 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoundLoc3D: Invisible 3D Sound Source Localization and Classification Using a Multimodal RGB-D Acoustic Camera
Dec 22, 2024Accurately localizing 3D sound sources and estimating their semantic labels -- where the sources may not be visible, but are assumed to lie on the physical surface of objects in the scene -- have many real applications, including detecting gas leak and machinery malfunction. The audio-visual weak-correlation in such setting poses new challenges in deriving innovative methods to answer if or how we can use cross-modal information to solve the task. Towards this end, we propose to use an acoustic-camera rig consisting of a pinhole RGB-D camera and a coplanar four-channel microphone array~(Mic-Array). By using this rig to record audio-visual signals from multiviews, we can use the cross-modal cues to estimate the sound sources 3D locations. Specifically, our framework SoundLoc3D treats the task as a set prediction problem, each element in the set corresponds to a potential sound source. Given the audio-visual weak-correlation, the set representation is initially learned from a single view microphone array signal, and then refined by actively incorporating physical surface cues revealed from multiview RGB-D images. We demonstrate the efficiency and superiority of SoundLoc3D on large-scale simulated dataset, and further show its robustness to RGB-D measurement inaccuracy and ambient noise interference.
* Accepted by WACV2025
SPEAR: Receiver-to-Receiver Acoustic Neural Warping Field
Jun 16, 2024



We present SPEAR, a continuous receiver-to-receiver acoustic neural warping field for spatial acoustic effects prediction in an acoustic 3D space with a single stationary audio source. Unlike traditional source-to-receiver modelling methods that require prior space acoustic properties knowledge to rigorously model audio propagation from source to receiver, we propose to predict by warping the spatial acoustic effects from one reference receiver position to another target receiver position, so that the warped audio essentially accommodates all spatial acoustic effects belonging to the target position. SPEAR can be trained in a data much more readily accessible manner, in which we simply ask two robots to independently record spatial audio at different positions. We further theoretically prove the universal existence of the warping field if and only if one audio source presents. Three physical principles are incorporated to guide SPEAR network design, leading to the learned warping field physically meaningful. We demonstrate SPEAR superiority on both synthetic, photo-realistic and real-world dataset, showing the huge potential of SPEAR to various down-stream robotic tasks.
Dusk Till Dawn: Self-supervised Nighttime Stereo Depth Estimation using Visual Foundation Models
May 18, 2024



Self-supervised depth estimation algorithms rely heavily on frame-warping relationships, exhibiting substantial performance degradation when applied in challenging circumstances, such as low-visibility and nighttime scenarios with varying illumination conditions. Addressing this challenge, we introduce an algorithm designed to achieve accurate self-supervised stereo depth estimation focusing on nighttime conditions. Specifically, we use pretrained visual foundation models to extract generalised features across challenging scenes and present an efficient method for matching and integrating these features from stereo frames. Moreover, to prevent pixels violating photometric consistency assumption from negatively affecting the depth predictions, we propose a novel masking approach designed to filter out such pixels. Lastly, addressing weaknesses in the evaluation of current depth estimation algorithms, we present novel evaluation metrics. Our experiments, conducted on challenging datasets including Oxford RobotCar and Multi-Spectral Stereo, demonstrate the robust improvements realized by our approach. Code is available at: https://github.com/madhubabuv/dtd
Spherical Mask: Coarse-to-Fine 3D Point Cloud Instance Segmentation with Spherical Representation
Dec 18, 2023Coarse-to-fine 3D instance segmentation methods show weak performances compared to recent Grouping-based, Kernel-based and Transformer-based methods. We argue that this is due to two limitations: 1) Instance size overestimation by axis-aligned bounding box(AABB) 2) False negative error accumulation from inaccurate box to the refinement phase. In this work, we introduce Spherical Mask, a novel coarse-to-fine approach based on spherical representation, overcoming those two limitations with several benefits. Specifically, our coarse detection estimates each instance with a 3D polygon using a center and radial distance predictions, which avoids excessive size estimation of AABB. To cut the error propagation in the existing coarse-to-fine approaches, we virtually migrate points based on the polygon, allowing all foreground points, including false negatives, to be refined. During inference, the proposal and point migration modules run in parallel and are assembled to form binary masks of instances. We also introduce two margin-based losses for the point migration to enforce corrections for the false positives/negatives and cohesion of foreground points, significantly improving the performance. Experimental results from three datasets, such as ScanNetV2, S3DIS, and STPLS3D, show that our proposed method outperforms existing works, demonstrating the effectiveness of the new instance representation with spherical coordinates.
DynPoint: Dynamic Neural Point For View Synthesis
Oct 31, 2023



The introduction of neural radiance fields has greatly improved the effectiveness of view synthesis for monocular videos. However, existing algorithms face difficulties when dealing with uncontrolled or lengthy scenarios, and require extensive training time specific to each new scenario. To tackle these limitations, we propose DynPoint, an algorithm designed to facilitate the rapid synthesis of novel views for unconstrained monocular videos. Rather than encoding the entirety of the scenario information into a latent representation, DynPoint concentrates on predicting the explicit 3D correspondence between neighboring frames to realize information aggregation. Specifically, this correspondence prediction is achieved through the estimation of consistent depth and scene flow information across frames. Subsequently, the acquired correspondence is utilized to aggregate information from multiple reference frames to a target frame, by constructing hierarchical neural point clouds. The resulting framework enables swift and accurate view synthesis for desired views of target frames. The experimental results obtained demonstrate the considerable acceleration of training time achieved - typically an order of magnitude - by our proposed method while yielding comparable outcomes compared to prior approaches. Furthermore, our method exhibits strong robustness in handling long-duration videos without learning a canonical representation of video content.
Tighter Variational Bounds are Not Necessarily Better. A Research Report on Implementation, Ablation Study, and Extensions
Sep 23, 2022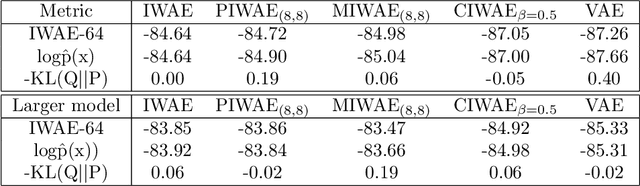
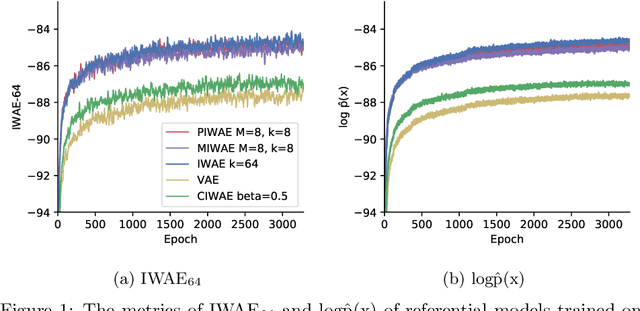
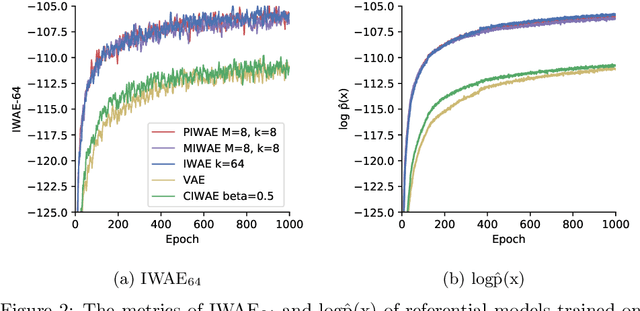

This report explains, implements and extends the works presented in "Tighter Variational Bounds are Not Necessarily Better" (T Rainforth et al., 2018). We provide theoretical and empirical evidence that increasing the number of importance samples $K$ in the importance weighted autoencoder (IWAE) (Burda et al., 2016) degrades the signal-to-noise ratio (SNR) of the gradient estimator in the inference network and thereby affecting the full learning process. In other words, even though increasing $K$ decreases the standard deviation of the gradients, it also reduces the magnitude of the true gradient faster, thereby increasing the relative variance of the gradient updates. Extensive experiments are performed to understand the importance of $K$. These experiments suggest that tighter variational bounds are beneficial for the generative network, whereas looser bounds are preferable for the inference network. With these insights, three methods are implemented and studied: the partially importance weighted autoencoder (PIWAE), the multiply importance weighted autoencoder (MIWAE) and the combination importance weighted autoencoder (CIWAE). Each of these three methods entails IWAE as a special case but employs the importance weights in different ways to ensure a higher SNR of the gradient estimators. In our research study and analysis, the efficacy of these algorithms is tested on multiple datasets such as MNIST and Omniglot. Finally, we demonstrate that the three presented IWAE variations are able to generate approximate posterior distributions that are much closer to the true posterior distribution than for the IWAE, while matching the performance of the IWAE generative network or potentially outperforming it in the case of PIWAE.
Sample, Crop, Track: Self-Supervised Mobile 3D Object Detection for Urban Driving LiDAR
Sep 21, 2022
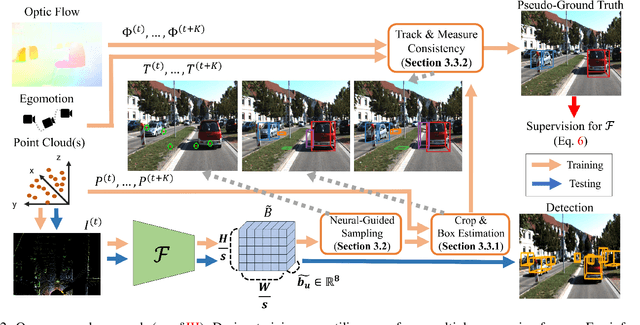
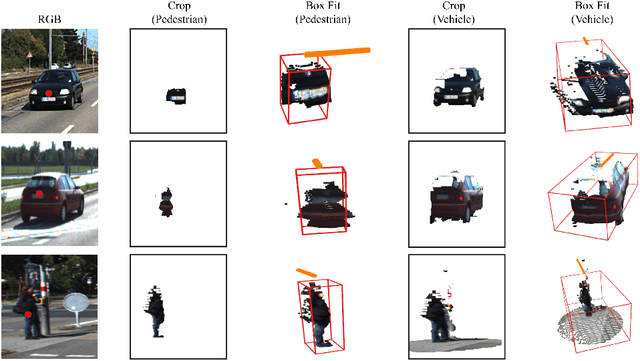
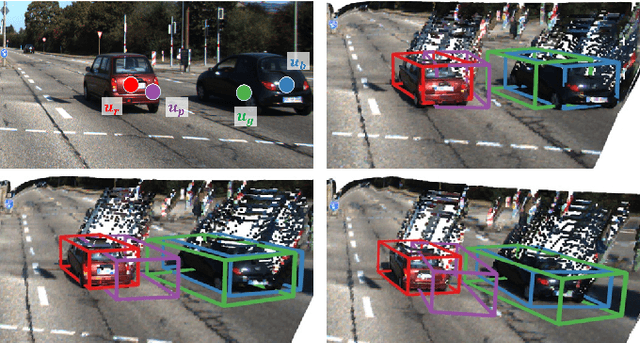
Deep learning has led to great progress in the detection of mobile (i.e. movement-capable) objects in urban driving scenes in recent years. Supervised approaches typically require the annotation of large training sets; there has thus been great interest in leveraging weakly, semi- or self-supervised methods to avoid this, with much success. Whilst weakly and semi-supervised methods require some annotation, self-supervised methods have used cues such as motion to relieve the need for annotation altogether. However, a complete absence of annotation typically degrades their performance, and ambiguities that arise during motion grouping can inhibit their ability to find accurate object boundaries. In this paper, we propose a new self-supervised mobile object detection approach called SCT. This uses both motion cues and expected object sizes to improve detection performance, and predicts a dense grid of 3D oriented bounding boxes to improve object discovery. We significantly outperform the state-of-the-art self-supervised mobile object detection method TCR on the KITTI tracking benchmark, and achieve performance that is within 30% of the fully supervised PV-RCNN++ method for IoUs <= 0.5.
When the Sun Goes Down: Repairing Photometric Losses for All-Day Depth Estimation
Jun 28, 2022
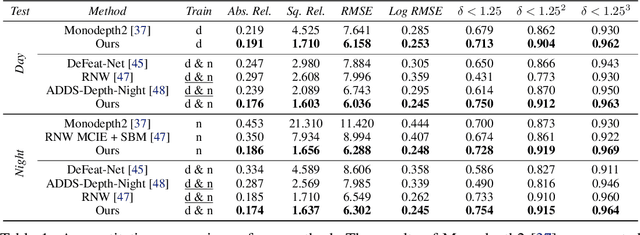
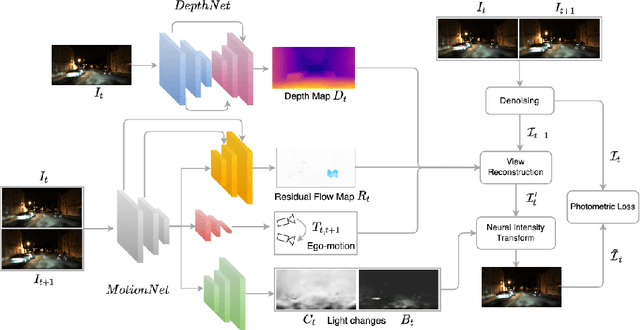
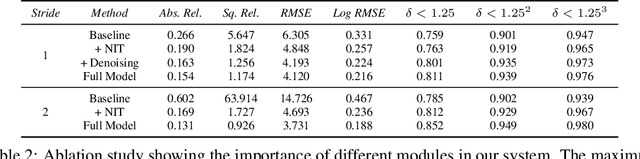
Self-supervised deep learning methods for joint depth and ego-motion estimation can yield accurate trajectories without needing ground-truth training data. However, as they typically use photometric losses, their performance can degrade significantly when the assumptions these losses make (e.g. temporal illumination consistency, a static scene, and the absence of noise and occlusions) are violated. This limits their use for e.g. nighttime sequences, which tend to contain many point light sources (including on dynamic objects) and low signal-to-noise ratio (SNR) in darker image regions. In this paper, we show how to use a combination of three techniques to allow the existing photometric losses to work for both day and nighttime images. First, we introduce a per-pixel neural intensity transformation to compensate for the light changes that occur between successive frames. Second, we predict a per-pixel residual flow map that we use to correct the reprojection correspondences induced by the estimated ego-motion and depth from the networks. And third, we denoise the training images to improve the robustness and accuracy of our approach. These changes allow us to train a single model for both day and nighttime images without needing separate encoders or extra feature networks like existing methods. We perform extensive experiments and ablation studies on the challenging Oxford RobotCar dataset to demonstrate the efficacy of our approach for both day and nighttime sequences.
Real-Time Hybrid Mapping of Populated Indoor Scenes using a Low-Cost Monocular UAV
Mar 04, 2022
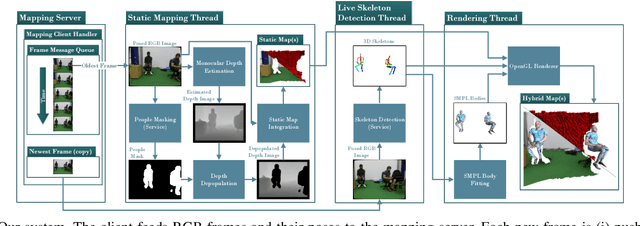
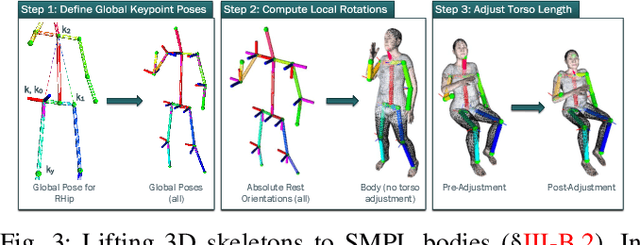
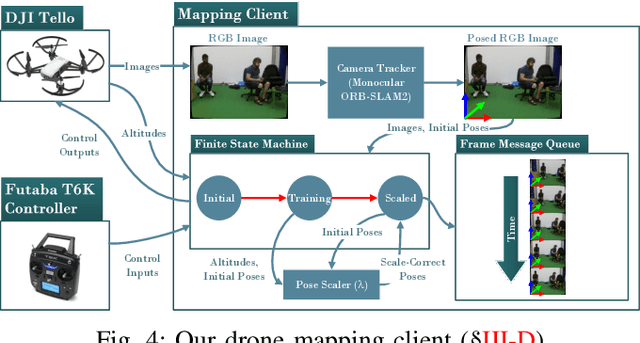
Unmanned aerial vehicles (UAVs) have been used for many applications in recent years, from urban search and rescue, to agricultural surveying, to autonomous underground mine exploration. However, deploying UAVs in tight, indoor spaces, especially close to humans, remains a challenge. One solution, when limited payload is required, is to use micro-UAVs, which pose less risk to humans and typically cost less to replace after a crash. However, micro-UAVs can only carry a limited sensor suite, e.g. a monocular camera instead of a stereo pair or LiDAR, complicating tasks like dense mapping and markerless multi-person 3D human pose estimation, which are needed to operate in tight environments around people. Monocular approaches to such tasks exist, and dense monocular mapping approaches have been successfully deployed for UAV applications. However, despite many recent works on both marker-based and markerless multi-UAV single-person motion capture, markerless single-camera multi-person 3D human pose estimation remains a much earlier-stage technology, and we are not aware of existing attempts to deploy it in an aerial context. In this paper, we present what is thus, to our knowledge, the first system to perform simultaneous mapping and multi-person 3D human pose estimation from a monocular camera mounted on a single UAV. In particular, we show how to loosely couple state-of-the-art monocular depth estimation and monocular 3D human pose estimation approaches to reconstruct a hybrid map of a populated indoor scene in real time. We validate our component-level design choices via extensive experiments on the large-scale ScanNet and GTA-IM datasets. To evaluate our system-level performance, we also construct a new Oxford Hybrid Mapping dataset of populated indoor scenes.