 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO-VO: Learning Where to Focus for Enhanced State Estimation
Apr 05, 2026We present DINO Patch Visual Odometry (DINO-VO), an end-to-end monocular visual odometry system with strong scene generalization. Current Visual Odometry (VO) systems often rely on heuristic feature extraction strategies, which can degrade accuracy and robustness, particularly in large-scale outdoor environments. DINO-VO addresses these limitations by incorporating a differentiable adaptive patch selector into the end-to-end pipeline, improving the quality of extracted patches and enhancing generalization across diverse datasets. Additionally, our system integrates a multi-task feature extraction module with a differentiable bundle adjustment (BA) module that leverages inverse depth priors, enabling the system to learn and utilize appearance and geometric information effectively. This integration bridges the gap between feature learning and state estimation. Extensive experiments on the TartanAir, KITTI, Euroc, and TUM datasets demonstrate that DINO-VO exhibits strong generalization across synthetic, indoor, and outdoor environments, achieving state-of-the-art tracking accuracy.
MacTok: Robust Continuous Tokenization for Image Generation
Mar 31, 2026Continuous image tokenizers enable efficient visual generation, and those based on variational frameworks can learn smooth, structured latent representations through KL regularization. Yet this often leads to posterior collapse when using fewer tokens, where the encoder fails to encode informative features into the compressed latent space. To address this, we introduce \textbf{MacTok}, a \textbf{M}asked \textbf{A}ugmenting 1D \textbf{C}ontinuous \textbf{Tok}enizer that leverages image masking and representation alignment to prevent collapse while learning compact and robust representations. MacTok applies both random masking to regularize latent learning and DINO-guided semantic masking to emphasize informative regions in images, forcing the model to encode robust semantics from incomplete visual evidence. Combined with global and local representation alignment, MacTok preserves rich discriminative information in a highly compressed 1D latent space, requiring only 64 or 128 tokens. On ImageNet, MacTok achieves a competitive gFID of 1.44 at 256$\times$256 and a state-of-the-art 1.52 at 512$\times$512 with SiT-XL, while reducing token usage by up to 64$\times$. These results confirm that masking and semantic guidance together prevent posterior collapse and achieve efficient, high-fidelity tokenization.
GIFT: Global Irreplaceability Frame Targeting for Efficient Video Understanding
Mar 26, 2026Video Large Language Models (VLMs) have achieved remarkable success in video understanding, but the significant computational cost from processing dense frames severely limits their practical application. Existing methods alleviate this by selecting keyframes, but their greedy decision-making, combined with a decoupled evaluation of relevance and diversity, often falls into local optima and results in erroneously selecting irrelevant noise frames. To address these challenges, we propose GIFT: Global Irreplaceability Frame Targeting, a novel training-free framework that selects frames by assessing their intrinsic irreplaceability. Specifically, we first introduce Directed Diversity to quantify a frame's uniqueness conditioned on relevance, which allows us to formulate a unified irreplaceability score. Subsequently, our Budget-Aware Refinement strategy employs a adaptive iterative process that first secures a core set of frames with the highest irreplaceability, and then shifts its priority to building crucial temporal context around these selections as the budget expands. Extensive experiments demonstrate that GIFT achieves a maximum average improvement of 12.5% across long-form video benchmarks on LLaVA-Video-7B compared to uniform sampling.
M^3: Dense Matching Meets Multi-View Foundation Models for Monocular Gaussian Splatting SLAM
Mar 17, 2026Streaming reconstruction from uncalibrated monocular video remains challenging, as it requires both high-precision pose estimation and computationally efficient online refinement in dynamic environments. While coupling 3D foundation models with SLAM frameworks is a promising paradigm, a critical bottleneck persists: most multi-view foundation models estimate poses in a feed-forward manner, yielding pixel-level correspondences that lack the requisite precision for rigorous geometric optimization. To address this, we present M^3, which augments the Multi-view foundation model with a dedicated Matching head to facilitate fine-grained dense correspondences and integrates it into a robust Monocular Gaussian Splatting SLAM. M^3 further enhances tracking stability by incorporating dynamic area suppression and cross-inference intrinsic alignment. Extensive experiments on diverse indoor and outdoor benchmarks demonstrate state-of-the-art accuracy in both pose estimation and scene reconstruction. Notably, M^3 reduces ATE RMSE by 64.3% compared to VGGT-SLAM 2.0 and outperforms ARTDECO by 2.11 dB in PSNR on the ScanNet++ dataset.
DynamicVGGT: Learning Dynamic Point Maps for 4D Scene Reconstruction in Autonomous Driving
Mar 09, 2026Dynamic scene reconstruction in autonomous driving remains a fundamental challenge due to significant temporal variations, moving objects, and complex scene dynamics. Existing feed-forward 3D models have demonstrated strong performance in static reconstruction but still struggle to capture dynamic motion. To address these limitations, we propose DynamicVGGT, a unified feed-forward framework that extends VGGT from static 3D perception to dynamic 4D reconstruction. Our goal is to model point motion within feed-forward 3D models in a dynamic and temporally coherent manner. To this end, we jointly predict the current and future point maps within a shared reference coordinate system, allowing the model to implicitly learn dynamic point representations through temporal correspondence. To efficiently capture temporal dependencies, we introduce a Motion-aware Temporal Attention (MTA) module that learns motion continuity. Furthermore, we design a Dynamic 3D Gaussian Splatting Head that explicitly models point motion by predicting Gaussian velocities using learnable motion tokens under scene flow supervision. It refines dynamic geometry through continuous 3D Gaussian optimization. Extensive experiments on autonomous driving datasets demonstrate that DynamicVGGT significantly outperforms existing methods in reconstruction accuracy, achieving robust feed-forward 4D dynamic scene reconstruction under complex driving scenarios.
Enhancing Geometric Perception in VLMs via Translator-Guided Reinforcement Learning
Feb 26, 2026Vision-language models (VLMs) often struggle with geometric reasoning due to their limited perception of fundamental diagram elements. To tackle this challenge, we introduce GeoPerceive, a benchmark comprising diagram instances paired with domain-specific language (DSL) representations, along with an efficient automatic data generation pipeline. This design enables the isolated evaluation of geometric perception independently from reasoning. To exploit the data provided by GeoPerceive for enhancing the geometric perception capabilities of VLMs, we propose GeoDPO, a translator-guided reinforcement learning (RL) framework. GeoDPO employs an NL-to-DSL translator, which is trained on synthetic pairs generated by the data engine of GeoPerceive, to bridge natural language and DSL. This translator facilitates the computation of fine-grained, DSL-level scores, which serve as reward signals in reinforcement learning. We assess GeoDPO on both in-domain and out-of-domain datasets, spanning tasks in geometric perception as well as downstream reasoning. Experimental results demonstrate that, while supervised fine-tuning (SFT) offers only marginal improvements and may even impair performance in out-of-domain scenarios, GeoDPO achieves substantial gains: $+26.5\%$ on in-domain data, $+8.0\%$ on out-of-domain data, and $+39.0\%$ on downstream reasoning tasks. These findings underscore the superior performance and generalization ability of GeoDPO over SFT. All codes are released at https://github.com/Longin-Yu/GeoPerceive to ensure reproducibility.
MethConvTransformer: A Deep Learning Framework for Cross-Tissue Alzheimer's Disease Detection
Jan 01, 2026Alzheimer's disease (AD) is a multifactorial neurodegenerative disorder characterized by progressive cognitive decline and widespread epigenetic dysregulation in the brain. DNA methylation, as a stable yet dynamic epigenetic modification, holds promise as a noninvasive biomarker for early AD detection. However, methylation signatures vary substantially across tissues and studies, limiting reproducibility and translational utility. To address these challenges, we develop MethConvTransformer, a transformer-based deep learning framework that integrates DNA methylation profiles from both brain and peripheral tissues to enable biomarker discovery. The model couples a CpG-wise linear projection with convolutional and self-attention layers to capture local and long-range dependencies among CpG sites, while incorporating subject-level covariates and tissue embeddings to disentangle shared and region-specific methylation effects. In experiments across six GEO datasets and an independent ADNI validation cohort, our model consistently outperforms conventional machine-learning baselines, achieving superior discrimination and generalization. Moreover, interpretability analyses using linear projection, SHAP, and Grad-CAM++ reveal biologically meaningful methylation patterns aligned with AD-associated pathways, including immune receptor signaling, glycosylation, lipid metabolism, and endomembrane (ER/Golgi) organization. Together, these results indicate that MethConvTransformer delivers robust, cross-tissue epigenetic biomarkers for AD while providing multi-resolution interpretability, thereby advancing reproducible methylation-based diagnostics and offering testable hypotheses on disease mechanisms.
SafeRBench: A Comprehensive Benchmark for Safety Assessment in Large Reasoning Models
Nov 19, 2025Large Reasoning Models (LRMs) improve answer quality through explicit chain-of-thought, yet this very capability introduces new safety risks: harmful content can be subtly injected, surface gradually, or be justified by misleading rationales within the reasoning trace. Existing safety evaluations, however, primarily focus on output-level judgments and rarely capture these dynamic risks along the reasoning process. In this paper, we present SafeRBench, the first benchmark that assesses LRM safety end-to-end -- from inputs and intermediate reasoning to final outputs. (1) Input Characterization: We pioneer the incorporation of risk categories and levels into input design, explicitly accounting for affected groups and severity, and thereby establish a balanced prompt suite reflecting diverse harm gradients. (2) Fine-Grained Output Analysis: We introduce a micro-thought chunking mechanism to segment long reasoning traces into semantically coherent units, enabling fine-grained evaluation across ten safety dimensions. (3) Human Safety Alignment: We validate LLM-based evaluations against human annotations specifically designed to capture safety judgments. Evaluations on 19 LRMs demonstrate that SafeRBench enables detailed, multidimensional safety assessment, offering insights into risks and protective mechanisms from multiple perspectives.
Dark-ISP: Enhancing RAW Image Processing for Low-Light Object Detection
Sep 11, 2025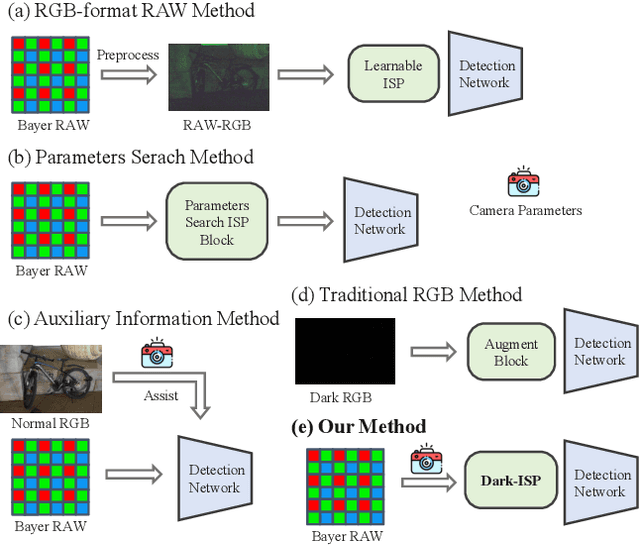
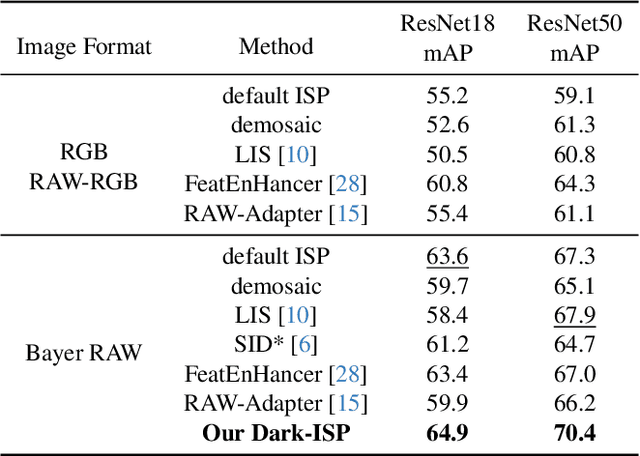
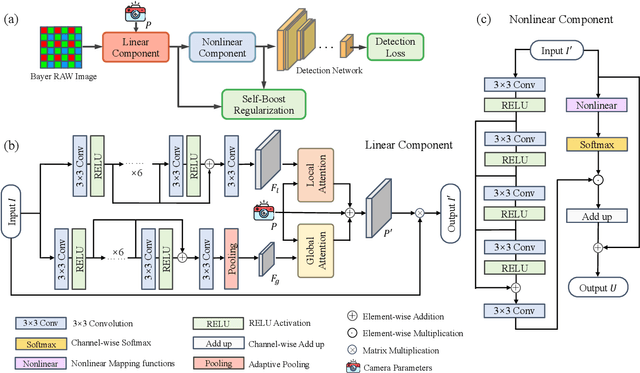
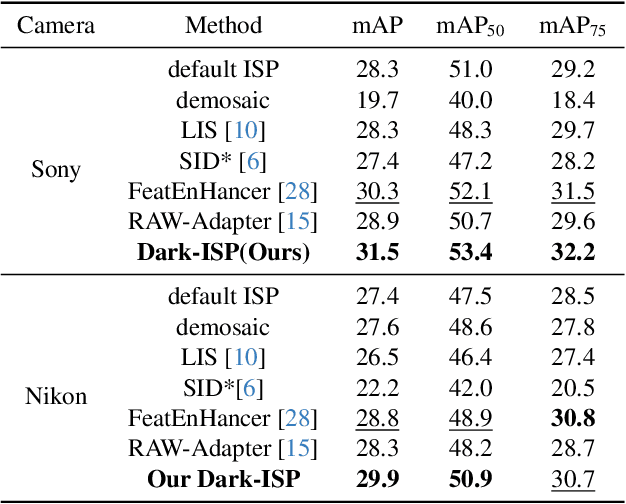
Low-light Object detection is crucial for many real-world applications but remains challenging due to degraded image quality. While recent studies have shown that RAW images offer superior potential over RGB images, existing approaches either use RAW-RGB images with information loss or employ complex frameworks. To address these, we propose a lightweight and self-adaptive Image Signal Processing (ISP) plugin, Dark-ISP, which directly processes Bayer RAW images in dark environments, enabling seamless end-to-end training for object detection. Our key innovations are: (1) We deconstruct conventional ISP pipelines into sequential linear (sensor calibration) and nonlinear (tone mapping) sub-modules, recasting them as differentiable components optimized through task-driven losses. Each module is equipped with content-aware adaptability and physics-informed priors, enabling automatic RAW-to-RGB conversion aligned with detection objectives. (2) By exploiting the ISP pipeline's intrinsic cascade structure, we devise a Self-Boost mechanism that facilitates cooperation between sub-modules. Through extensive experiments on three RAW image datasets, we demonstrate that our method outperforms state-of-the-art RGB- and RAW-based detection approaches, achieving superior results with minimal parameters in challenging low-light environments.
* 11 pages, 6 figures, conference
SCOUT: Teaching Pre-trained Language Models to Enhance Reasoning via Flow Chain-of-Thought
May 30, 2025Chain of Thought (CoT) prompting improves the reasoning performance of large language models (LLMs) by encouraging step by step thinking. However, CoT-based methods depend on intermediate reasoning steps, which limits scalability and generalization. Recent work explores recursive reasoning, where LLMs reuse internal layers across iterations to refine latent representations without explicit CoT supervision. While promising, these approaches often require costly pretraining and lack a principled framework for how reasoning should evolve across iterations. We address this gap by introducing Flow Chain of Thought (Flow CoT), a reasoning paradigm that models recursive inference as a progressive trajectory of latent cognitive states. Flow CoT frames each iteration as a distinct cognitive stage deepening reasoning across iterations without relying on manual supervision. To realize this, we propose SCOUT (Stepwise Cognitive Optimization Using Teachers), a lightweight fine tuning framework that enables Flow CoT style reasoning without the need for pretraining. SCOUT uses progressive distillation to align each iteration with a teacher of appropriate capacity, and a cross attention based retrospective module that integrates outputs from previous iterations while preserving the models original computation flow. Experiments across eight reasoning benchmarks show that SCOUT consistently improves both accuracy and explanation quality, achieving up to 1.8% gains under fine tuning. Qualitative analyses further reveal that SCOUT enables progressively deeper reasoning across iterations refining both belief formation and explanation granularity. These results not only validate the effectiveness of SCOUT, but also demonstrate the practical viability of Flow CoT as a scalable framework for enhancing reasoning in LLMs.