 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycleVLA: Proactive Self-Correcting Vision-Language-Action Models via Subtask Backtracking and Minimum Bayes Risk Decoding
Jan 05, 2026Current work on robot failure detection and correction typically operate in a post hoc manner, analyzing errors and applying corrections only after failures occur. This work introduces CycleVLA, a system that equips Vision-Language-Action models (VLAs) with proactive self-correction, the capability to anticipate incipient failures and recover before they fully manifest during execution. CycleVLA achieves this by integrating a progress-aware VLA that flags critical subtask transition points where failures most frequently occur, a VLM-based failure predictor and planner that triggers subtask backtracking upon predicted failure, and a test-time scaling strategy based on Minimum Bayes Risk (MBR) decoding to improve retry success after backtracking. Extensive experiments show that CycleVLA improves performance for both well-trained and under-trained VLAs, and that MBR serves as an effective zero-shot test-time scaling strategy for VLAs. Project Page: https://dannymcy.github.io/cyclevla/
Efficient and Microphone-Fault-Tolerant 3D Sound Source Localization
May 27, 2025Sound source localization (SSL) is a critical technology for determining the position of sound sources in complex environments. However, existing methods face challenges such as high computational costs and precise calibration requirements, limiting their deployment in dynamic or resource-constrained environments. This paper introduces a novel 3D SSL framework, which uses sparse cross-attention, pretraining, and adaptive signal coherence metrics, to achieve accurate and computationally efficient localization with fewer input microphones. The framework is also fault-tolerant to unreliable or even unknown microphone position inputs, ensuring its applicability in real-world scenarios. Preliminary experiments demonstrate its scalability for multi-source localization without requiring additional hardware. This work advances SSL by balancing the model's performance and efficiency and improving its robustness for real-world scenarios.
Target Speaker Extraction through Comparing Noisy Positive and Negative Audio Enrollments
Feb 23, 2025Target speaker extraction focuses on isolating a specific speaker's voice from an audio mixture containing multiple speakers. To provide information about the target speaker's identity, prior works have utilized clean audio examples as conditioning inputs. However, such clean audio examples are not always readily available (e.g. It is impractical to obtain a clean audio example of a stranger's voice at a cocktail party without stepping away from the noisy environment). Limited prior research has explored extracting the target speaker's characteristics from noisy audio examples, which may include overlapping speech from disturbing speakers. In this work, we focus on target speaker extraction when multiple speakers are present during the enrollment stage, through leveraging differences between audio segments where the target speakers are speaking (Positive Enrollments) and segments where they are not (Negative Enrollments). Experiments show the effectiveness of our model architecture and the dedicated pretraining method for the proposed task. Our method achieves state-of-the-art performance in the proposed application settings and demonstrates strong generalizability across challenging and realistic scenarios.
SPEAR: Receiver-to-Receiver Acoustic Neural Warping Field
Jun 16, 2024



We present SPEAR, a continuous receiver-to-receiver acoustic neural warping field for spatial acoustic effects prediction in an acoustic 3D space with a single stationary audio source. Unlike traditional source-to-receiver modelling methods that require prior space acoustic properties knowledge to rigorously model audio propagation from source to receiver, we propose to predict by warping the spatial acoustic effects from one reference receiver position to another target receiver position, so that the warped audio essentially accommodates all spatial acoustic effects belonging to the target position. SPEAR can be trained in a data much more readily accessible manner, in which we simply ask two robots to independently record spatial audio at different positions. We further theoretically prove the universal existence of the warping field if and only if one audio source presents. Three physical principles are incorporated to guide SPEAR network design, leading to the learned warping field physically meaningful. We demonstrate SPEAR superiority on both synthetic, photo-realistic and real-world dataset, showing the huge potential of SPEAR to various down-stream robotic tasks.
CLIP-Diffusion-LM: Apply Diffusion Model on Image Captioning
Oct 10, 2022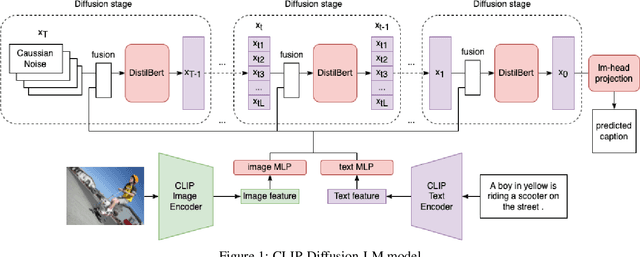
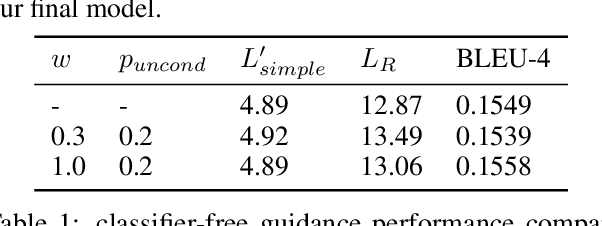

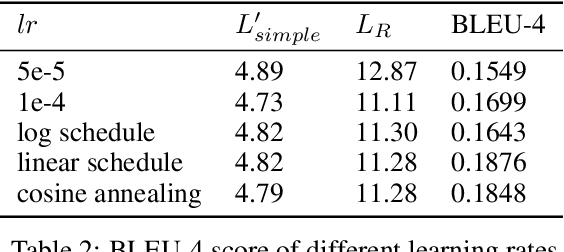
Image captioning task has been extensively researched by previous work. However, limited experiments focus on generating captions based on non-autoregressive text decoder. Inspired by the recent success of the denoising diffusion model on image synthesis tasks, we apply denoising diffusion probabilistic models to text generation in image captioning tasks. We show that our CLIP-Diffusion-LM is capable of generating image captions using significantly fewer inference steps than autoregressive models. On the Flickr8k dataset, the model achieves 0.1876 BLEU-4 score. By training on the combined Flickr8k and Flickr30k dataset, our model achieves 0.2470 BLEU-4 score. Our code is available at https://github.com/xu-shitong/diffusion-image-captioning.