 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025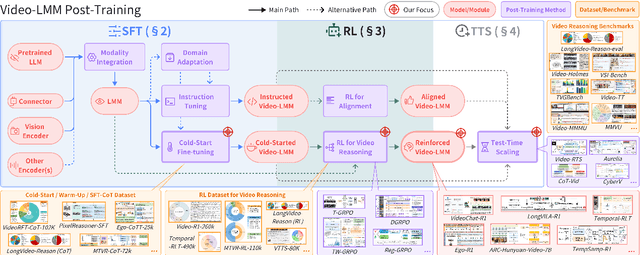
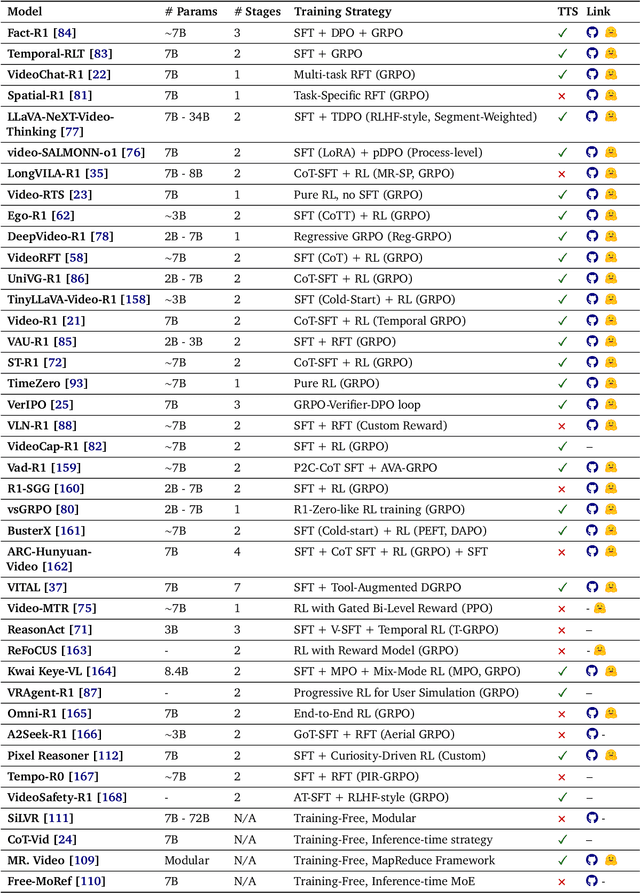
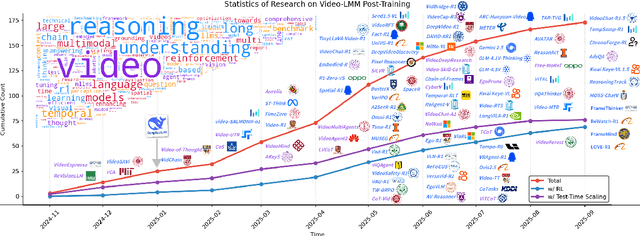
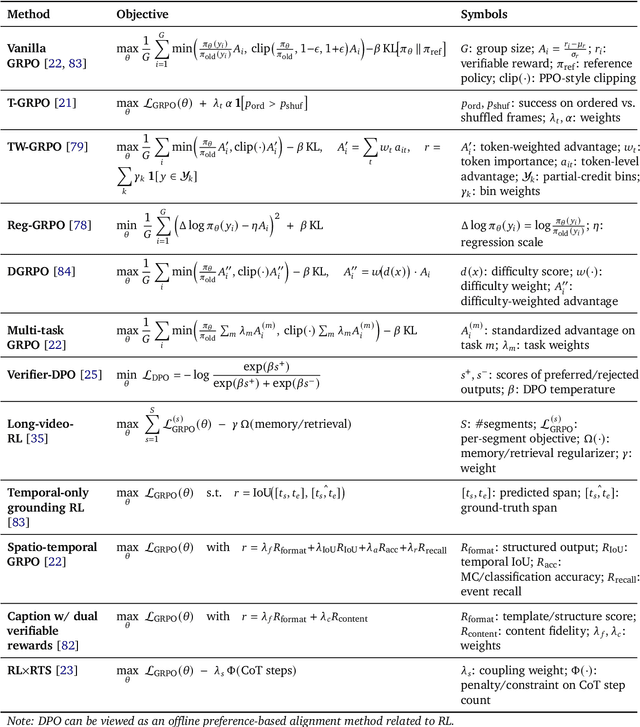
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
Generative AI for Cel-Animation: A Survey
Jan 08, 2025



Traditional Celluloid (Cel) Animation production pipeline encompasses multiple essential steps, including storyboarding, layout design, keyframe animation, inbetweening, and colorization, which demand substantial manual effort, technical expertise, and significant time investment. These challenges have historically impeded the efficiency and scalability of Cel-Animation production. The rise of generative artificial intelligence (GenAI), encompassing large language models, multimodal models, and diffusion models, offers innovative solutions by automating tasks such as inbetween frame generation, colorization, and storyboard creation. This survey explores how GenAI integration is revolutionizing traditional animation workflows by lowering technical barriers, broadening accessibility for a wider range of creators through tools like AniDoc, ToonCrafter, and AniSora, and enabling artists to focus more on creative expression and artistic innovation. Despite its potential, issues such as maintaining visual consistency, ensuring stylistic coherence, and addressing ethical considerations continue to pose challenges. Furthermore, this paper discusses future directions and explores potential advancements in AI-assisted animation. For further exploration and resources, please visit our GitHub repository: https://github.com/yunlong10/Awesome-AI4Animation
Swiss DINO: Efficient and Versatile Vision Framework for On-device Personal Object Search
Jul 10, 2024
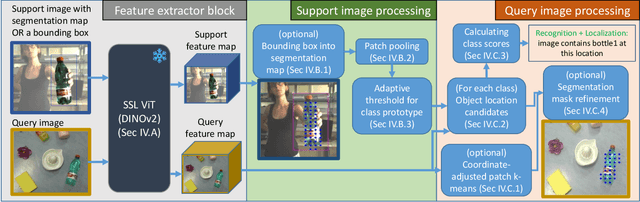


In this paper, we address a recent trend in robotic home appliances to include vision systems on personal devices, capable of personalizing the appliances on the fly. In particular, we formulate and address an important technical task of personal object search, which involves localization and identification of personal items of interest on images captured by robotic appliances, with each item referenced only by a few annotated images. The task is crucial for robotic home appliances and mobile systems, which need to process personal visual scenes or to operate with particular personal objects (e.g., for grasping or navigation). In practice, personal object search presents two main technical challenges. First, a robot vision system needs to be able to distinguish between many fine-grained classes, in the presence of occlusions and clutter. Second, the strict resource requirements for the on-device system restrict the usage of most state-of-the-art methods for few-shot learning and often prevent on-device adaptation. In this work, we propose Swiss DINO: a simple yet effective framework for one-shot personal object search based on the recent DINOv2 transformer model, which was shown to have strong zero-shot generalization properties. Swiss DINO handles challenging on-device personalized scene understanding requirements and does not require any adaptation training. We show significant improvement (up to 55%) in segmentation and recognition accuracy compared to the common lightweight solutions, and significant footprint reduction of backbone inference time (up to 100x) and GPU consumption (up to 10x) compared to the heavy transformer-based solutions.
SPEAR: Receiver-to-Receiver Acoustic Neural Warping Field
Jun 16, 2024



We present SPEAR, a continuous receiver-to-receiver acoustic neural warping field for spatial acoustic effects prediction in an acoustic 3D space with a single stationary audio source. Unlike traditional source-to-receiver modelling methods that require prior space acoustic properties knowledge to rigorously model audio propagation from source to receiver, we propose to predict by warping the spatial acoustic effects from one reference receiver position to another target receiver position, so that the warped audio essentially accommodates all spatial acoustic effects belonging to the target position. SPEAR can be trained in a data much more readily accessible manner, in which we simply ask two robots to independently record spatial audio at different positions. We further theoretically prove the universal existence of the warping field if and only if one audio source presents. Three physical principles are incorporated to guide SPEAR network design, leading to the learned warping field physically meaningful. We demonstrate SPEAR superiority on both synthetic, photo-realistic and real-world dataset, showing the huge potential of SPEAR to various down-stream robotic tasks.
MGDepth: Motion-Guided Cost Volume For Self-Supervised Monocular Depth In Dynamic Scenarios
Dec 23, 2023



Despite advancements in self-supervised monocular depth estimation, challenges persist in dynamic scenarios due to the dependence on assumptions about a static world. In this paper, we present MGDepth, a Motion-Guided Cost Volume Depth Net, to achieve precise depth estimation for both dynamic objects and static backgrounds, all while maintaining computational efficiency. To tackle the challenges posed by dynamic content, we incorporate optical flow and coarse monocular depth to create a novel static reference frame. This frame is then utilized to build a motion-guided cost volume in collaboration with the target frame. Additionally, to enhance the accuracy and resilience of the network structure, we introduce an attention-based depth net architecture to effectively integrate information from feature maps with varying resolutions. Compared to methods with similar computational costs, MGDepth achieves a significant reduction of approximately seven percent in root-mean-square error for self-supervised monocular depth estimation on the KITTI-2015 dataset.
DynPoint: Dynamic Neural Point For View Synthesis
Oct 31, 2023



The introduction of neural radiance fields has greatly improved the effectiveness of view synthesis for monocular videos. However, existing algorithms face difficulties when dealing with uncontrolled or lengthy scenarios, and require extensive training time specific to each new scenario. To tackle these limitations, we propose DynPoint, an algorithm designed to facilitate the rapid synthesis of novel views for unconstrained monocular videos. Rather than encoding the entirety of the scenario information into a latent representation, DynPoint concentrates on predicting the explicit 3D correspondence between neighboring frames to realize information aggregation. Specifically, this correspondence prediction is achieved through the estimation of consistent depth and scene flow information across frames. Subsequently, the acquired correspondence is utilized to aggregate information from multiple reference frames to a target frame, by constructing hierarchical neural point clouds. The resulting framework enables swift and accurate view synthesis for desired views of target frames. The experimental results obtained demonstrate the considerable acceleration of training time achieved - typically an order of magnitude - by our proposed method while yielding comparable outcomes compared to prior approaches. Furthermore, our method exhibits strong robustness in handling long-duration videos without learning a canonical representation of video content.
Multi-body SE(3) Equivariance for Unsupervised Rigid Segmentation and Motion Estimation
Jun 08, 2023A truly generalizable approach to rigid segmentation and motion estimation is fundamental to 3D understanding of articulated objects and moving scenes. In view of the tightly coupled relationship between segmentation and motion estimates, we present an SE(3) equivariant architecture and a training strategy to tackle this task in an unsupervised manner. Our architecture comprises two lightweight and inter-connected heads that predict segmentation masks using point-level invariant features and motion estimates from SE(3) equivariant features without the prerequisites of category information. Our unified training strategy can be performed online while jointly optimizing the two predictions by exploiting the interrelations among scene flow, segmentation mask, and rigid transformations. We show experiments on four datasets as evidence of the superiority of our method both in terms of model performance and computational efficiency with only 0.25M parameters and 0.92G FLOPs. To the best of our knowledge, this is the first work designed for category-agnostic part-level SE(3) equivariance in dynamic point clouds.
No Pain, Big Gain: Classify Dynamic Point Cloud Sequences with Static Models by Fitting Feature-level Space-time Surfaces
Mar 23, 2022



Scene flow is a powerful tool for capturing the motion field of 3D point clouds. However, it is difficult to directly apply flow-based models to dynamic point cloud classification since the unstructured points make it hard or even impossible to efficiently and effectively trace point-wise correspondences. To capture 3D motions without explicitly tracking correspondences, we propose a kinematics-inspired neural network (Kinet) by generalizing the kinematic concept of ST-surfaces to the feature space. By unrolling the normal solver of ST-surfaces in the feature space, Kinet implicitly encodes feature-level dynamics and gains advantages from the use of mature backbones for static point cloud processing. With only minor changes in network structures and low computing overhead, it is painless to jointly train and deploy our framework with a given static model. Experiments on NvGesture, SHREC'17, MSRAction-3D, and NTU-RGBD demonstrate its efficacy in performance, efficiency in both the number of parameters and computational complexity, as well as its versatility to various static backbones. Noticeably, Kinet achieves the accuracy of 93.27% on MSRAction-3D with only 3.20M parameters and 10.35G FLOPS.
Uncertainty-aware INVASE: Enhanced Breast Cancer Diagnosis Feature Selection
May 04, 2021


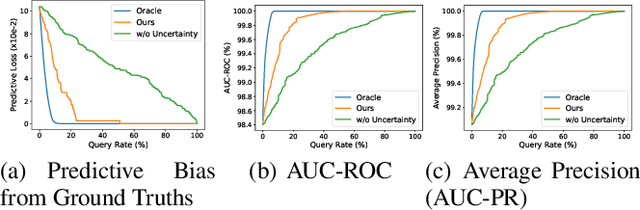
In this paper, we present an uncertainty-aware INVASE to quantify predictive confidence of healthcare problem. By introducing learnable Gaussian distributions, we lever-age their variances to measure the degree of uncertainty. Based on the vanilla INVASE, two additional modules are proposed, i.e., an uncertainty quantification module in the predictor, and a reward shaping module in the selector. We conduct extensive experiments on UCI-WDBC dataset. Notably, our method eliminates almost all predictive bias with only about 20% queries, while the uncertainty-agnostic counterpart requires nearly 100% queries. The open-source implementation with a detailed tutorial is available at https://github.com/jx-zhong-for-academic-purpose/Uncertainty-aware-INVASE/blob/main/tutorialinvase%2B.ipynb.
RoIMix: Proposal-Fusion among Multiple Images for Underwater Object Detection
Nov 08, 2019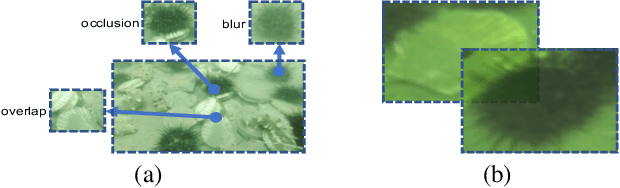



Generic object detection algorithms have proven their excellent performance in recent years. However, object detection on underwater datasets is still less explored. In contrast to generic datasets, underwater images usually have color shift and low contrast; sediment would cause blurring in underwater images. In addition, underwater creatures often appear closely to each other on images due to their living habits. To address these issues, our work investigates augmentation policies to simulate overlapping, occluded and blurred objects, and we construct a model capable of achieving better generalization. We propose an augmentation method called RoIMix, which characterizes interactions among images. Proposals extracted from different images are mixed together. Previous data augmentation methods operate on a single image while we apply RoIMix to multiple images to create enhanced samples as training data. Experiments show that our proposed method improves the performance of region-based object detectors on both Pascal VOC and URPC datasets.