 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Minimum-Volume Confidence Set Intersection for Multinomial Outcomes
Jan 26, 2026Computation of confidence sets is central to data science and machine learning, serving as the workhorse of A/B testing and underpinning the operation and analysis of reinforcement learning algorithms. Among all valid confidence sets for the multinomial parameter, minimum-volume confidence sets (MVCs) are optimal in that they minimize average volume, but they are defined as level sets of an exact p-value that is discontinuous and difficult to compute. Rather than attempting to characterize the geometry of MVCs directly, this paper studies a practically motivated decision problem: given two observed multinomial outcomes, can one certify whether their MVCs intersect? We present a certified, tolerance-aware algorithm for this intersection problem. The method exploits the fact that likelihood ordering induces halfspace constraints in log-odds coordinates, enabling adaptive geometric partitioning of parameter space and computable lower and upper bounds on p-values over each cell. For three categories, this yields an efficient and provably sound algorithm that either certifies intersection, certifies disjointness, or returns an indeterminate result when the decision lies within a prescribed margin. We further show how the approach extends to higher dimensions. The results demonstrate that, despite their irregular geometry, MVCs admit reliable certified decision procedures for core tasks in A/B testing.
A latent linear model for nonlinear coupled oscillators on graphs
Nov 25, 2023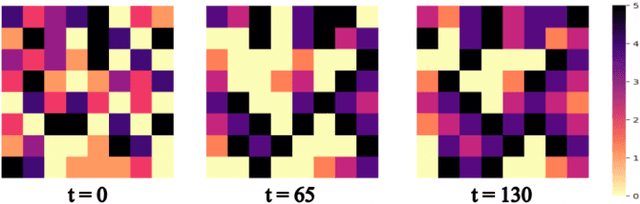
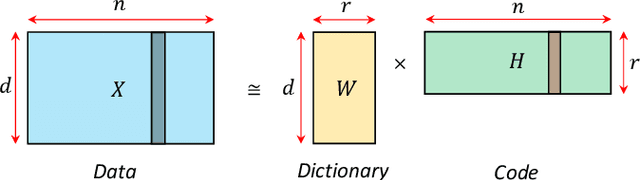
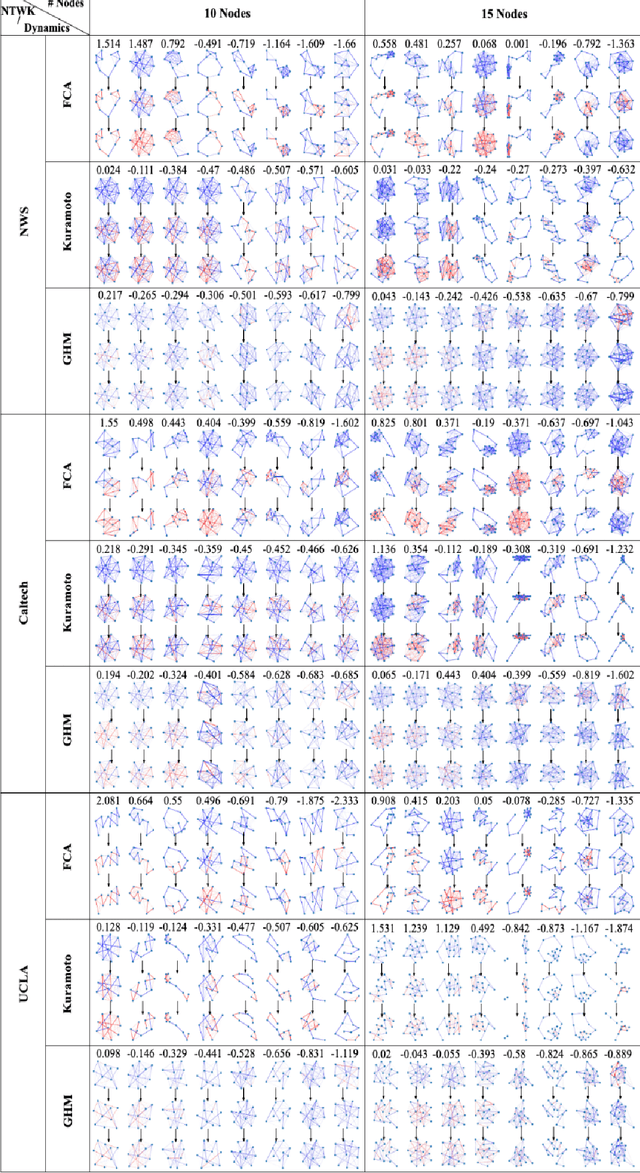
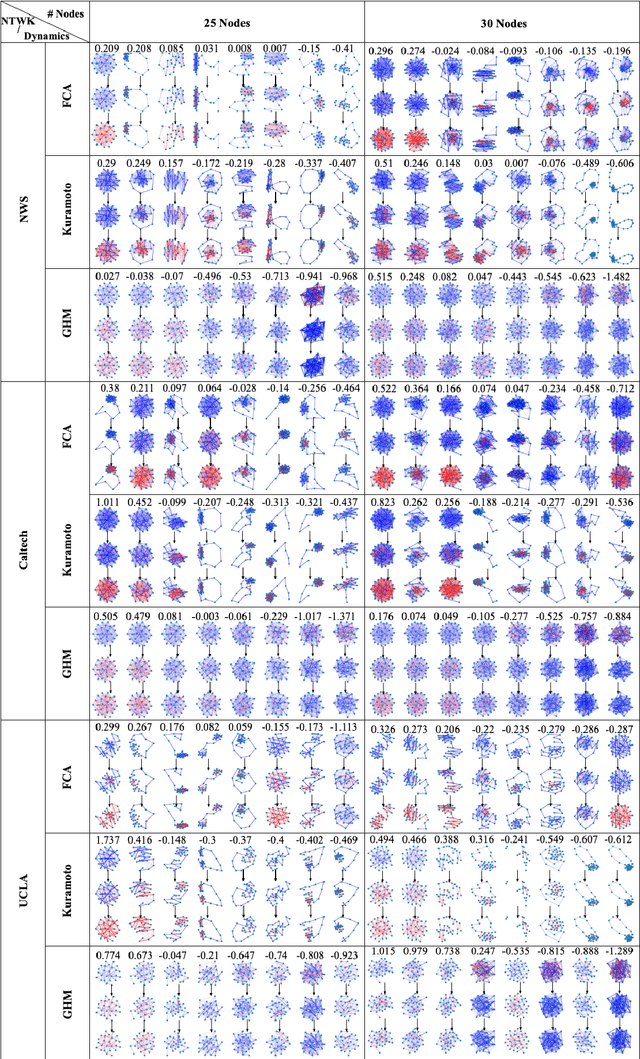
A system of coupled oscillators on an arbitrary graph is locally driven by the tendency to mutual synchronization between nearby oscillators, but can and often exhibit nonlinear behavior on the whole graph. Understanding such nonlinear behavior has been a key challenge in predicting whether all oscillators in such a system will eventually synchronize. In this paper, we demonstrate that, surprisingly, such nonlinear behavior of coupled oscillators can be effectively linearized in certain latent dynamic spaces. The key insight is that there is a small number of `latent dynamics filters', each with a specific association with synchronizing and non-synchronizing dynamics on subgraphs so that any observed dynamics on subgraphs can be approximated by a suitable linear combination of such elementary dynamic patterns. Taking an ensemble of subgraph-level predictions provides an interpretable predictor for whether the system on the whole graph reaches global synchronization. We propose algorithms based on supervised matrix factorization to learn such latent dynamics filters. We demonstrate that our method performs competitively in synchronization prediction tasks against baselines and black-box classification algorithms, despite its simple and interpretable architecture.
Progressive Adaptive Chance-Constrained Safeguards for Reinforcement Learning
Oct 05, 2023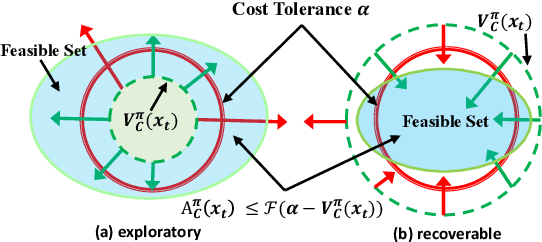
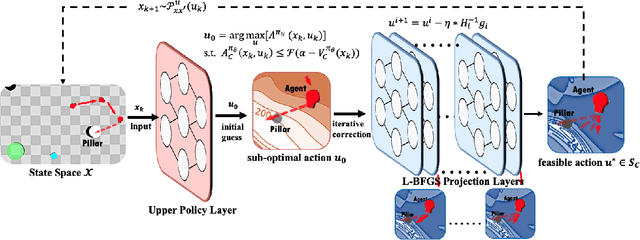


Safety assurance of Reinforcement Learning (RL) is critical for exploration in real-world scenarios. In handling the Constrained Markov Decision Process, current approaches experience intrinsic difficulties in trading-off between optimality and feasibility. Direct optimization methods cannot strictly guarantee state-wise in-training safety while projection-based methods are usually inefficient and correct actions through lengthy iterations. To address these two challenges, this paper proposes an adaptive surrogate chance constraint for the safety cost, and a hierarchical architecture that corrects actions produced by the upper policy layer via a fast Quasi-Newton method. Theoretical analysis indicates that the relaxed probabilistic constraint can sufficiently guarantee forward invariance to the safe set. We validate the proposed method on 4 simulated and real-world safety-critical robotic tasks. Results indicate that the proposed method can efficiently enforce safety (nearly zero-violation), while preserving optimality (+23.8%), robustness and generalizability to stochastic real-world settings.
Efficiently Training On-Policy Actor-Critic Networks in Robotic Deep Reinforcement Learning with Demonstration-like Sampled Exploration
Sep 27, 2021

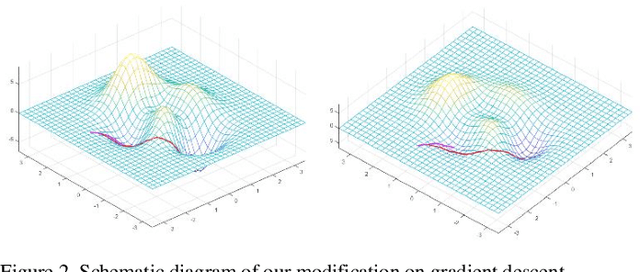
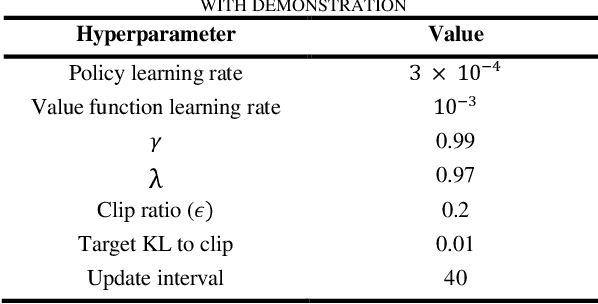
In complex environments with high dimension, training a reinforcement learning (RL) model from scratch often suffers from lengthy and tedious collection of agent-environment interactions. Instead, leveraging expert demonstration to guide RL agent can boost sample efficiency and improve final convergence. In order to better integrate expert prior with on-policy RL models, we propose a generic framework for Learning from Demonstration (LfD) based on actor-critic algorithms. Technically, we first employ K-Means clustering to evaluate the similarity of sampled exploration with demonstration data. Then we increase the likelihood of actions in similar frames by modifying the gradient update strategy to leverage demonstration. We conduct experiments on 4 standard benchmark environments in Mujoco and 2 self-designed robotic environments. Results show that, under certain condition, our algorithm can improve sample efficiency by 20% ~ 40%. By combining our framework with on-policy algorithms, RL models can accelerate convergence and obtain better final mean episode rewards especially in complex robotic context where interactions are expensive.
Efficient State Representation Learning for Dynamic Robotic Scenarios
Sep 17, 2021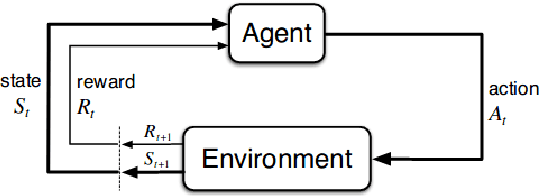
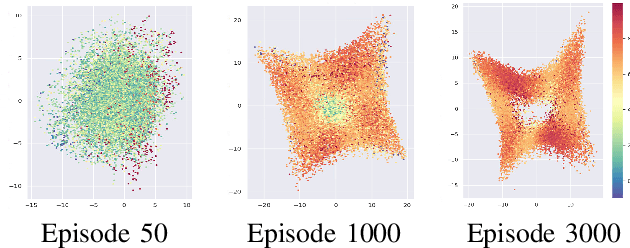
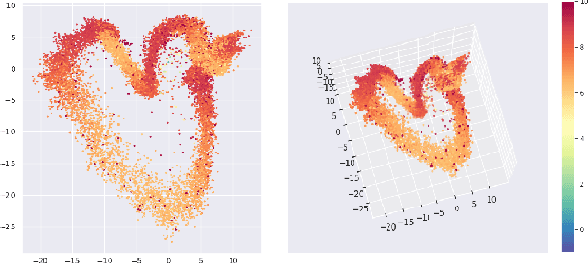
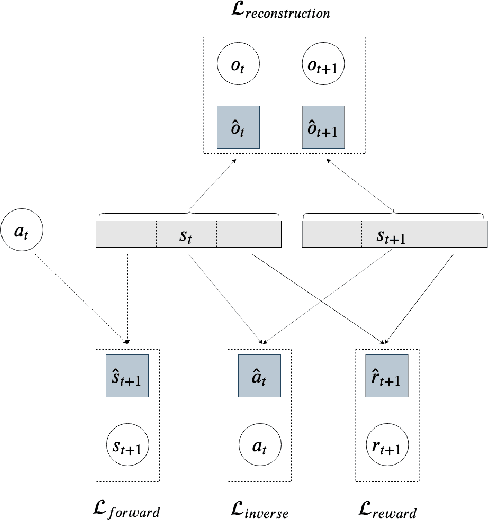
While the rapid progress of deep learning fuels end-to-end reinforcement learning (RL), direct application, especially in high-dimensional space like robotic scenarios still suffers from high sample efficiency. Therefore State Representation Learning (SRL) is proposed to specifically learn to encode task-relevant features from complex sensory data into low-dimensional states. However, the pervasive implementation of SRL is usually conducted by a decoupling strategy in which the observation-state mapping is learned separately, which is prone to over-fit. To handle such problem, we present a new algorithm called Policy Optimization via Abstract Representation which integrates SRL into the original RL scale. Firstly, We engage RL loss to assist in updating SRL model so that the states can evolve to meet the demand of reinforcement learning and maintain a good physical interpretation. Secondly, we introduce a dynamic parameter adjustment mechanism so that both models can efficiently adapt to each other. Thirdly, we introduce a new prior called domain resemblance to leverage expert demonstration to train the SRL model. Finally, we provide a real-time access by state graph to monitor the course of learning. Results show that our algorithm outperforms the PPO baselines and decoupling strategies in terms of sample efficiency and final rewards. Thus our model can efficiently deal with tasks in high dimensions and facilitate training real-life robots directly from scratch.
Exploration-efficient Deep Reinforcement Learning with Demonstration Guidance for Robot Control
Feb 27, 2020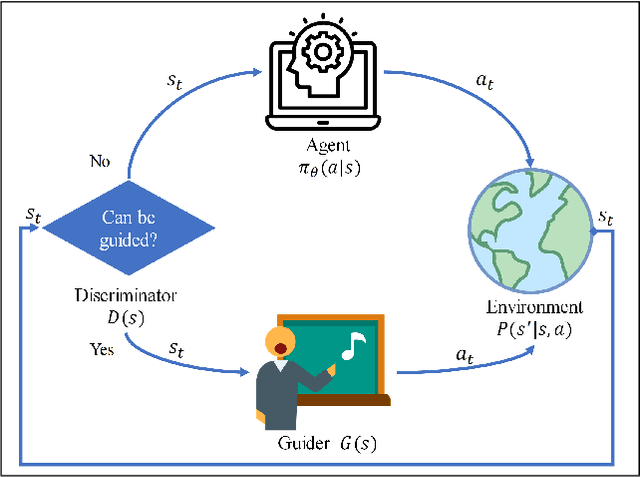

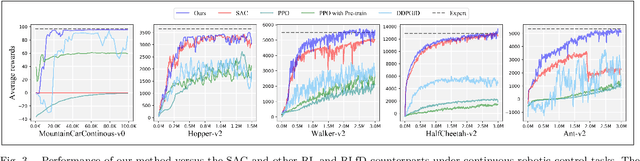
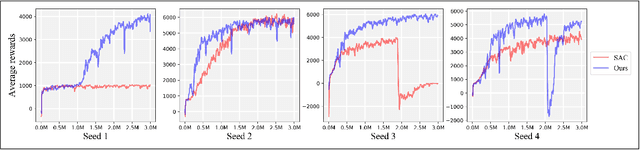
Although deep reinforcement learning (DRL) algorithms have made important achievements in many control tasks, they still suffer from the problems of sample inefficiency and unstable training process, which are usually caused by sparse rewards. Recently, some reinforcement learning from demonstration (RLfD) methods have shown to be promising in overcoming these problems. However, they usually require considerable demonstrations. In order to tackle these challenges, on the basis of the SAC algorithm we propose a sample efficient DRL-EG (DRL with efficient guidance) algorithm, in which a discriminator D(s) and a guider G(s) are modeled by a small number of expert demonstrations. The discriminator will determine the appropriate guidance states and the guider will guide agents to better exploration in the training phase. Empirical evaluation results from several continuous control tasks verify the effectiveness and performance improvements of our method over other RL and RLfD counterparts. Experiments results also show that DRL-EG can help the agent to escape from a local optimum.