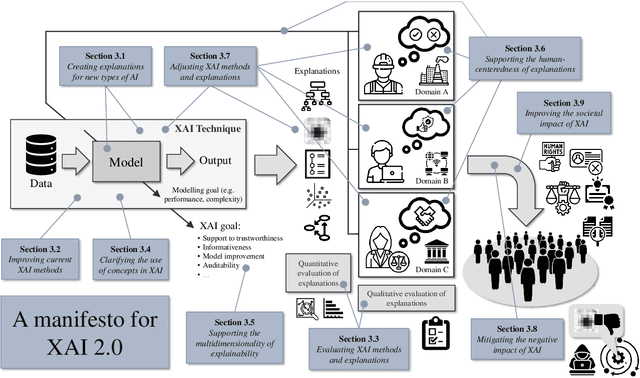
As systems based on opaque Artificial Intelligence (AI) continue to flourish in diverse real-world applications, understanding these black box models has become paramount. In response, Explainable AI (XAI) has emerged as a field of research with practical and ethical benefits across various domains. This paper not only highlights the advancements in XAI and its application in real-world scenarios but also addresses the ongoing challenges within XAI, emphasizing the need for broader perspectives and collaborative efforts. We bring together experts from diverse fields to identify open problems, striving to synchronize research agendas and accelerate XAI in practical applications. By fostering collaborative discussion and interdisciplinary cooperation, we aim to propel XAI forward, contributing to its continued success. Our goal is to put forward a comprehensive proposal for advancing XAI. To achieve this goal, we present a manifesto of 27 open problems categorized into nine categories. These challenges encapsulate the complexities and nuances of XAI and offer a road map for future research. For each problem, we provide promising research directions in the hope of harnessing the collective intelligence of interested stakeholders.
Explaining and visualizing black-box models through counterfactual paths
Aug 01, 2023Explainable AI (XAI) is an increasingly important area of machine learning research, which aims to make black-box models transparent and interpretable. In this paper, we propose a novel approach to XAI that uses the so-called counterfactual paths generated by conditional permutations of features. The algorithm measures feature importance by identifying sequential permutations of features that most influence changes in model predictions. It is particularly suitable for generating explanations based on counterfactual paths in knowledge graphs incorporating domain knowledge. Counterfactual paths introduce an additional graph dimension to current XAI methods in both explaining and visualizing black-box models. Experiments with synthetic and medical data demonstrate the practical applicability of our approach.
Ethical ChatGPT: Concerns, Challenges, and Commandments
May 18, 2023Large language models, e.g. ChatGPT are currently contributing enormously to make artificial intelligence even more popular, especially among the general population. However, such chatbot models were developed as tools to support natural language communication between humans. Problematically, it is very much a ``statistical correlation machine" (correlation instead of causality) and there are indeed ethical concerns associated with the use of AI language models such as ChatGPT, such as Bias, Privacy, and Abuse. This paper highlights specific ethical concerns on ChatGPT and articulates key challenges when ChatGPT is used in various applications. Practical commandments for different stakeholders of ChatGPT are also proposed that can serve as checklist guidelines for those applying ChatGPT in their applications. These commandment examples are expected to motivate the ethical use of ChatGPT.
Exploring the Trade-off between Plausibility, Change Intensity and Adversarial Power in Counterfactual Explanations using Multi-objective Optimization
May 20, 2022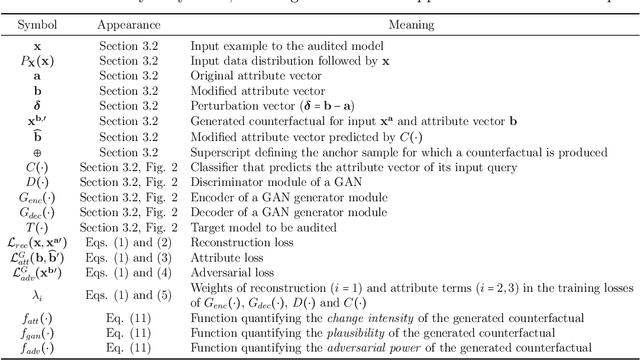
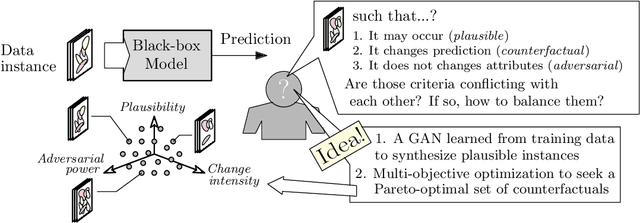
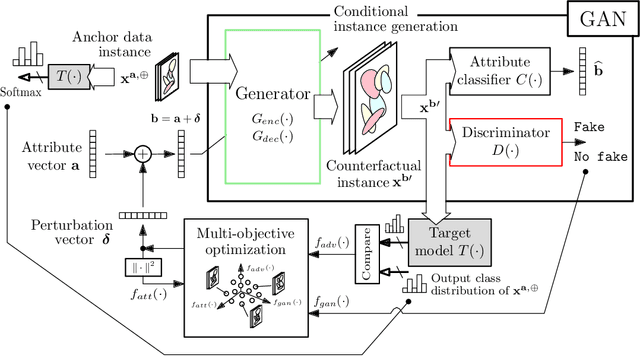

There is a broad consensus on the importance of deep learning models in tasks involving complex data. Often, an adequate understanding of these models is required when focusing on the transparency of decisions in human-critical applications. Besides other explainability techniques, trustworthiness can be achieved by using counterfactuals, like the way a human becomes familiar with an unknown process: by understanding the hypothetical circumstances under which the output changes. In this work we argue that automated counterfactual generation should regard several aspects of the produced adversarial instances, not only their adversarial capability. To this end, we present a novel framework for the generation of counterfactual examples which formulates its goal as a multi-objective optimization problem balancing three different objectives: 1) plausibility, i.e., the likeliness of the counterfactual of being possible as per the distribution of the input data; 2) intensity of the changes to the original input; and 3) adversarial power, namely, the variability of the model's output induced by the counterfactual. The framework departs from a target model to be audited and uses a Generative Adversarial Network to model the distribution of input data, together with a multi-objective solver for the discovery of counterfactuals balancing among these objectives. The utility of the framework is showcased over six classification tasks comprising image and three-dimensional data. The experiments verify that the framework unveils counterfactuals that comply with intuition, increasing the trustworthiness of the user, and leading to further insights, such as the detection of bias and data misrepresentation.
A Practical Tutorial on Explainable AI Techniques
Nov 13, 2021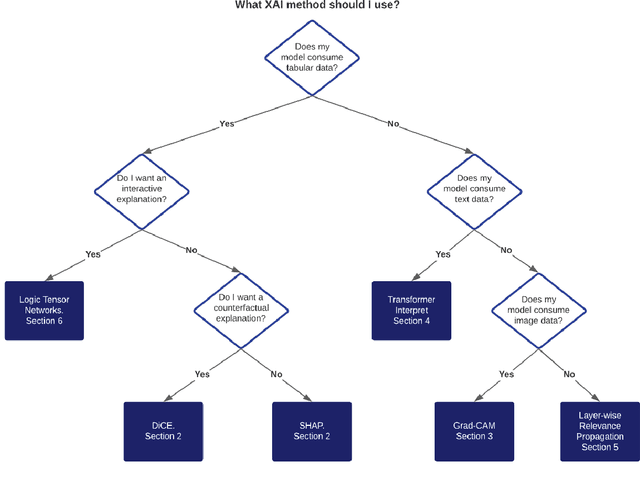
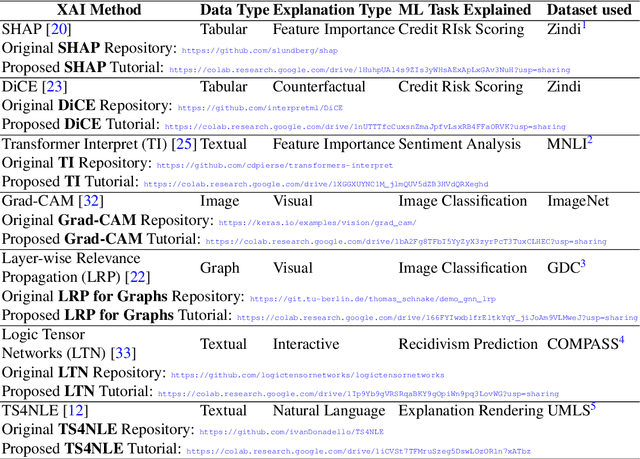
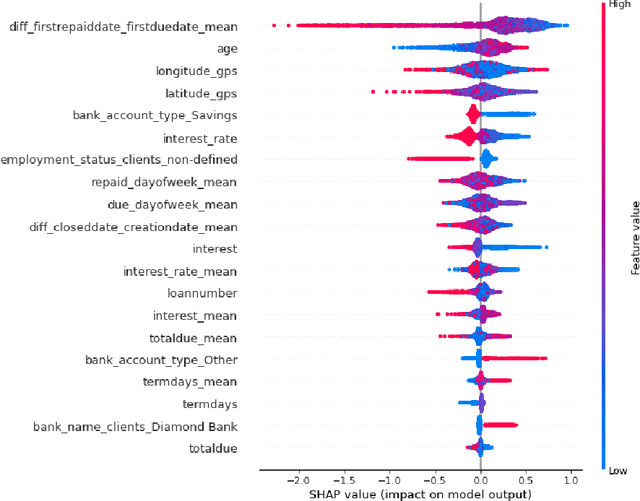
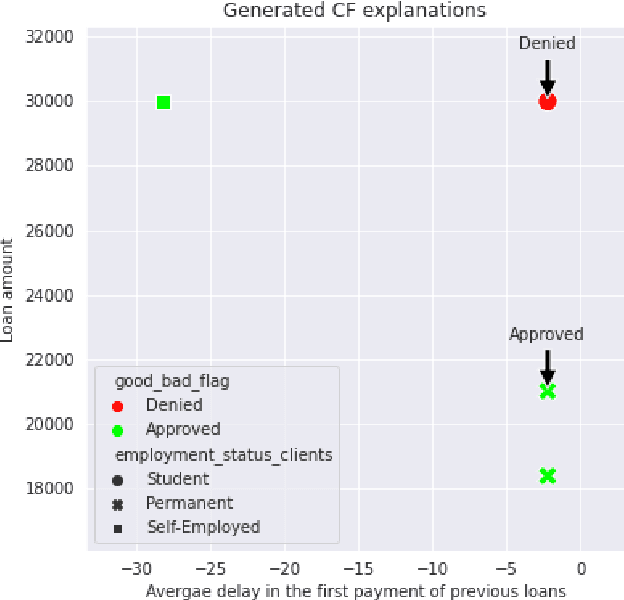
Last years have been characterized by an upsurge of opaque automatic decision support systems, such as Deep Neural Networks (DNNs). Although they have great generalization and prediction skills, their functioning does not allow obtaining detailed explanations of their behaviour. As opaque machine learning models are increasingly being employed to make important predictions in critical environments, the danger is to create and use decisions that are not justifiable or legitimate. Therefore, there is a general agreement on the importance of endowing machine learning models with explainability. The reason is that EXplainable Artificial Intelligence (XAI) techniques can serve to verify and certify model outputs and enhance them with desirable notions such as trustworthiness, accountability, transparency and fairness. This tutorial is meant to be the go-to handbook for any audience with a computer science background aiming at getting intuitive insights of machine learning models, accompanied with straight, fast, and intuitive explanations out of the box. We believe that these methods provide a valuable contribution for applying XAI techniques in their particular day-to-day models, datasets and use-cases. Figure \ref{fig:Flowchart} acts as a flowchart/map for the reader and should help him to find the ideal method to use according to his type of data. The reader will find a description of the proposed method as well as an example of use and a Python notebook that he can easily modify as he pleases in order to apply it to his own case of application.
Network Module Detection from Multi-Modal Node Features with a Greedy Decision Forest for Actionable Explainable AI
Aug 26, 2021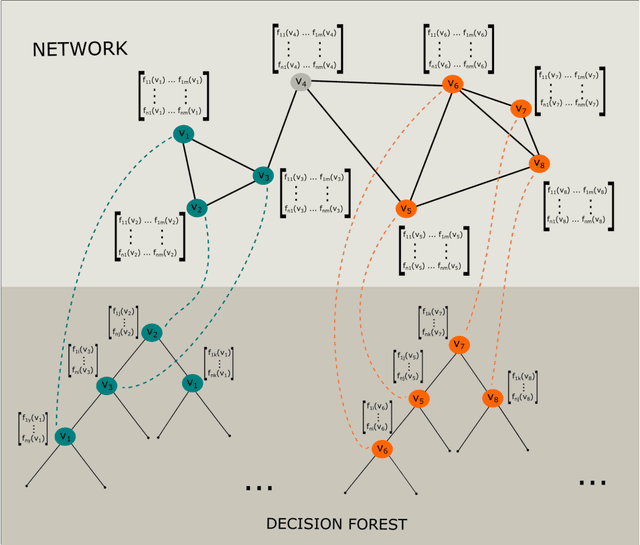
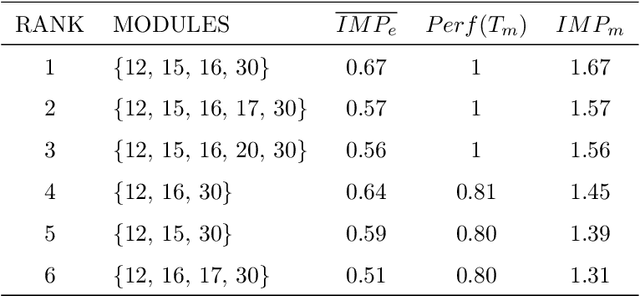
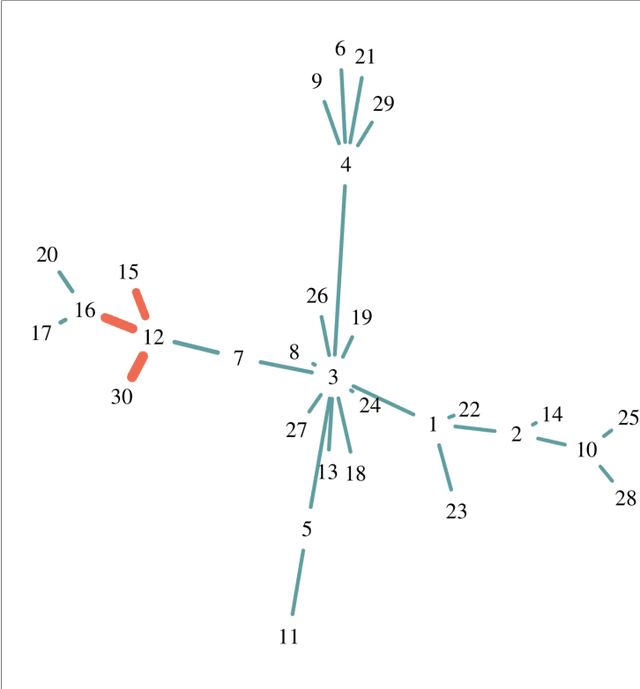
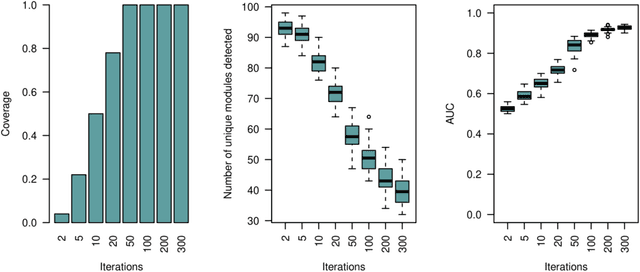
Network-based algorithms are used in most domains of research and industry in a wide variety of applications and are of great practical use. In this work, we demonstrate subnetwork detection based on multi-modal node features using a new Greedy Decision Forest for better interpretability. The latter will be a crucial factor in retaining experts and gaining their trust in such algorithms in the future. To demonstrate a concrete application example, we focus in this paper on bioinformatics and systems biology with a special focus on biomedicine. However, our methodological approach is applicable in many other domains as well. Systems biology serves as a very good example of a field in which statistical data-driven machine learning enables the analysis of large amounts of multi-modal biomedical data. This is important to reach the future goal of precision medicine, where the complexity of patients is modeled on a system level to best tailor medical decisions, health practices and therapies to the individual patient. Our glass-box approach could help to uncover disease-causing network modules from multi-omics data to better understand diseases such as cancer.