 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEMA: Simple yet Effective Learning for Multi-Turn Jailbreak Attacks
Feb 06, 2026Multi-turn jailbreaks capture the real threat model for safety-aligned chatbots, where single-turn attacks are merely a special case. Yet existing approaches break under exploration complexity and intent drift. We propose SEMA, a simple yet effective framework that trains a multi-turn attacker without relying on any existing strategies or external data. SEMA comprises two stages. Prefilling self-tuning enables usable rollouts by fine-tuning on non-refusal, well-structured, multi-turn adversarial prompts that are self-generated with a minimal prefix, thereby stabilizing subsequent learning. Reinforcement learning with intent-drift-aware reward trains the attacker to elicit valid multi-turn adversarial prompts while maintaining the same harmful objective. We anchor harmful intent in multi-turn jailbreaks via an intent-drift-aware reward that combines intent alignment, compliance risk, and level of detail. Our open-loop attack regime avoids dependence on victim feedback, unifies single- and multi-turn settings, and reduces exploration complexity. Across multiple datasets, victim models, and jailbreak judges, our method achieves state-of-the-art (SOTA) attack success rates (ASR), outperforming all single-turn baselines, manually scripted and template-driven multi-turn baselines, as well as our SFT (Supervised Fine-Tuning) and DPO (Direct Preference Optimization) variants. For instance, SEMA performs an average $80.1\%$ ASR@1 across three closed-source and open-source victim models on AdvBench, 33.9% over SOTA. The approach is compact, reproducible, and transfers across targets, providing a stronger and more realistic stress test for large language model (LLM) safety and enabling automatic redteaming to expose and localize failure modes. Our code is available at: https://github.com/fmmarkmq/SEMA.
Statistical Estimation of Adversarial Risk in Large Language Models under Best-of-N Sampling
Jan 30, 2026Large Language Models (LLMs) are typically evaluated for safety under single-shot or low-budget adversarial prompting, which underestimates real-world risk. In practice, attackers can exploit large-scale parallel sampling to repeatedly probe a model until a harmful response is produced. While recent work shows that attack success increases with repeated sampling, principled methods for predicting large-scale adversarial risk remain limited. We propose a scaling-aware Best-of-N estimation of risk, SABER, for modeling jailbreak vulnerability under Best-of-N sampling. We model sample-level success probabilities using a Beta distribution, the conjugate prior of the Bernoulli distribution, and derive an analytic scaling law that enables reliable extrapolation of large-N attack success rates from small-budget measurements. Using only n=100 samples, our anchored estimator predicts ASR@1000 with a mean absolute error of 1.66, compared to 12.04 for the baseline, which is an 86.2% reduction in estimation error. Our results reveal heterogeneous risk scaling profiles and show that models appearing robust under standard evaluation can experience rapid nonlinear risk amplification under parallel adversarial pressure. This work provides a low-cost, scalable methodology for realistic LLM safety assessment. We will release our code and evaluation scripts upon publication to future research.
MMPerspective: Do MLLMs Understand Perspective? A Comprehensive Benchmark for Perspective Perception, Reasoning, and Robustness
May 26, 2025Understanding perspective is fundamental to human visual perception, yet the extent to which multimodal large language models (MLLMs) internalize perspective geometry remains unclear. We introduce MMPerspective, the first benchmark specifically designed to systematically evaluate MLLMs' understanding of perspective through 10 carefully crafted tasks across three complementary dimensions: Perspective Perception, Reasoning, and Robustness. Our benchmark comprises 2,711 real-world and synthetic image instances with 5,083 question-answer pairs that probe key capabilities, such as vanishing point perception and counting, perspective type reasoning, line relationship understanding in 3D space, invariance to perspective-preserving transformations, etc. Through a comprehensive evaluation of 43 state-of-the-art MLLMs, we uncover significant limitations: while models demonstrate competence on surface-level perceptual tasks, they struggle with compositional reasoning and maintaining spatial consistency under perturbations. Our analysis further reveals intriguing patterns between model architecture, scale, and perspective capabilities, highlighting both robustness bottlenecks and the benefits of chain-of-thought prompting. MMPerspective establishes a valuable testbed for diagnosing and advancing spatial understanding in vision-language systems. Resources available at: https://yunlong10.github.io/MMPerspective/
Caption Anything in Video: Fine-grained Object-centric Captioning via Spatiotemporal Multimodal Prompting
Apr 09, 2025We present CAT-V (Caption AnyThing in Video), a training-free framework for fine-grained object-centric video captioning that enables detailed descriptions of user-selected objects through time. CAT-V integrates three key components: a Segmenter based on SAMURAI for precise object segmentation across frames, a Temporal Analyzer powered by TRACE-Uni for accurate event boundary detection and temporal analysis, and a Captioner using InternVL-2.5 for generating detailed object-centric descriptions. Through spatiotemporal visual prompts and chain-of-thought reasoning, our framework generates detailed, temporally-aware descriptions of objects' attributes, actions, statuses, interactions, and environmental contexts without requiring additional training data. CAT-V supports flexible user interactions through various visual prompts (points, bounding boxes, and irregular regions) and maintains temporal sensitivity by tracking object states and interactions across different time segments. Our approach addresses limitations of existing video captioning methods, which either produce overly abstract descriptions or lack object-level precision, enabling fine-grained, object-specific descriptions while maintaining temporal coherence and spatial accuracy. The GitHub repository for this project is available at https://github.com/yunlong10/CAT-V
Forward Learning with Differential Privacy
Apr 01, 2025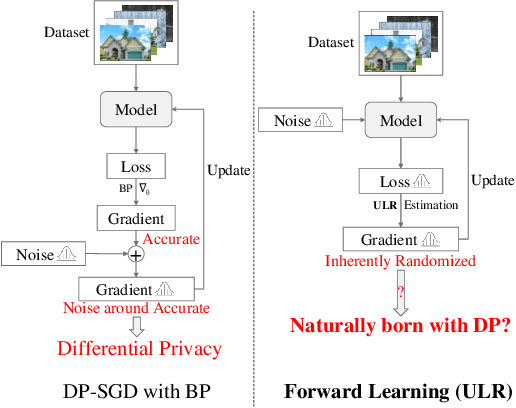
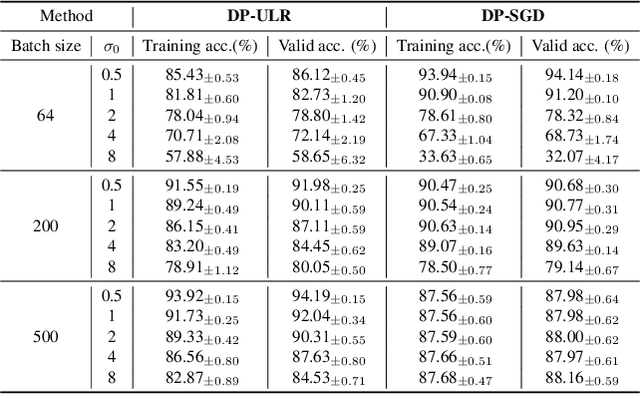
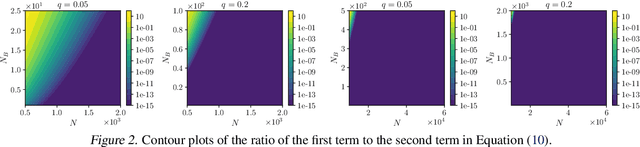
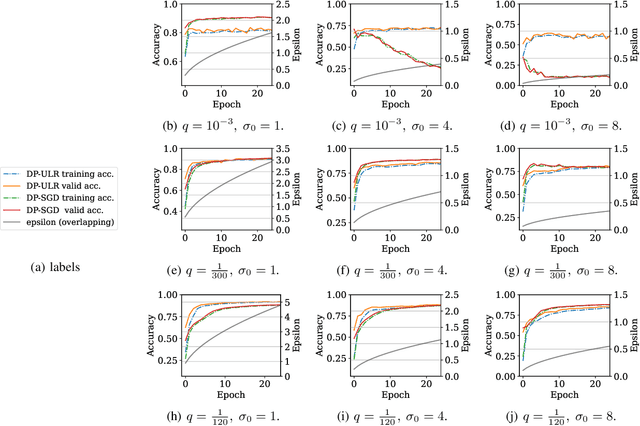
Differential privacy (DP) in deep learning is a critical concern as it ensures the confidentiality of training data while maintaining model utility. Existing DP training algorithms provide privacy guarantees by clipping and then injecting external noise into sample gradients computed by the backpropagation algorithm. Different from backpropagation, forward-learning algorithms based on perturbation inherently add noise during the forward pass and utilize randomness to estimate the gradients. Although these algorithms are non-privatized, the introduction of noise during the forward pass indirectly provides internal randomness protection to the model parameters and their gradients, suggesting the potential for naturally providing differential privacy. In this paper, we propose a \blue{privatized} forward-learning algorithm, Differential Private Unified Likelihood Ratio (DP-ULR), and demonstrate its differential privacy guarantees. DP-ULR features a novel batch sampling operation with rejection, of which we provide theoretical analysis in conjunction with classic differential privacy mechanisms. DP-ULR is also underpinned by a theoretically guided privacy controller that dynamically adjusts noise levels to manage privacy costs in each training step. Our experiments indicate that DP-ULR achieves competitive performance compared to traditional differential privacy training algorithms based on backpropagation, maintaining nearly the same privacy loss limits.
Generative AI for Cel-Animation: A Survey
Jan 08, 2025



Traditional Celluloid (Cel) Animation production pipeline encompasses multiple essential steps, including storyboarding, layout design, keyframe animation, inbetweening, and colorization, which demand substantial manual effort, technical expertise, and significant time investment. These challenges have historically impeded the efficiency and scalability of Cel-Animation production. The rise of generative artificial intelligence (GenAI), encompassing large language models, multimodal models, and diffusion models, offers innovative solutions by automating tasks such as inbetween frame generation, colorization, and storyboard creation. This survey explores how GenAI integration is revolutionizing traditional animation workflows by lowering technical barriers, broadening accessibility for a wider range of creators through tools like AniDoc, ToonCrafter, and AniSora, and enabling artists to focus more on creative expression and artistic innovation. Despite its potential, issues such as maintaining visual consistency, ensuring stylistic coherence, and addressing ethical considerations continue to pose challenges. Furthermore, this paper discusses future directions and explores potential advancements in AI-assisted animation. For further exploration and resources, please visit our GitHub repository: https://github.com/yunlong10/Awesome-AI4Animation
VidComposition: Can MLLMs Analyze Compositions in Compiled Videos?
Nov 19, 2024



The advancement of Multimodal Large Language Models (MLLMs) has enabled significant progress in multimodal understanding, expanding their capacity to analyze video content. However, existing evaluation benchmarks for MLLMs primarily focus on abstract video comprehension, lacking a detailed assessment of their ability to understand video compositions, the nuanced interpretation of how visual elements combine and interact within highly compiled video contexts. We introduce VidComposition, a new benchmark specifically designed to evaluate the video composition understanding capabilities of MLLMs using carefully curated compiled videos and cinematic-level annotations. VidComposition includes 982 videos with 1706 multiple-choice questions, covering various compositional aspects such as camera movement, angle, shot size, narrative structure, character actions and emotions, etc. Our comprehensive evaluation of 33 open-source and proprietary MLLMs reveals a significant performance gap between human and model capabilities. This highlights the limitations of current MLLMs in understanding complex, compiled video compositions and offers insights into areas for further improvement. The leaderboard and evaluation code are available at https://yunlong10.github.io/VidComposition/.
Will the Inclusion of Generated Data Amplify Bias Across Generations in Future Image Classification Models?
Oct 14, 2024As the demand for high-quality training data escalates, researchers have increasingly turned to generative models to create synthetic data, addressing data scarcity and enabling continuous model improvement. However, reliance on self-generated data introduces a critical question: Will this practice amplify bias in future models? While most research has focused on overall performance, the impact on model bias, particularly subgroup bias, remains underexplored. In this work, we investigate the effects of the generated data on image classification tasks, with a specific focus on bias. We develop a practical simulation environment that integrates a self-consuming loop, where the generative model and classification model are trained synergistically. Hundreds of experiments are conducted on Colorized MNIST, CIFAR-20/100, and Hard ImageNet datasets to reveal changes in fairness metrics across generations. In addition, we provide a conjecture to explain the bias dynamics when training models on continuously augmented datasets across generations. Our findings contribute to the ongoing debate on the implications of synthetic data for fairness in real-world applications.
FLOPS: Forward Learning with OPtimal Sampling
Oct 08, 2024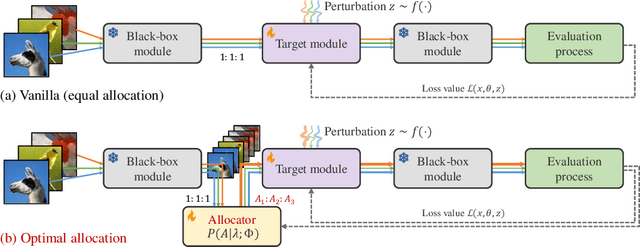
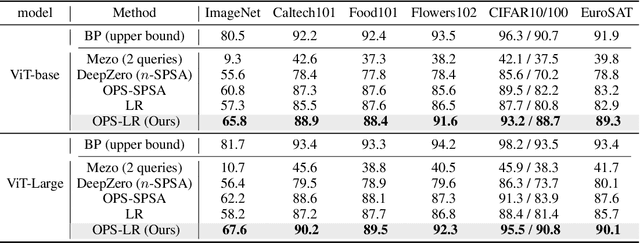
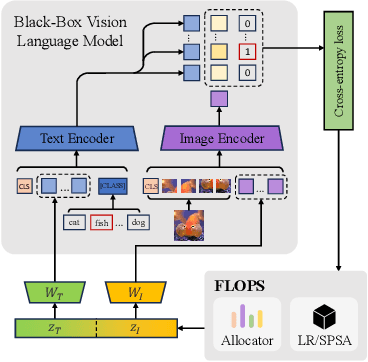
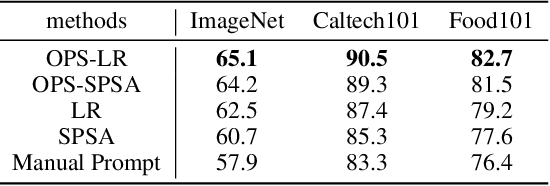
Given the limitations of backpropagation, perturbation-based gradient computation methods have recently gained focus for learning with only forward passes, also referred to as queries. Conventional forward learning consumes enormous queries on each data point for accurate gradient estimation through Monte Carlo sampling, which hinders the scalability of those algorithms. However, not all data points deserve equal queries for gradient estimation. In this paper, we study the problem of improving the forward learning efficiency from a novel perspective: how to reduce the gradient estimation variance with minimum cost? For this, we propose to allocate the optimal number of queries over each data in one batch during training to achieve a good balance between estimation accuracy and computational efficiency. Specifically, with a simplified proxy objective and a reparameterization technique, we derive a novel plug-and-play query allocator with minimal parameters. Theoretical results are carried out to verify its optimality. We conduct extensive experiments for fine-tuning Vision Transformers on various datasets and further deploy the allocator to two black-box applications: prompt tuning and multimodal alignment for foundation models. All findings demonstrate that our proposed allocator significantly enhances the scalability of forward-learning algorithms, paving the way for real-world applications.
Do More Details Always Introduce More Hallucinations in LVLM-based Image Captioning?
Jun 18, 2024Large Vision-Language Models (LVLMs) excel in integrating visual and linguistic contexts to produce detailed content, facilitating applications such as image captioning. However, using LVLMs to generate descriptions often faces the challenge of object hallucination (OH), where the output text misrepresents actual objects in the input image. While previous studies attribute the occurrence of OH to the inclusion of more details, our study finds technical flaws in existing metrics, leading to unreliable evaluations of models and conclusions about OH. This has sparked a debate on the question: Do more details always introduce more hallucinations in LVLM-based image captioning? In this paper, we address this debate by proposing a novel decoding strategy, Differentiated Beam Decoding (DBD), along with a reliable new set of evaluation metrics: CLIP-Precision, CLIP-Recall, and CLIP-F1. DBD decodes the wealth of information hidden in visual input into distinct language representations called unit facts in parallel. This decoding is achieved via a well-designed differential score that guides the parallel search and candidate screening. The selected unit facts are then aggregated to generate the final caption. Our proposed metrics evaluate the comprehensiveness and accuracy of image captions by comparing the embedding groups of ground-truth image regions and generated text partitions. Extensive experiments on the Visual Genome dataset validate the effectiveness of our approach, demonstrating that it produces detailed descriptions while maintaining low hallucination levels.