 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill or Skip? Learning Selective Skill Invocation in Agentic Tasks via Dual-Granularity Preference Learning
May 30, 2026Agent skills are callable procedural modules that provide reusable knowledge and execution policies for complex agentic tasks. However, existing methods mainly focus on selecting relevant skills or improving the skills themselves, while overlooking whether a relevant skill should actually be invoked at the current decision point. Unhelpful invocations may introduce irrelevant context and disrupt an otherwise correct execution process. To address this issue, we propose SelSkill, a dual-granularity preference-learning framework for selective skill invocation. SelSkill formulates skill use as a skill-or-skip decision, uses predictive uncertainty to prioritize candidate decision points, and constructs controlled invoke-skip preference pairs from shared trajectory prefixes. It further combines episode-level outcome preferences with step-level invocation preferences to capture both overall trajectory quality and the local effectiveness of skill invocation. On ALFWorld with Qwen3-8B, SelSkill improves task success by 10.9 percentage points and execution precision by 29.1 percentage points. On BFCL, it improves task success by 5.7 percentage points and execution precision by 29.5 percentage points. Zero-shot results on Tau-bench and PopQA further suggest that the learned invocation policy transfers to new domains with previously unseen skills.
StreamMeCo: Long-Term Agent Memory Compression for Efficient Streaming Video Understanding
Apr 10, 2026Vision agent memory has shown remarkable effectiveness in streaming video understanding. However, storing such memory for videos incurs substantial memory overhead, leading to high costs in both storage and computation. To address this issue, we propose StreamMeCo, an efficient Stream Agent Memory Compression framework. Specifically, based on the connectivity of the memory graph, StreamMeCo introduces edge-free minmax sampling for the isolated nodes and an edge-aware weight pruning for connected nodes, evicting the redundant memory nodes while maintaining the accuracy. In addition, we introduce a time-decay memory retrieval mechanism to further eliminate the performance degradation caused by memory compression. Extensive experiments on three challenging benchmark datasets (M3-Bench-robot, M3-Bench-web and Video-MME-Long) demonstrate that under 70% memory graph compression, StreamMeCo achieves a 1.87* speedup in memory retrieval while delivering an average accuracy improvement of 1.0%. Our code is available at https://github.com/Celina-love-sweet/StreamMeCo.
Evolving Beyond Snapshots: Harmonizing Structure and Sequence via Entity State Tuning for Temporal Knowledge Graph Forecasting
Feb 12, 2026Temporal knowledge graph (TKG) forecasting requires predicting future facts by jointly modeling structural dependencies within each snapshot and temporal evolution across snapshots. However, most existing methods are stateless: they recompute entity representations at each timestamp from a limited query window, leading to episodic amnesia and rapid decay of long-term dependencies. To address this limitation, we propose Entity State Tuning (EST), an encoder-agnostic framework that endows TKG forecasters with persistent and continuously evolving entity states. EST maintains a global state buffer and progressively aligns structural evidence with sequential signals via a closed-loop design. Specifically, a topology-aware state perceiver first injects entity-state priors into structural encoding. Then, a unified temporal context module aggregates the state-enhanced events with a pluggable sequence backbone. Subsequently, a dual-track evolution mechanism writes the updated context back to the global entity state memory, balancing plasticity against stability. Experiments on multiple benchmarks show that EST consistently improves diverse backbones and achieves state-of-the-art performance, highlighting the importance of state persistence for long-horizon TKG forecasting. The code is published at https://github.com/yuanwuyuan9/Evolving-Beyond-Snapshots
Efficient State Representation Learning for Dynamic Robotic Scenarios
Sep 17, 2021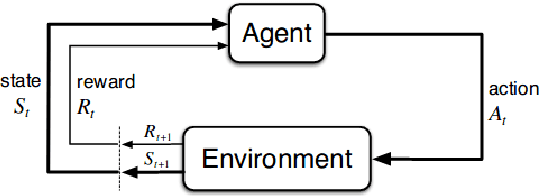
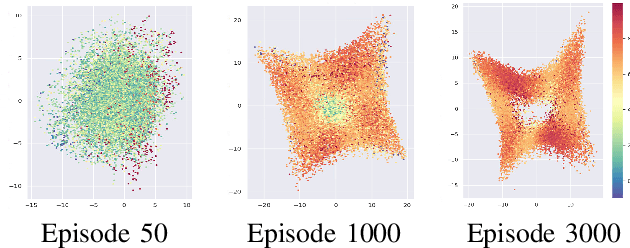
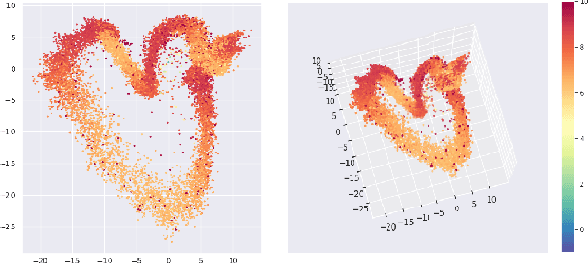
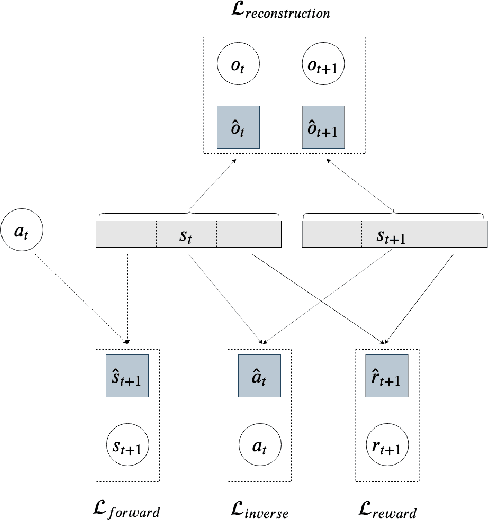
While the rapid progress of deep learning fuels end-to-end reinforcement learning (RL), direct application, especially in high-dimensional space like robotic scenarios still suffers from high sample efficiency. Therefore State Representation Learning (SRL) is proposed to specifically learn to encode task-relevant features from complex sensory data into low-dimensional states. However, the pervasive implementation of SRL is usually conducted by a decoupling strategy in which the observation-state mapping is learned separately, which is prone to over-fit. To handle such problem, we present a new algorithm called Policy Optimization via Abstract Representation which integrates SRL into the original RL scale. Firstly, We engage RL loss to assist in updating SRL model so that the states can evolve to meet the demand of reinforcement learning and maintain a good physical interpretation. Secondly, we introduce a dynamic parameter adjustment mechanism so that both models can efficiently adapt to each other. Thirdly, we introduce a new prior called domain resemblance to leverage expert demonstration to train the SRL model. Finally, we provide a real-time access by state graph to monitor the course of learning. Results show that our algorithm outperforms the PPO baselines and decoupling strategies in terms of sample efficiency and final rewards. Thus our model can efficiently deal with tasks in high dimensions and facilitate training real-life robots directly from scratch.
Exploration-efficient Deep Reinforcement Learning with Demonstration Guidance for Robot Control
Feb 27, 2020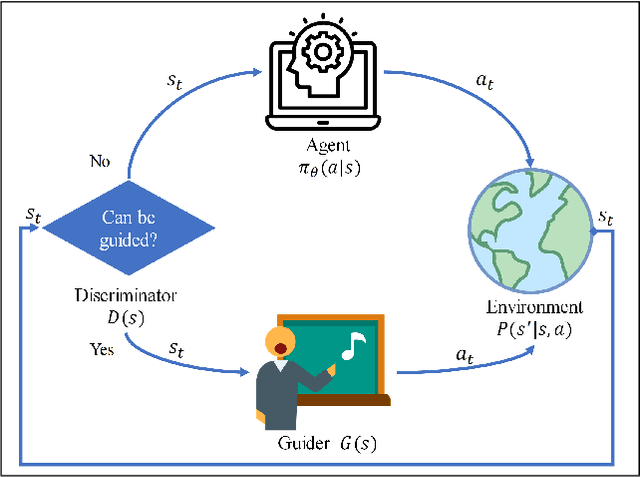

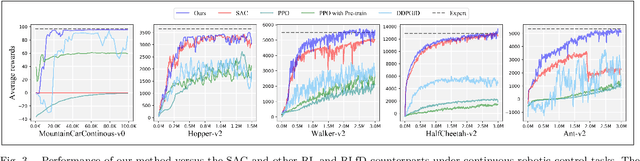
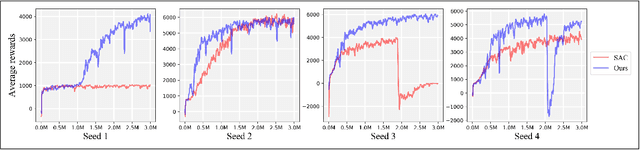
Although deep reinforcement learning (DRL) algorithms have made important achievements in many control tasks, they still suffer from the problems of sample inefficiency and unstable training process, which are usually caused by sparse rewards. Recently, some reinforcement learning from demonstration (RLfD) methods have shown to be promising in overcoming these problems. However, they usually require considerable demonstrations. In order to tackle these challenges, on the basis of the SAC algorithm we propose a sample efficient DRL-EG (DRL with efficient guidance) algorithm, in which a discriminator D(s) and a guider G(s) are modeled by a small number of expert demonstrations. The discriminator will determine the appropriate guidance states and the guider will guide agents to better exploration in the training phase. Empirical evaluation results from several continuous control tasks verify the effectiveness and performance improvements of our method over other RL and RLfD counterparts. Experiments results also show that DRL-EG can help the agent to escape from a local optimum.
DisCoRL: Continual Reinforcement Learning via Policy Distillation
Jul 11, 2019
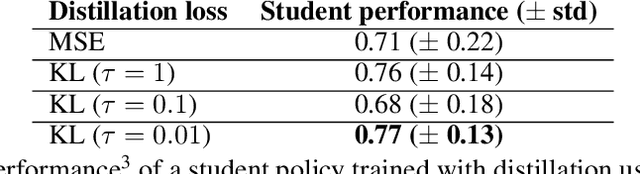
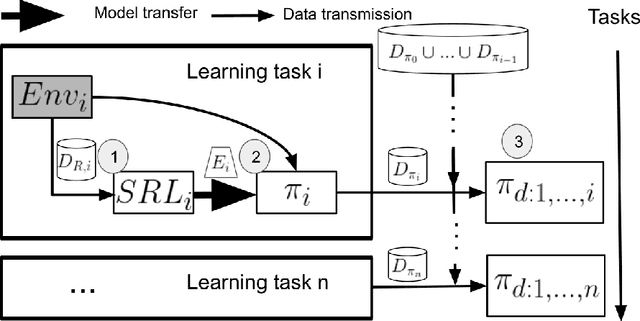
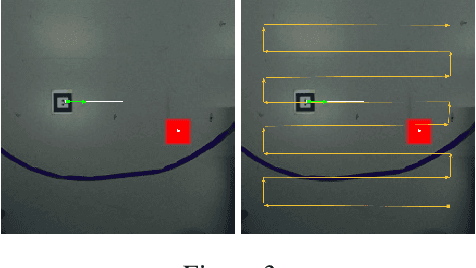
In multi-task reinforcement learning there are two main challenges: at training time, the ability to learn different policies with a single model; at test time, inferring which of those policies applying without an external signal. In the case of continual reinforcement learning a third challenge arises: learning tasks sequentially without forgetting the previous ones. In this paper, we tackle these challenges by proposing DisCoRL, an approach combining state representation learning and policy distillation. We experiment on a sequence of three simulated 2D navigation tasks with a 3 wheel omni-directional robot. Moreover, we tested our approach's robustness by transferring the final policy into a real life setting. The policy can solve all tasks and automatically infer which one to run.
Continual Reinforcement Learning deployed in Real-life using Policy Distillation and Sim2Real Transfer
Jun 11, 2019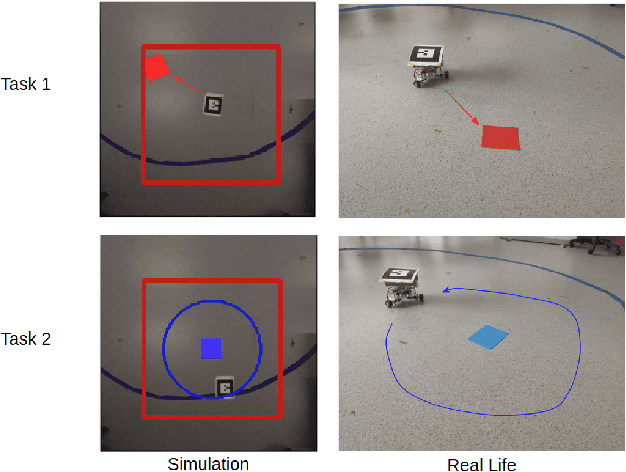
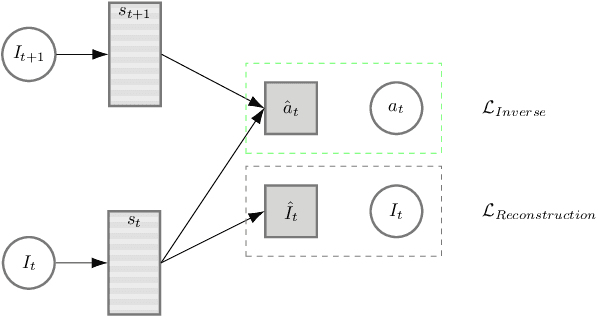
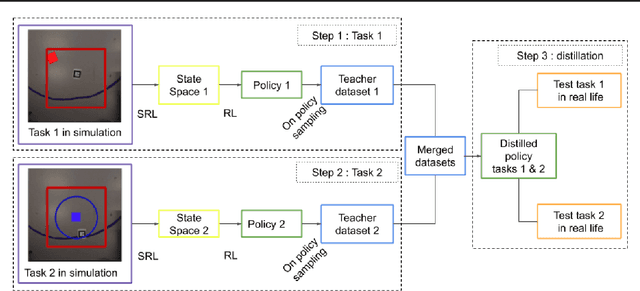
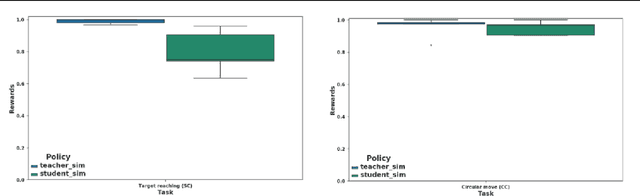
We focus on the problem of teaching a robot to solve tasks presented sequentially, i.e., in a continual learning scenario. The robot should be able to solve all tasks it has encountered, without forgetting past tasks. We provide preliminary work on applying Reinforcement Learning to such setting, on 2D navigation tasks for a 3 wheel omni-directional robot. Our approach takes advantage of state representation learning and policy distillation. Policies are trained using learned features as input, rather than raw observations, allowing better sample efficiency. Policy distillation is used to combine multiple policies into a single one that solves all encountered tasks.