 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiteVSR: Lightweight Adaptation of Frozen Diffusion Transformers for Video Super-Resolution
Jun 08, 2026Adapting large-scale pre-trained video generators for Video Super-Resolution (VSR) in novel domains remains computationally prohibitive. Methods that reformulate generation as direct Low-Quality to High-Quality mappings deviate from the original generative formulation, demanding extensive fine-tuning. ControlNet-style adapters lose their efficiency under modern Diffusion Transformers since the absence of encoder-decoder hierarchy forces duplication of the entire backbone. We observe that flow matching offers a principled alternative for cross-domain VSR adaptation. By predicting a constant velocity field across all timesteps, the adaptation task reduces to learning a fixed injection pattern rather than time-varying transformations. Building on this insight, we propose LiteVSR, a minimalist framework that performs VSR using a completely frozen Diffusion Transformer with a lightweight State-Aware Adapter. The adapter employs a dual-stream architecture that extracts static structural cues from the LQ input and dynamic cues from intermediate denoising states, aligning them through time-dependent cross-attention to enable adaptive transition from structural alignment to texture refinement as denoising proceeds. LiteVSR achieves competitive restoration quality with only 11.25% trainable parameters and 12 GPU-hours of training on a single A100, while maintaining fast sampling (down to a single step) compatibility.
LatSearch: Latent Reward-Guided Search for Faster Inference-Time Scaling in Video Diffusion
Mar 15, 2026The recent success of inference-time scaling in large language models has inspired similar explorations in video diffusion. In particular, motivated by the existence of "golden noise" that enhances video quality, prior work has attempted to improve inference by optimising or searching for better initial noise. However, these approaches have notable limitations: they either rely on priors imposed at the beginning of noise sampling or on rewards evaluated only on the denoised and decoded videos. This leads to error accumulation, delayed and sparse reward signals, and prohibitive computational cost, which prevents the use of stronger search algorithms. Crucially, stronger search algorithms are precisely what could unlock substantial gains in controllability, sample efficiency and generation quality for video diffusion, provided their computational cost can be reduced. To fill in this gap, we enable efficient inference-time scaling for video diffusion through latent reward guidance, which provides intermediate, informative and efficient feedback along the denoising trajectory. We introduce a latent reward model that scores partially denoised latents at arbitrary timesteps with respect to visual quality, motion quality, and text alignment. Building on this model, we propose LatSearch, a novel inference-time search mechanism that performs Reward-Guided Resampling and Pruning (RGRP). In the resampling stage, candidates are sampled according to reward-normalised probabilities to reduce over-reliance on the reward model. In the pruning stage, applied at the final scheduled step, only the candidate with the highest cumulative reward is retained, improving both quality and efficiency. We evaluate LatSearch on the VBench-2.0 benchmark and demonstrate that it consistently improves video generation across multiple evaluation dimensions compared to the baseline Wan2.1 model.
ParkingTwin: Training-Free Streaming 3D Reconstruction for Parking-Lot Digital Twins
Jan 20, 2026High-fidelity parking-lot digital twins provide essential priors for path planning, collision checking, and perception validation in Automated Valet Parking (AVP). Yet robot-oriented reconstruction faces a trilemma: sparse forward-facing views cause weak parallax and ill-posed geometry; dynamic occlusions and extreme lighting hinder stable texture fusion; and neural rendering typically needs expensive offline optimization, violating edge-side streaming constraints. We propose ParkingTwin, a training-free, lightweight system for online streaming 3D reconstruction. First, OSM-prior-driven geometric construction uses OpenStreetMap semantic topology to directly generate a metric-consistent TSDF, replacing blind geometric search with deterministic mapping and avoiding costly optimization. Second, geometry-aware dynamic filtering employs a quad-modal constraint field (normal/height/depth consistency) to reject moving vehicles and transient occlusions in real time. Third, illumination-robust fusion in CIELAB decouples luminance and chromaticity via adaptive L-channel weighting and depth-gradient suppression, reducing seams under abrupt lighting changes. ParkingTwin runs at 30+ FPS on an entry-level GTX 1660. On a 68,000 m^2 real-world dataset, it achieves SSIM 0.87 (+16.0%), delivers about 15x end-to-end speedup, and reduces GPU memory by 83.3% compared with state-of-the-art 3D Gaussian Splatting (3DGS) that typically requires high-end GPUs (RTX 4090D). The system outputs explicit triangle meshes compatible with Unity/Unreal digital-twin pipelines. Project page: https://mihoutao-liu.github.io/ParkingTwin/
Variable Impedance Control for Floating-Base Supernumerary Robotic Leg in Walking Assistance
Nov 15, 2025In human-robot systems, ensuring safety during force control in the presence of both internal and external disturbances is crucial. As a typical loosely coupled floating-base robot system, the supernumerary robotic leg (SRL) system is particularly susceptible to strong internal disturbances. To address the challenge posed by floating base, we investigated the dynamics model of the loosely coupled SRL and designed a hybrid position/force impedance controller to fit dynamic torque input. An efficient variable impedance control (VIC) method is developed to enhance human-robot interaction, particularly in scenarios involving external force disturbances. By dynamically adjusting impedance parameters, VIC improves the dynamic switching between rigidity and flexibility, so that it can adapt to unknown environmental disturbances in different states. An efficient real-time stability guaranteed impedance parameters generating network is specifically designed for the proposed SRL, to achieve shock mitigation and high rigidity supporting. Simulations and experiments validate the system's effectiveness, demonstrating its ability to maintain smooth signal transitions in flexible states while providing strong support forces in rigid states. This approach provides a practical solution for accommodating individual gait variations in interaction, and significantly advances the safety and adaptability of human-robot systems.
Multi-Joint Physics-Informed Deep Learning Framework for Time-Efficient Inverse Dynamics
Nov 14, 2025Time-efficient estimation of muscle activations and forces across multi-joint systems is critical for clinical assessment and assistive device control. However, conventional approaches are computationally expensive and lack a high-quality labeled dataset for multi-joint applications. To address these challenges, we propose a physics-informed deep learning framework that estimates muscle activations and forces directly from kinematics. The framework employs a novel Multi-Joint Cross-Attention (MJCA) module with Bidirectional Gated Recurrent Unit (BiGRU) layers to capture inter-joint coordination, enabling each joint to adaptively integrate motion information from others. By embedding multi-joint dynamics, inter-joint coupling, and external force interactions into the loss function, our Physics-Informed MJCA-BiGRU (PI-MJCA-BiGRU) delivers physiologically consistent predictions without labeled data while enabling time-efficient inference. Experimental validation on two datasets demonstrates that PI-MJCA-BiGRU achieves performance comparable to conventional supervised methods without requiring ground-truth labels, while the MJCA module significantly enhances inter-joint coordination modeling compared to other baseline architectures.
Mitigating Cross-modal Representation Bias for Multicultural Image-to-Recipe Retrieval
Oct 23, 2025Existing approaches for image-to-recipe retrieval have the implicit assumption that a food image can fully capture the details textually documented in its recipe. However, a food image only reflects the visual outcome of a cooked dish and not the underlying cooking process. Consequently, learning cross-modal representations to bridge the modality gap between images and recipes tends to ignore subtle, recipe-specific details that are not visually apparent but are crucial for recipe retrieval. Specifically, the representations are biased to capture the dominant visual elements, resulting in difficulty in ranking similar recipes with subtle differences in use of ingredients and cooking methods. The bias in representation learning is expected to be more severe when the training data is mixed of images and recipes sourced from different cuisines. This paper proposes a novel causal approach that predicts the culinary elements potentially overlooked in images, while explicitly injecting these elements into cross-modal representation learning to mitigate biases. Experiments are conducted on the standard monolingual Recipe1M dataset and a newly curated multilingual multicultural cuisine dataset. The results indicate that the proposed causal representation learning is capable of uncovering subtle ingredients and cooking actions and achieves impressive retrieval performance on both monolingual and multilingual multicultural datasets.
HDLxGraph: Bridging Large Language Models and HDL Repositories via HDL Graph Databases
May 21, 2025Large Language Models (LLMs) have demonstrated their potential in hardware design tasks, such as Hardware Description Language (HDL) generation and debugging. Yet, their performance in real-world, repository-level HDL projects with thousands or even tens of thousands of code lines is hindered. To this end, we propose HDLxGraph, a novel framework that integrates Graph Retrieval Augmented Generation (Graph RAG) with LLMs, introducing HDL-specific graph representations by incorporating Abstract Syntax Trees (ASTs) and Data Flow Graphs (DFGs) to capture both code graph view and hardware graph view. HDLxGraph utilizes a dual-retrieval mechanism that not only mitigates the limited recall issues inherent in similarity-based semantic retrieval by incorporating structural information, but also enhances its extensibility to various real-world tasks by a task-specific retrieval finetuning. Additionally, to address the lack of comprehensive HDL search benchmarks, we introduce HDLSearch, a multi-granularity evaluation dataset derived from real-world repository-level projects. Experimental results demonstrate that HDLxGraph significantly improves average search accuracy, debugging efficiency and completion quality by 12.04%, 12.22% and 5.04% compared to similarity-based RAG, respectively. The code of HDLxGraph and collected HDLSearch benchmark are available at https://github.com/Nick-Zheng-Q/HDLxGraph.
NTIRE 2025 Challenge on Efficient Burst HDR and Restoration: Datasets, Methods, and Results
May 17, 2025
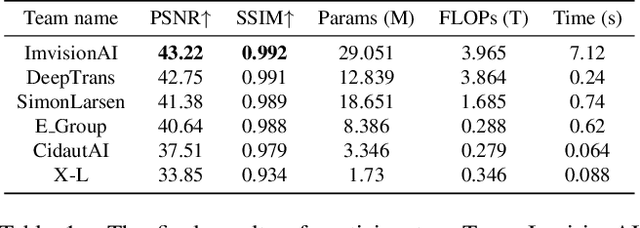

This paper reviews the NTIRE 2025 Efficient Burst HDR and Restoration Challenge, which aims to advance efficient multi-frame high dynamic range (HDR) and restoration techniques. The challenge is based on a novel RAW multi-frame fusion dataset, comprising nine noisy and misaligned RAW frames with various exposure levels per scene. Participants were tasked with developing solutions capable of effectively fusing these frames while adhering to strict efficiency constraints: fewer than 30 million model parameters and a computational budget under 4.0 trillion FLOPs. A total of 217 participants registered, with six teams finally submitting valid solutions. The top-performing approach achieved a PSNR of 43.22 dB, showcasing the potential of novel methods in this domain. This paper provides a comprehensive overview of the challenge, compares the proposed solutions, and serves as a valuable reference for researchers and practitioners in efficient burst HDR and restoration.
FusionNet: Multi-model Linear Fusion Framework for Low-light Image Enhancement
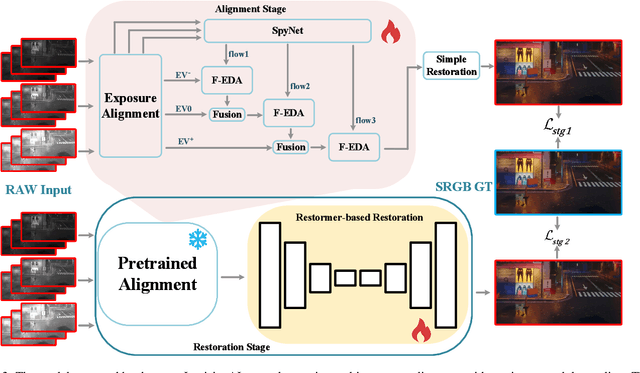
Apr 27, 2025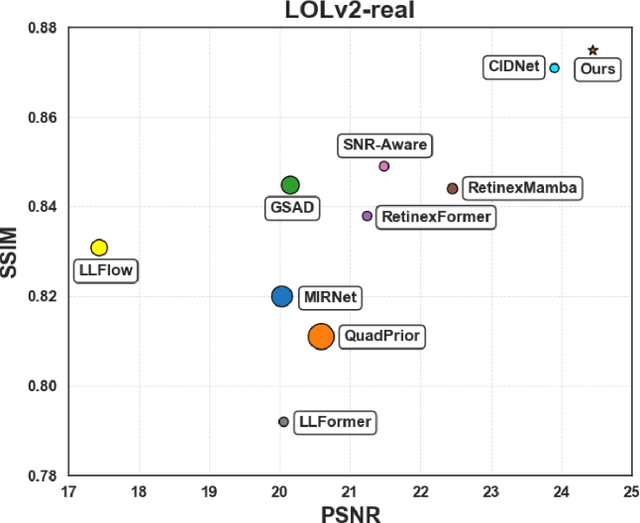

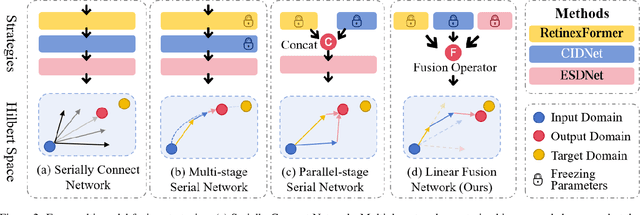

The advent of Deep Neural Networks (DNNs) has driven remarkable progress in low-light image enhancement (LLIE), with diverse architectures (e.g., CNNs and Transformers) and color spaces (e.g., sRGB, HSV, HVI) yielding impressive results. Recent efforts have sought to leverage the complementary strengths of these paradigms, offering promising solutions to enhance performance across varying degradation scenarios. However, existing fusion strategies are hindered by challenges such as parameter explosion, optimization instability, and feature misalignment, limiting further improvements. To overcome these issues, we introduce FusionNet, a novel multi-model linear fusion framework that operates in parallel to effectively capture global and local features across diverse color spaces. By incorporating a linear fusion strategy underpinned by Hilbert space theoretical guarantees, FusionNet mitigates network collapse and reduces excessive training costs. Our method achieved 1st place in the CVPR2025 NTIRE Low Light Enhancement Challenge. Extensive experiments conducted on synthetic and real-world benchmark datasets demonstrate that the proposed method significantly outperforms state-of-the-art methods in terms of both quantitative and qualitative results, delivering robust enhancement under diverse low-light conditions.
Temporal Score Analysis for Understanding and Correcting Diffusion Artifacts
Mar 20, 2025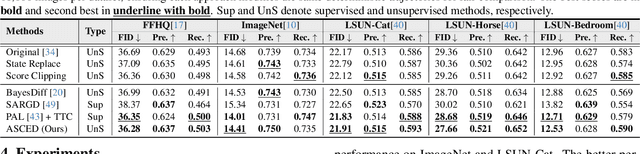
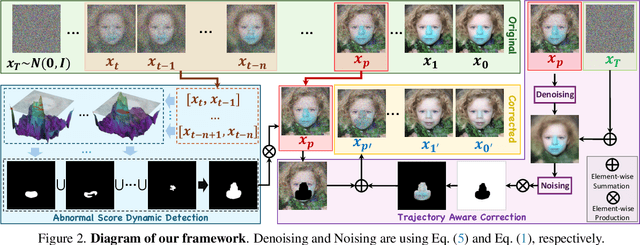
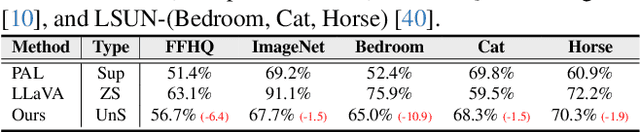

Visual artifacts remain a persistent challenge in diffusion models, even with training on massive datasets. Current solutions primarily rely on supervised detectors, yet lack understanding of why these artifacts occur in the first place. In our analysis, we identify three distinct phases in the diffusion generative process: Profiling, Mutation, and Refinement. Artifacts typically emerge during the Mutation phase, where certain regions exhibit anomalous score dynamics over time, causing abrupt disruptions in the normal evolution pattern. This temporal nature explains why existing methods focusing only on spatial uncertainty of the final output fail at effective artifact localization. Based on these insights, we propose ASCED (Abnormal Score Correction for Enhancing Diffusion), that detects artifacts by monitoring abnormal score dynamics during the diffusion process, with a trajectory-aware on-the-fly mitigation strategy that appropriate generation of noise in the detected areas. Unlike most existing methods that apply post hoc corrections, \eg, by applying a noising-denoising scheme after generation, our mitigation strategy operates seamlessly within the existing diffusion process. Extensive experiments demonstrate that our proposed approach effectively reduces artifacts across diverse domains, matching or surpassing existing supervised methods without additional training.