 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO-VO: Learning Where to Focus for Enhanced State Estimation
Apr 05, 2026We present DINO Patch Visual Odometry (DINO-VO), an end-to-end monocular visual odometry system with strong scene generalization. Current Visual Odometry (VO) systems often rely on heuristic feature extraction strategies, which can degrade accuracy and robustness, particularly in large-scale outdoor environments. DINO-VO addresses these limitations by incorporating a differentiable adaptive patch selector into the end-to-end pipeline, improving the quality of extracted patches and enhancing generalization across diverse datasets. Additionally, our system integrates a multi-task feature extraction module with a differentiable bundle adjustment (BA) module that leverages inverse depth priors, enabling the system to learn and utilize appearance and geometric information effectively. This integration bridges the gap between feature learning and state estimation. Extensive experiments on the TartanAir, KITTI, Euroc, and TUM datasets demonstrate that DINO-VO exhibits strong generalization across synthetic, indoor, and outdoor environments, achieving state-of-the-art tracking accuracy.
MacTok: Robust Continuous Tokenization for Image Generation
Mar 31, 2026Continuous image tokenizers enable efficient visual generation, and those based on variational frameworks can learn smooth, structured latent representations through KL regularization. Yet this often leads to posterior collapse when using fewer tokens, where the encoder fails to encode informative features into the compressed latent space. To address this, we introduce \textbf{MacTok}, a \textbf{M}asked \textbf{A}ugmenting 1D \textbf{C}ontinuous \textbf{Tok}enizer that leverages image masking and representation alignment to prevent collapse while learning compact and robust representations. MacTok applies both random masking to regularize latent learning and DINO-guided semantic masking to emphasize informative regions in images, forcing the model to encode robust semantics from incomplete visual evidence. Combined with global and local representation alignment, MacTok preserves rich discriminative information in a highly compressed 1D latent space, requiring only 64 or 128 tokens. On ImageNet, MacTok achieves a competitive gFID of 1.44 at 256$\times$256 and a state-of-the-art 1.52 at 512$\times$512 with SiT-XL, while reducing token usage by up to 64$\times$. These results confirm that masking and semantic guidance together prevent posterior collapse and achieve efficient, high-fidelity tokenization.
GIFT: Global Irreplaceability Frame Targeting for Efficient Video Understanding
Mar 26, 2026Video Large Language Models (VLMs) have achieved remarkable success in video understanding, but the significant computational cost from processing dense frames severely limits their practical application. Existing methods alleviate this by selecting keyframes, but their greedy decision-making, combined with a decoupled evaluation of relevance and diversity, often falls into local optima and results in erroneously selecting irrelevant noise frames. To address these challenges, we propose GIFT: Global Irreplaceability Frame Targeting, a novel training-free framework that selects frames by assessing their intrinsic irreplaceability. Specifically, we first introduce Directed Diversity to quantify a frame's uniqueness conditioned on relevance, which allows us to formulate a unified irreplaceability score. Subsequently, our Budget-Aware Refinement strategy employs a adaptive iterative process that first secures a core set of frames with the highest irreplaceability, and then shifts its priority to building crucial temporal context around these selections as the budget expands. Extensive experiments demonstrate that GIFT achieves a maximum average improvement of 12.5% across long-form video benchmarks on LLaVA-Video-7B compared to uniform sampling.
CausalVAD: De-confounding End-to-End Autonomous Driving via Causal Intervention
Mar 19, 2026Planning-oriented end-to-end driving models show great promise, yet they fundamentally learn statistical correlations instead of true causal relationships. This vulnerability leads to causal confusion, where models exploit dataset biases as shortcuts, critically harming their reliability and safety in complex scenarios. To address this, we introduce CausalVAD, a de-confounding training framework that leverages causal intervention. At its core, we design the sparse causal intervention scheme (SCIS), a lightweight, plug-and-play module to instantiate the backdoor adjustment theory in neural networks. SCIS constructs a dictionary of prototypes representing latent driving contexts. It then uses this dictionary to intervene on the model's sparse vectorized queries. This step actively eliminates spurious associations induced by confounders, thereby eliminating spurious factors from the representations for downstream tasks. Extensive experiments on benchmarks like nuScenes show CausalVAD achieves state-of-the-art planning accuracy and safety. Furthermore, our method demonstrates superior robustness against both data bias and noisy scenarios configured to induce causal confusion.
DynamicVGGT: Learning Dynamic Point Maps for 4D Scene Reconstruction in Autonomous Driving
Mar 09, 2026Dynamic scene reconstruction in autonomous driving remains a fundamental challenge due to significant temporal variations, moving objects, and complex scene dynamics. Existing feed-forward 3D models have demonstrated strong performance in static reconstruction but still struggle to capture dynamic motion. To address these limitations, we propose DynamicVGGT, a unified feed-forward framework that extends VGGT from static 3D perception to dynamic 4D reconstruction. Our goal is to model point motion within feed-forward 3D models in a dynamic and temporally coherent manner. To this end, we jointly predict the current and future point maps within a shared reference coordinate system, allowing the model to implicitly learn dynamic point representations through temporal correspondence. To efficiently capture temporal dependencies, we introduce a Motion-aware Temporal Attention (MTA) module that learns motion continuity. Furthermore, we design a Dynamic 3D Gaussian Splatting Head that explicitly models point motion by predicting Gaussian velocities using learnable motion tokens under scene flow supervision. It refines dynamic geometry through continuous 3D Gaussian optimization. Extensive experiments on autonomous driving datasets demonstrate that DynamicVGGT significantly outperforms existing methods in reconstruction accuracy, achieving robust feed-forward 4D dynamic scene reconstruction under complex driving scenarios.
Vision-Language Feature Alignment for Road Anomaly Segmentation
Mar 01, 2026Safe autonomous systems in complex environments require robust road anomaly segmentation to identify unknown obstacles. However, existing approaches often rely on pixel-level statistics to determine whether a region appears anomalous. This reliance leads to high false-positive rates on semantically normal background regions such as sky or vegetation, and poor recall of true Out-of-distribution (OOD) instances, thereby posing safety risks for robotic perception and decision-making. To address these challenges, we propose VL-Anomaly, a vision-language anomaly segmentation framework that incorporates semantic priors from pre-trained Vision-Language Models (VLMs). Specifically, we design a prompt learning-driven alignment module that adapts Mask2Forme's visual features to CLIP text embeddings of known categories, effectively suppressing spurious anomaly responses in background regions. At inference time, we further introduce a multi-source inference strategy that integrates text-guided similarity, CLIP-based image-text similarity and detector confidence, enabling more reliable anomaly prediction by leveraging complementary information sources. Extensive experiments demonstrate that VL-Anomaly achieves state-of-the-art performance on benchmark datasets including RoadAnomaly, SMIYC and Fishyscapes.Code is released on https://github.com/NickHezhuolin/VL-aligner-Road-anomaly-segment.
Decoupling Scene Perception and Ego Status: A Multi-Context Fusion Approach for Enhanced Generalization in End-to-End Autonomous Driving
Nov 18, 2025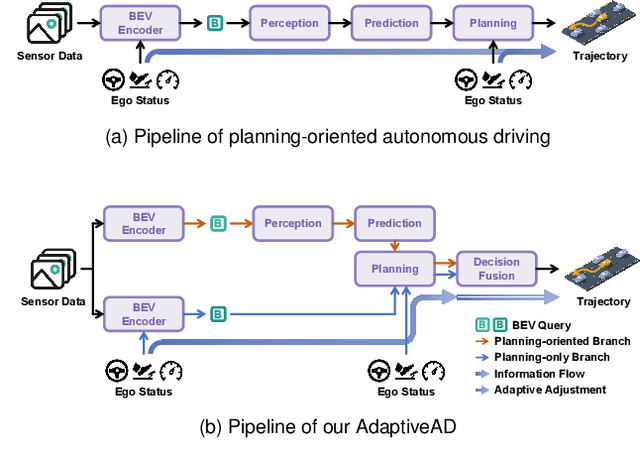
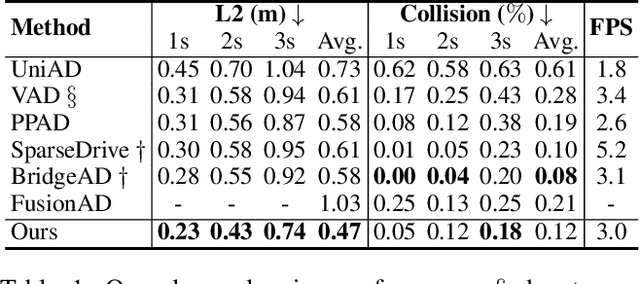
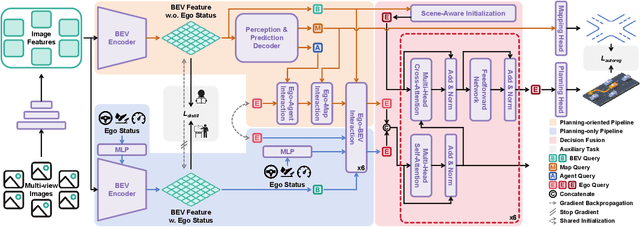
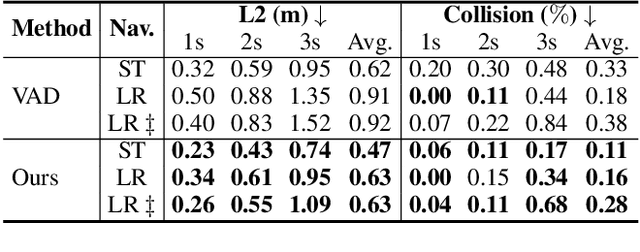
Modular design of planning-oriented autonomous driving has markedly advanced end-to-end systems. However, existing architectures remain constrained by an over-reliance on ego status, hindering generalization and robust scene understanding. We identify the root cause as an inherent design within these architectures that allows ego status to be easily leveraged as a shortcut. Specifically, the premature fusion of ego status in the upstream BEV encoder allows an information flow from this strong prior to dominate the downstream planning module. To address this challenge, we propose AdaptiveAD, an architectural-level solution based on a multi-context fusion strategy. Its core is a dual-branch structure that explicitly decouples scene perception and ego status. One branch performs scene-driven reasoning based on multi-task learning, but with ego status deliberately omitted from the BEV encoder, while the other conducts ego-driven reasoning based solely on the planning task. A scene-aware fusion module then adaptively integrates the complementary decisions from the two branches to form the final planning trajectory. To ensure this decoupling does not compromise multi-task learning, we introduce a path attention mechanism for ego-BEV interaction and add two targeted auxiliary tasks: BEV unidirectional distillation and autoregressive online mapping. Extensive evaluations on the nuScenes dataset demonstrate that AdaptiveAD achieves state-of-the-art open-loop planning performance. Crucially, it significantly mitigates the over-reliance on ego status and exhibits impressive generalization capabilities across diverse scenarios.
Learning Global Representation from Queries for Vectorized HD Map Construction
Oct 08, 2025The online construction of vectorized high-definition (HD) maps is a cornerstone of modern autonomous driving systems. State-of-the-art approaches, particularly those based on the DETR framework, formulate this as an instance detection problem. However, their reliance on independent, learnable object queries results in a predominantly local query perspective, neglecting the inherent global representation within HD maps. In this work, we propose \textbf{MapGR} (\textbf{G}lobal \textbf{R}epresentation learning for HD \textbf{Map} construction), an architecture designed to learn and utilize a global representations from queries. Our method introduces two synergistic modules: a Global Representation Learning (GRL) module, which encourages the distribution of all queries to better align with the global map through a carefully designed holistic segmentation task, and a Global Representation Guidance (GRG) module, which endows each individual query with explicit, global-level contextual information to facilitate its optimization. Evaluations on the nuScenes and Argoverse2 datasets validate the efficacy of our approach, demonstrating substantial improvements in mean Average Precision (mAP) compared to leading baselines.
Dark-ISP: Enhancing RAW Image Processing for Low-Light Object Detection
Sep 11, 2025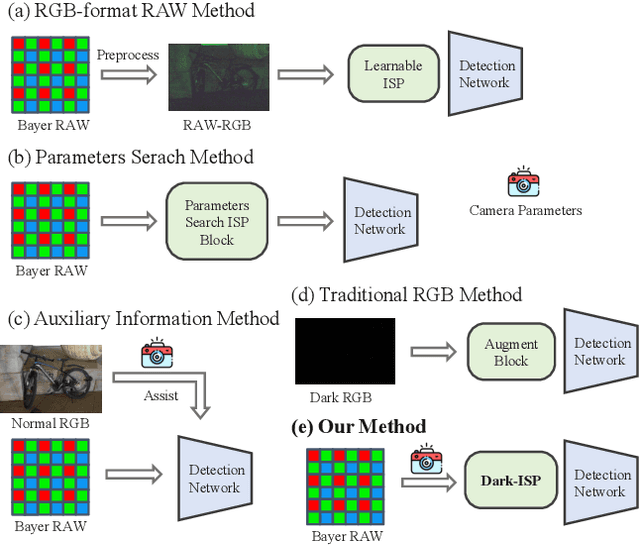
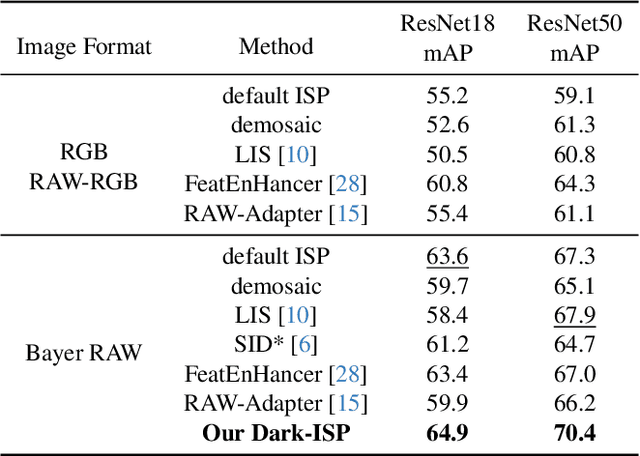
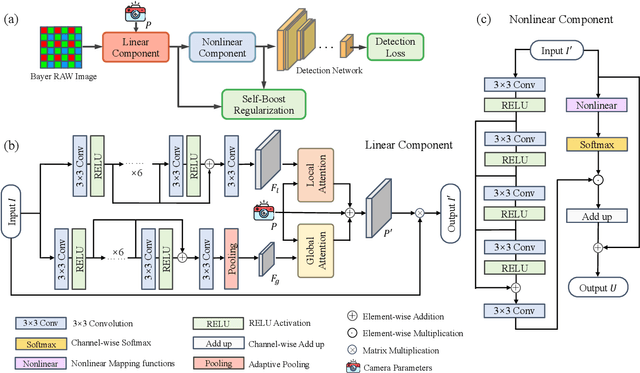
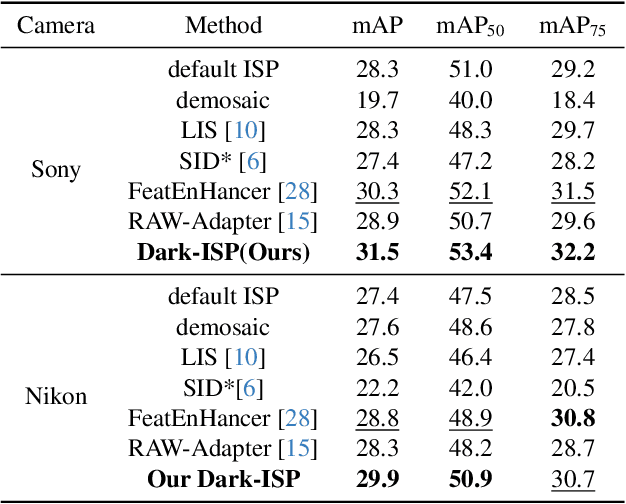
Low-light Object detection is crucial for many real-world applications but remains challenging due to degraded image quality. While recent studies have shown that RAW images offer superior potential over RGB images, existing approaches either use RAW-RGB images with information loss or employ complex frameworks. To address these, we propose a lightweight and self-adaptive Image Signal Processing (ISP) plugin, Dark-ISP, which directly processes Bayer RAW images in dark environments, enabling seamless end-to-end training for object detection. Our key innovations are: (1) We deconstruct conventional ISP pipelines into sequential linear (sensor calibration) and nonlinear (tone mapping) sub-modules, recasting them as differentiable components optimized through task-driven losses. Each module is equipped with content-aware adaptability and physics-informed priors, enabling automatic RAW-to-RGB conversion aligned with detection objectives. (2) By exploiting the ISP pipeline's intrinsic cascade structure, we devise a Self-Boost mechanism that facilitates cooperation between sub-modules. Through extensive experiments on three RAW image datasets, we demonstrate that our method outperforms state-of-the-art RGB- and RAW-based detection approaches, achieving superior results with minimal parameters in challenging low-light environments.
* 11 pages, 6 figures, conference
FA-BARF: Frequency Adapted Bundle-Adjusting Neural Radiance Fields
Mar 15, 2025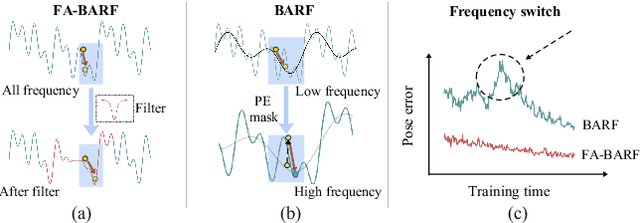
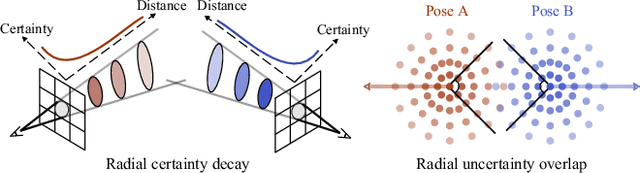
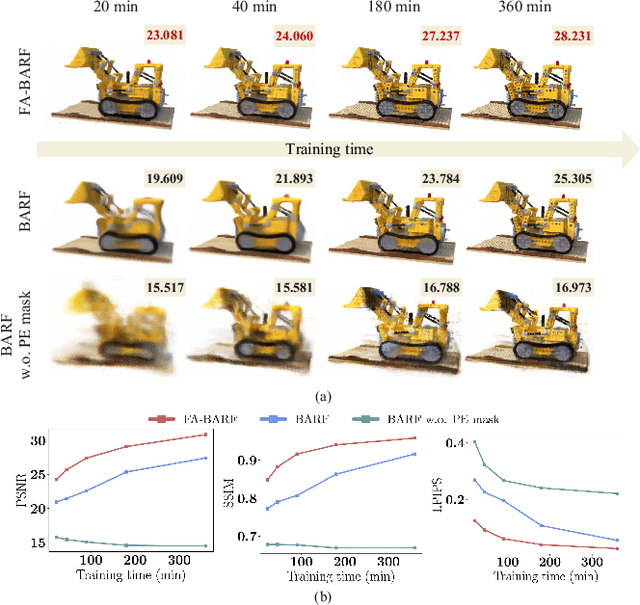
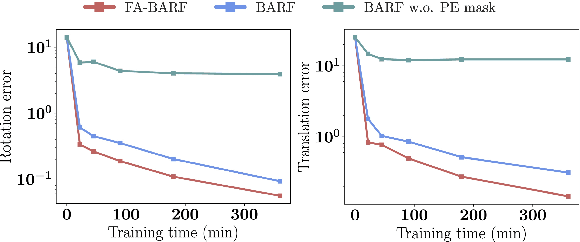
Neural Radiance Fields (NeRF) have exhibited highly effective performance for photorealistic novel view synthesis recently. However, the key limitation it meets is the reliance on a hand-crafted frequency annealing strategy to recover 3D scenes with imperfect camera poses. The strategy exploits a temporal low-pass filter to guarantee convergence while decelerating the joint optimization of implicit scene reconstruction and camera registration. In this work, we introduce the Frequency Adapted Bundle Adjusting Radiance Field (FA-BARF), substituting the temporal low-pass filter for a frequency-adapted spatial low-pass filter to address the decelerating problem. We establish a theoretical framework to interpret the relationship between position encoding of NeRF and camera registration and show that our frequency-adapted filter can mitigate frequency fluctuation caused by the temporal filter. Furthermore, we show that applying a spatial low-pass filter in NeRF can optimize camera poses productively through radial uncertainty overlaps among various views. Extensive experiments show that FA-BARF can accelerate the joint optimization process under little perturbations in object-centric scenes and recover real-world scenes with unknown camera poses. This implies wider possibilities for NeRF applied in dense 3D mapping and reconstruction under real-time requirements. The code will be released upon paper acceptance.