 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUBIC: Concept Embeddings for Unsupervised Bias Identification using VLMs
May 16, 2025Deep vision models often rely on biases learned from spurious correlations in datasets. To identify these biases, methods that interpret high-level, human-understandable concepts are more effective than those relying primarily on low-level features like heatmaps. A major challenge for these concept-based methods is the lack of image annotations indicating potentially bias-inducing concepts, since creating such annotations requires detailed labeling for each dataset and concept, which is highly labor-intensive. We present CUBIC (Concept embeddings for Unsupervised Bias IdentifiCation), a novel method that automatically discovers interpretable concepts that may bias classifier behavior. Unlike existing approaches, CUBIC does not rely on predefined bias candidates or examples of model failures tied to specific biases, as such information is not always available. Instead, it leverages image-text latent space and linear classifier probes to examine how the latent representation of a superclass label$\unicode{x2014}$shared by all instances in the dataset$\unicode{x2014}$is influenced by the presence of a given concept. By measuring these shifts against the normal vector to the classifier's decision boundary, CUBIC identifies concepts that significantly influence model predictions. Our experiments demonstrate that CUBIC effectively uncovers previously unknown biases using Vision-Language Models (VLMs) without requiring the samples in the dataset where the classifier underperforms or prior knowledge of potential biases.
Using Curiosity for an Even Representation of Tasks in Continual Offline Reinforcement Learning
Dec 05, 2023In this work, we investigate the means of using curiosity on replay buffers to improve offline multi-task continual reinforcement learning when tasks, which are defined by the non-stationarity in the environment, are non labeled and not evenly exposed to the learner in time. In particular, we investigate the use of curiosity both as a tool for task boundary detection and as a priority metric when it comes to retaining old transition tuples, which we respectively use to propose two different buffers. Firstly, we propose a Hybrid Reservoir Buffer with Task Separation (HRBTS), where curiosity is used to detect task boundaries that are not known due to the task agnostic nature of the problem. Secondly, by using curiosity as a priority metric when it comes to retaining old transition tuples, a Hybrid Curious Buffer (HCB) is proposed. We ultimately show that these buffers, in conjunction with regular reinforcement learning algorithms, can be used to alleviate the catastrophic forgetting issue suffered by the state of the art on replay buffers when the agent's exposure to tasks is not equal along time. We evaluate catastrophic forgetting and the efficiency of our proposed buffers against the latest works such as the Hybrid Reservoir Buffer (HRB) and the Multi-Time Scale Replay Buffer (MTR) in three different continual reinforcement learning settings. Experiments were done on classical control tasks and Metaworld environment. Experiments show that our proposed replay buffers display better immunity to catastrophic forgetting compared to existing works in most of the settings.
Connecting the Dots in Trustworthy Artificial Intelligence: From AI Principles, Ethics, and Key Requirements to Responsible AI Systems and Regulation
May 02, 2023



Trustworthy Artificial Intelligence (AI) is based on seven technical requirements sustained over three main pillars that should be met throughout the system's entire life cycle: it should be (1) lawful, (2) ethical, and (3) robust, both from a technical and a social perspective. However, attaining truly trustworthy AI concerns a wider vision that comprises the trustworthiness of all processes and actors that are part of the system's life cycle, and considers previous aspects from different lenses. A more holistic vision contemplates four essential axes: the global principles for ethical use and development of AI-based systems, a philosophical take on AI ethics, a risk-based approach to AI regulation, and the mentioned pillars and requirements. The seven requirements (human agency and oversight; robustness and safety; privacy and data governance; transparency; diversity, non-discrimination and fairness; societal and environmental wellbeing; and accountability) are analyzed from a triple perspective: What each requirement for trustworthy AI is, Why it is needed, and How each requirement can be implemented in practice. On the other hand, a practical approach to implement trustworthy AI systems allows defining the concept of responsibility of AI-based systems facing the law, through a given auditing process. Therefore, a responsible AI system is the resulting notion we introduce in this work, and a concept of utmost necessity that can be realized through auditing processes, subject to the challenges posed by the use of regulatory sandboxes. Our multidisciplinary vision of trustworthy AI also includes a regulation debate, with the purpose of serving as an entry point to this crucial field in the present and future progress of our society.
Towards a more efficient computation of individual attribute and policy contribution for post-hoc explanation of cooperative multi-agent systems using Myerson values
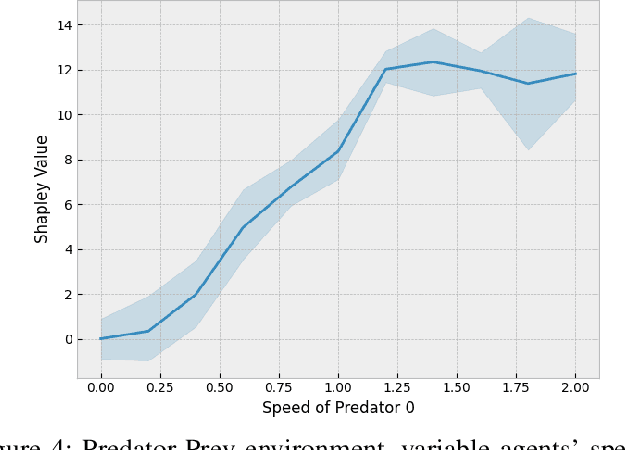
Dec 06, 2022A quantitative assessment of the global importance of an agent in a team is as valuable as gold for strategists, decision-makers, and sports coaches. Yet, retrieving this information is not trivial since in a cooperative task it is hard to isolate the performance of an individual from the one of the whole team. Moreover, it is not always clear the relationship between the role of an agent and his personal attributes. In this work we conceive an application of the Shapley analysis for studying the contribution of both agent policies and attributes, putting them on equal footing. Since the computational complexity is NP-hard and scales exponentially with the number of participants in a transferable utility coalitional game, we resort to exploiting a-priori knowledge about the rules of the game to constrain the relations between the participants over a graph. We hence propose a method to determine a Hierarchical Knowledge Graph of agents' policies and features in a Multi-Agent System. Assuming a simulator of the system is available, the graph structure allows to exploit dynamic programming to assess the importances in a much faster way. We test the proposed approach in a proof-of-case environment deploying both hardcoded policies and policies obtained via Deep Reinforcement Learning. The proposed paradigm is less computationally demanding than trivially computing the Shapley values and provides great insight not only into the importance of an agent in a team but also into the attributes needed to deploy the policy at its best.
Exploring the Trade-off between Plausibility, Change Intensity and Adversarial Power in Counterfactual Explanations using Multi-objective Optimization
May 20, 2022
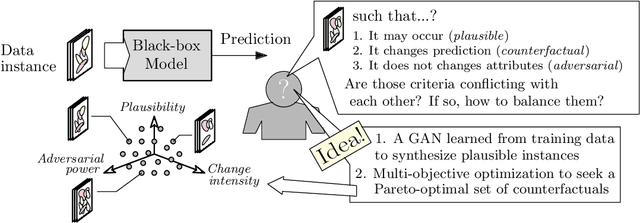
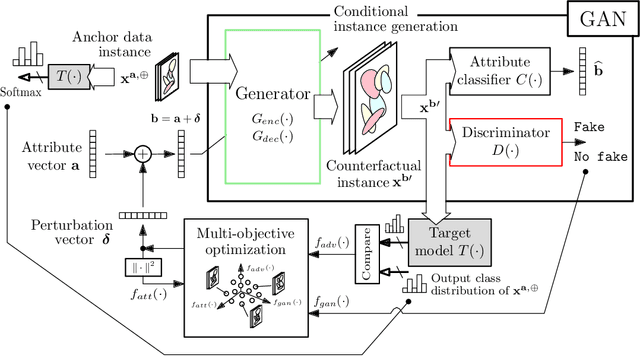

There is a broad consensus on the importance of deep learning models in tasks involving complex data. Often, an adequate understanding of these models is required when focusing on the transparency of decisions in human-critical applications. Besides other explainability techniques, trustworthiness can be achieved by using counterfactuals, like the way a human becomes familiar with an unknown process: by understanding the hypothetical circumstances under which the output changes. In this work we argue that automated counterfactual generation should regard several aspects of the produced adversarial instances, not only their adversarial capability. To this end, we present a novel framework for the generation of counterfactual examples which formulates its goal as a multi-objective optimization problem balancing three different objectives: 1) plausibility, i.e., the likeliness of the counterfactual of being possible as per the distribution of the input data; 2) intensity of the changes to the original input; and 3) adversarial power, namely, the variability of the model's output induced by the counterfactual. The framework departs from a target model to be audited and uses a Generative Adversarial Network to model the distribution of input data, together with a multi-objective solver for the discovery of counterfactuals balancing among these objectives. The utility of the framework is showcased over six classification tasks comprising image and three-dimensional data. The experiments verify that the framework unveils counterfactuals that comply with intuition, increasing the trustworthiness of the user, and leading to further insights, such as the detection of bias and data misrepresentation.
OG-SGG: Ontology-Guided Scene Graph Generation. A Case Study in Transfer Learning for Telepresence Robotics
Feb 21, 2022

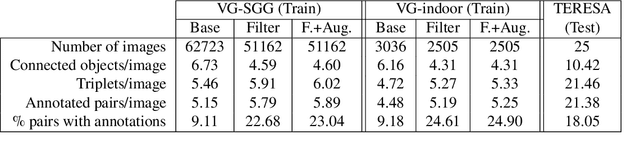
Scene graph generation from images is a task of great interest to applications such as robotics, because graphs are the main way to represent knowledge about the world and regulate human-robot interactions in tasks such as Visual Question Answering (VQA). Unfortunately, its corresponding area of machine learning is still relatively in its infancy, and the solutions currently offered do not specialize well in concrete usage scenarios. Specifically, they do not take existing "expert" knowledge about the domain world into account; and that might indeed be necessary in order to provide the level of reliability demanded by the use case scenarios. In this paper, we propose an initial approximation to a framework called Ontology-Guided Scene Graph Generation (OG-SGG), that can improve the performance of an existing machine learning based scene graph generator using prior knowledge supplied in the form of an ontology; and we present results evaluated on a specific scenario founded in telepresence robotics.
A Practical Tutorial on Explainable AI Techniques
Nov 13, 2021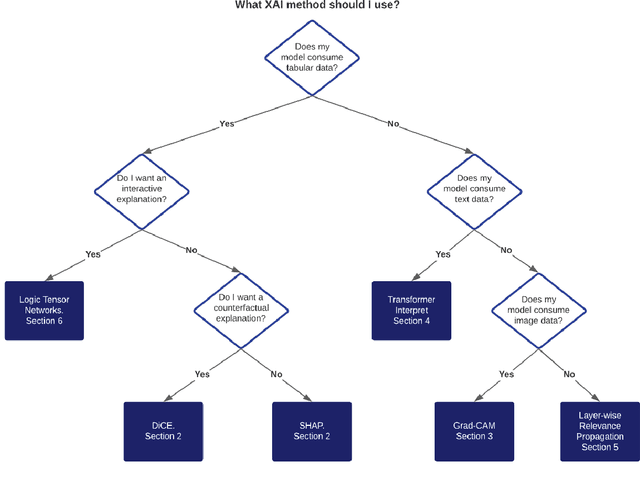
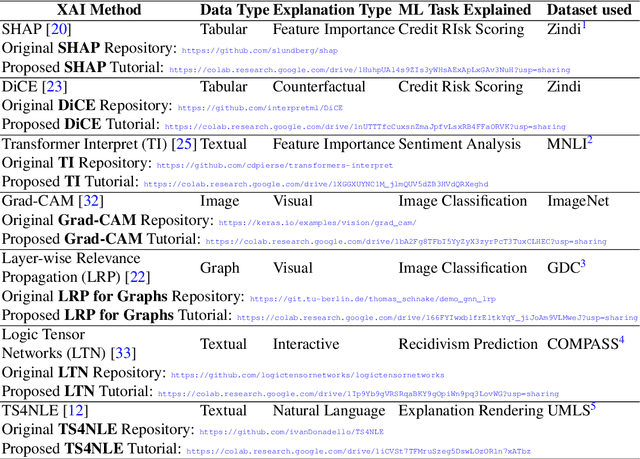
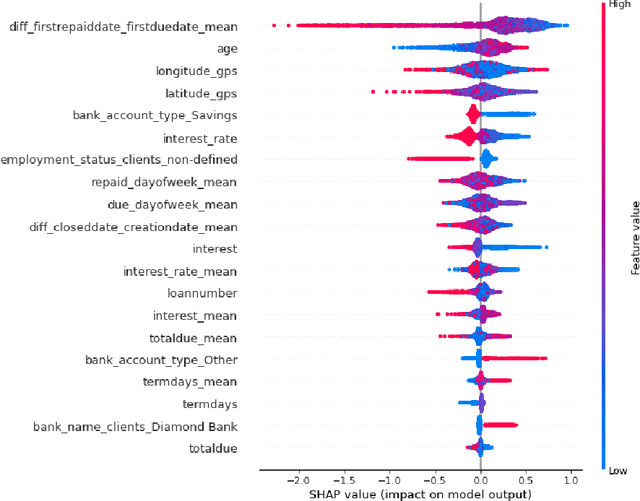
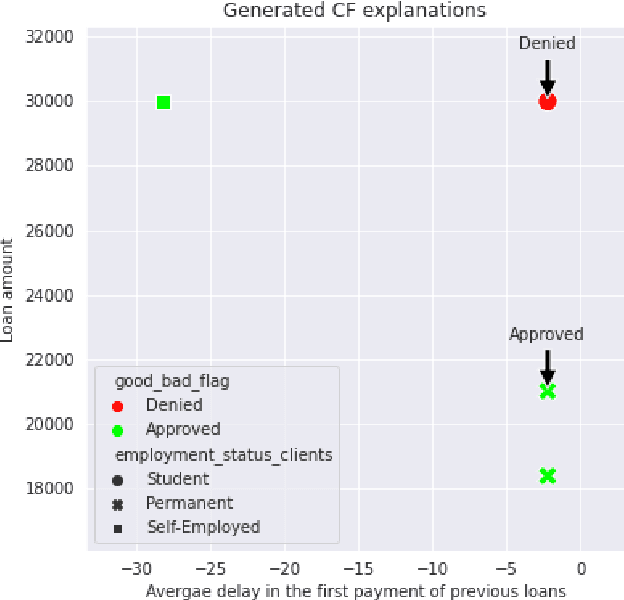
Last years have been characterized by an upsurge of opaque automatic decision support systems, such as Deep Neural Networks (DNNs). Although they have great generalization and prediction skills, their functioning does not allow obtaining detailed explanations of their behaviour. As opaque machine learning models are increasingly being employed to make important predictions in critical environments, the danger is to create and use decisions that are not justifiable or legitimate. Therefore, there is a general agreement on the importance of endowing machine learning models with explainability. The reason is that EXplainable Artificial Intelligence (XAI) techniques can serve to verify and certify model outputs and enhance them with desirable notions such as trustworthiness, accountability, transparency and fairness. This tutorial is meant to be the go-to handbook for any audience with a computer science background aiming at getting intuitive insights of machine learning models, accompanied with straight, fast, and intuitive explanations out of the box. We believe that these methods provide a valuable contribution for applying XAI techniques in their particular day-to-day models, datasets and use-cases. Figure \ref{fig:Flowchart} acts as a flowchart/map for the reader and should help him to find the ideal method to use according to his type of data. The reader will find a description of the proposed method as well as an example of use and a Python notebook that he can easily modify as he pleases in order to apply it to his own case of application.
Collective eXplainable AI: Explaining Cooperative Strategies and Agent Contribution in Multiagent Reinforcement Learning with Shapley Values
Oct 04, 2021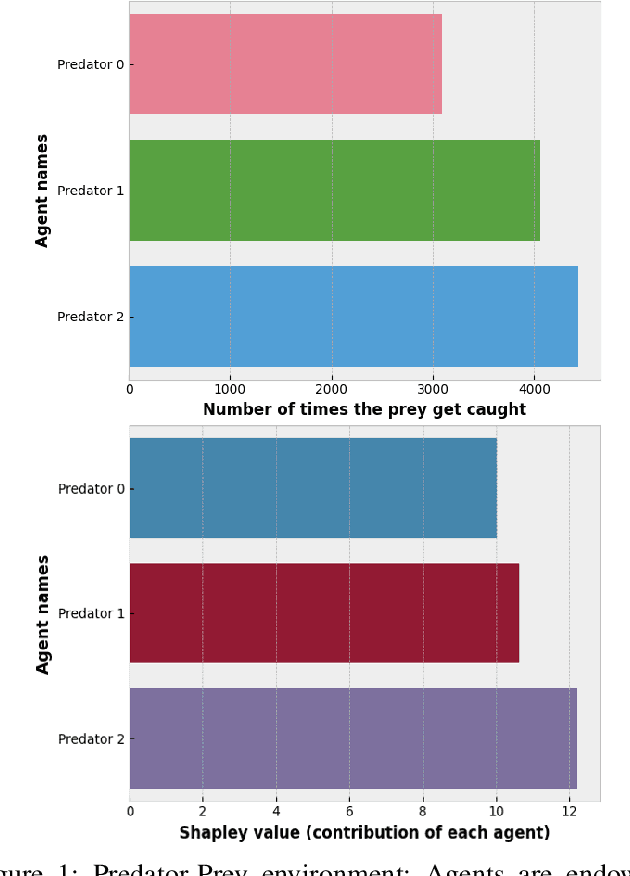
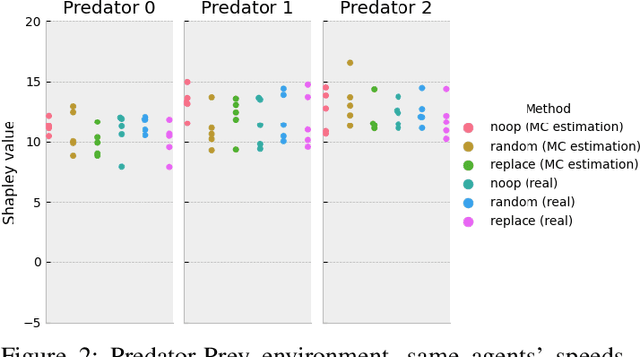
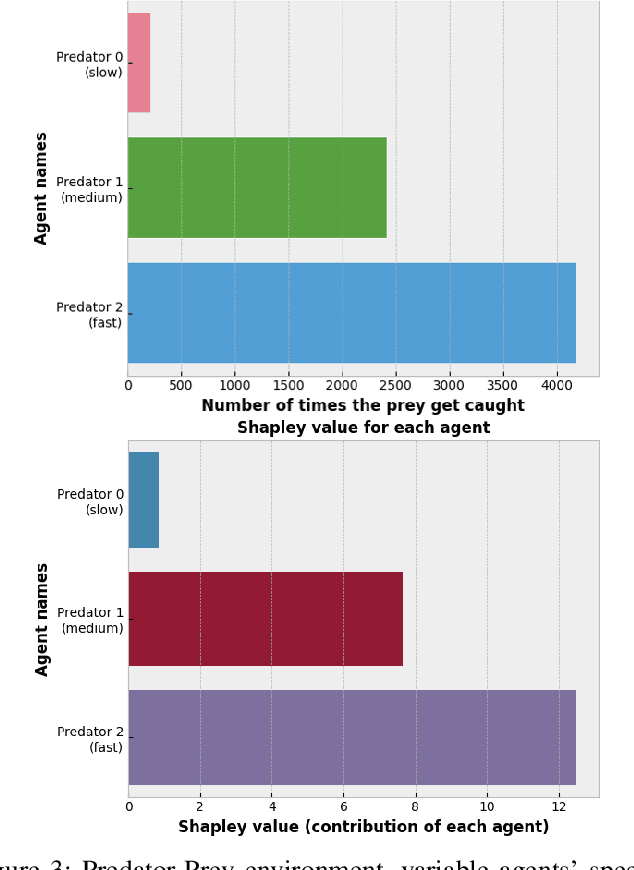
While Explainable Artificial Intelligence (XAI) is increasingly expanding more areas of application, little has been applied to make deep Reinforcement Learning (RL) more comprehensible. As RL becomes ubiquitous and used in critical and general public applications, it is essential to develop methods that make it better understood and more interpretable. This study proposes a novel approach to explain cooperative strategies in multiagent RL using Shapley values, a game theory concept used in XAI that successfully explains the rationale behind decisions taken by Machine Learning algorithms. Through testing common assumptions of this technique in two cooperation-centered socially challenging multi-agent environments environments, this article argues that Shapley values are a pertinent way to evaluate the contribution of players in a cooperative multi-agent RL context. To palliate the high overhead of this method, Shapley values are approximated using Monte Carlo sampling. Experimental results on Multiagent Particle and Sequential Social Dilemmas show that Shapley values succeed at estimating the contribution of each agent. These results could have implications that go beyond games in economics, (e.g., for non-discriminatory decision making, ethical and responsible AI-derived decisions or policy making under fairness constraints). They also expose how Shapley values only give general explanations about a model and cannot explain a single run, episode nor justify precise actions taken by agents. Future work should focus on addressing these critical aspects.
Efficient State Representation Learning for Dynamic Robotic Scenarios
Sep 17, 2021
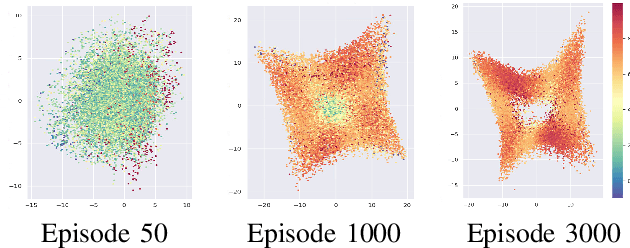
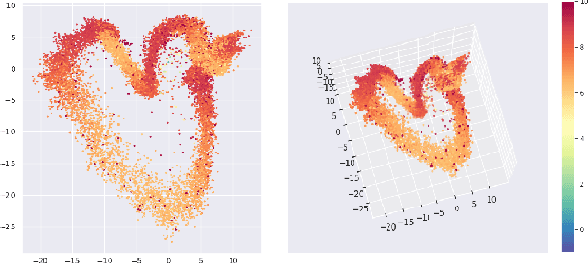
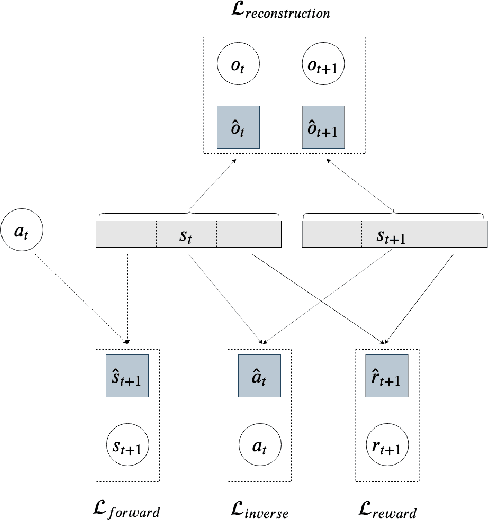
While the rapid progress of deep learning fuels end-to-end reinforcement learning (RL), direct application, especially in high-dimensional space like robotic scenarios still suffers from high sample efficiency. Therefore State Representation Learning (SRL) is proposed to specifically learn to encode task-relevant features from complex sensory data into low-dimensional states. However, the pervasive implementation of SRL is usually conducted by a decoupling strategy in which the observation-state mapping is learned separately, which is prone to over-fit. To handle such problem, we present a new algorithm called Policy Optimization via Abstract Representation which integrates SRL into the original RL scale. Firstly, We engage RL loss to assist in updating SRL model so that the states can evolve to meet the demand of reinforcement learning and maintain a good physical interpretation. Secondly, we introduce a dynamic parameter adjustment mechanism so that both models can efficiently adapt to each other. Thirdly, we introduce a new prior called domain resemblance to leverage expert demonstration to train the SRL model. Finally, we provide a real-time access by state graph to monitor the course of learning. Results show that our algorithm outperforms the PPO baselines and decoupling strategies in terms of sample efficiency and final rewards. Thus our model can efficiently deal with tasks in high dimensions and facilitate training real-life robots directly from scratch.
Physically-Consistent Generative Adversarial Networks for Coastal Flood Visualization
May 05, 2021
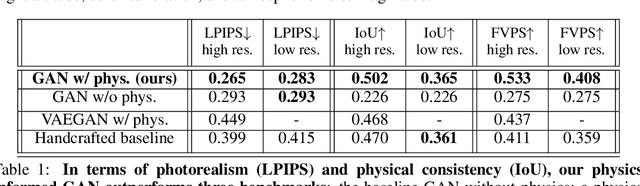
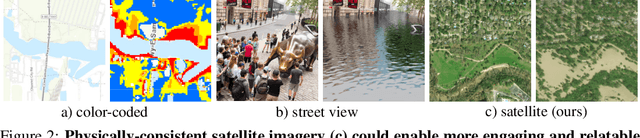
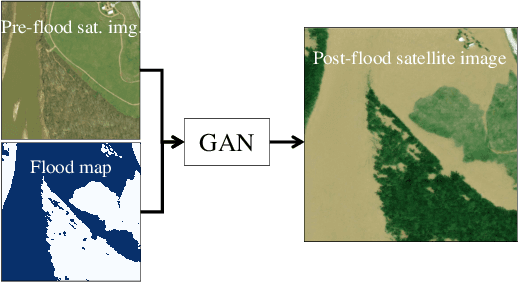
As climate change increases the intensity of natural disasters, society needs better tools for adaptation. Floods, for example, are the most frequent natural disaster, and better tools for flood risk communication could increase the support for flood-resilient infrastructure development. Our work aims to enable more visual communication of large-scale climate impacts via visualizing the output of coastal flood models as satellite imagery. We propose the first deep learning pipeline to ensure physical-consistency in synthetic visual satellite imagery. We advanced a state-of-the-art GAN called pix2pixHD, such that it produces imagery that is physically-consistent with the output of an expert-validated storm surge model (NOAA SLOSH). By evaluating the imagery relative to physics-based flood maps, we find that our proposed framework outperforms baseline models in both physical-consistency and photorealism. We envision our work to be the first step towards a global visualization of how climate change shapes our landscape. Continuing on this path, we show that the proposed pipeline generalizes to visualize arctic sea ice melt. We also publish a dataset of over 25k labelled image-pairs to study image-to-image translation in Earth observation.