 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization in 3D Shape Generation: An Empirical Study
Dec 29, 2025Generative models are increasingly used in 3D vision to synthesize novel shapes, yet it remains unclear whether their generation relies on memorizing training shapes. Understanding their memorization could help prevent training data leakage and improve the diversity of generated results. In this paper, we design an evaluation framework to quantify memorization in 3D generative models and study the influence of different data and modeling designs on memorization. We first apply our framework to quantify memorization in existing methods. Next, through controlled experiments with a latent vector-set (Vecset) diffusion model, we find that, on the data side, memorization depends on data modality, and increases with data diversity and finer-grained conditioning; on the modeling side, it peaks at a moderate guidance scale and can be mitigated by longer Vecsets and simple rotation augmentation. Together, our framework and analysis provide an empirical understanding of memorization in 3D generative models and suggest simple yet effective strategies to reduce it without degrading generation quality. Our code is available at https://github.com/zlab-princeton/3d_mem.
OPENTOUCH: Bringing Full-Hand Touch to Real-World Interaction
Dec 18, 2025The human hand is our primary interface to the physical world, yet egocentric perception rarely knows when, where, or how forcefully it makes contact. Robust wearable tactile sensors are scarce, and no existing in-the-wild datasets align first-person video with full-hand touch. To bridge the gap between visual perception and physical interaction, we present OpenTouch, the first in-the-wild egocentric full-hand tactile dataset, containing 5.1 hours of synchronized video-touch-pose data and 2,900 curated clips with detailed text annotations. Using OpenTouch, we introduce retrieval and classification benchmarks that probe how touch grounds perception and action. We show that tactile signals provide a compact yet powerful cue for grasp understanding, strengthen cross-modal alignment, and can be reliably retrieved from in-the-wild video queries. By releasing this annotated vision-touch-pose dataset and benchmark, we aim to advance multimodal egocentric perception, embodied learning, and contact-rich robotic manipulation.
RISE: Single Static Radar-based Indoor Scene Understanding
Nov 18, 2025Robust and privacy-preserving indoor scene understanding remains a fundamental open problem. While optical sensors such as RGB and LiDAR offer high spatial fidelity, they suffer from severe occlusions and introduce privacy risks in indoor environments. In contrast, millimeter-wave (mmWave) radar preserves privacy and penetrates obstacles, but its inherently low spatial resolution makes reliable geometric reasoning difficult. We introduce RISE, the first benchmark and system for single-static-radar indoor scene understanding, jointly targeting layout reconstruction and object detection. RISE is built upon the key insight that multipath reflections, traditionally treated as noise, encode rich geometric cues. To exploit this, we propose a Bi-Angular Multipath Enhancement that explicitly models Angle-of-Arrival and Angle-of-Departure to recover secondary (ghost) reflections and reveal invisible structures. On top of these enhanced observations, a simulation-to-reality Hierarchical Diffusion framework transforms fragmented radar responses into complete layout reconstruction and object detection. Our benchmark contains 50,000 frames collected across 100 real indoor trajectories, forming the first large-scale dataset dedicated to radar-based indoor scene understanding. Extensive experiments show that RISE reduces the Chamfer Distance by 60% (down to 16 cm) compared to the state of the art in layout reconstruction, and delivers the first mmWave-based object detection, achieving 58% IoU. These results establish RISE as a new foundation for geometry-aware and privacy-preserving indoor scene understanding using a single static radar.
Abstract 3D Perception for Spatial Intelligence in Vision-Language Models
Nov 14, 2025Vision-language models (VLMs) struggle with 3D-related tasks such as spatial cognition and physical understanding, which are crucial for real-world applications like robotics and embodied agents. We attribute this to a modality gap between the 3D tasks and the 2D training of VLM, which led to inefficient retrieval of 3D information from 2D input. To bridge this gap, we introduce SandboxVLM, a simple yet effective framework that leverages abstract bounding boxes to encode geometric structure and physical kinematics for VLM. Specifically, we design a 3D Sandbox reconstruction and perception pipeline comprising four stages: generating multi-view priors with abstract control, proxy elevation, multi-view voting and clustering, and 3D-aware reasoning. Evaluated in zero-shot settings across multiple benchmarks and VLM backbones, our approach consistently improves spatial intelligence, achieving an 8.3\% gain on SAT Real compared with baseline methods for instance. These results demonstrate that equipping VLMs with a 3D abstraction substantially enhances their 3D reasoning ability without additional training, suggesting new possibilities for general-purpose embodied intelligence.
MLA: A Multisensory Language-Action Model for Multimodal Understanding and Forecasting in Robotic Manipulation
Sep 30, 2025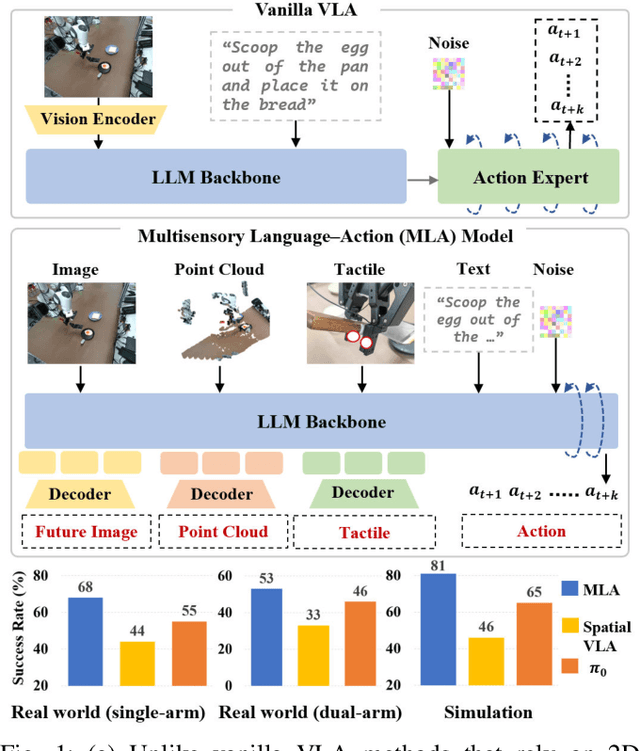
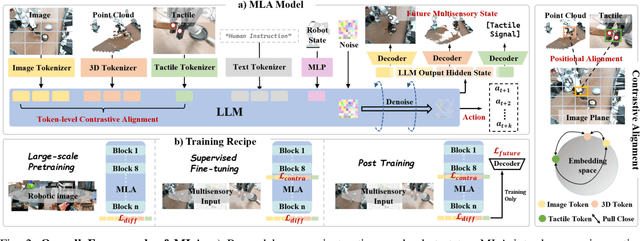
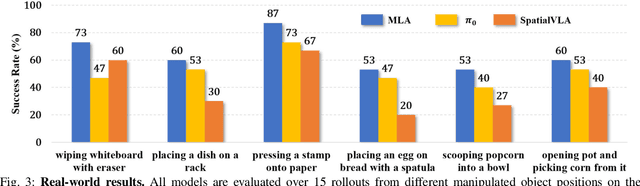

Vision-language-action models (VLAs) have shown generalization capabilities in robotic manipulation tasks by inheriting from vision-language models (VLMs) and learning action generation. Most VLA models focus on interpreting vision and language to generate actions, whereas robots must perceive and interact within the spatial-physical world. This gap highlights the need for a comprehensive understanding of robotic-specific multisensory information, which is crucial for achieving complex and contact-rich control. To this end, we introduce a multisensory language-action (MLA) model that collaboratively perceives heterogeneous sensory modalities and predicts future multisensory objectives to facilitate physical world modeling. Specifically, to enhance perceptual representations, we propose an encoder-free multimodal alignment scheme that innovatively repurposes the large language model itself as a perception module, directly interpreting multimodal cues by aligning 2D images, 3D point clouds, and tactile tokens through positional correspondence. To further enhance MLA's understanding of physical dynamics, we design a future multisensory generation post-training strategy that enables MLA to reason about semantic, geometric, and interaction information, providing more robust conditions for action generation. For evaluation, the MLA model outperforms the previous state-of-the-art 2D and 3D VLA methods by 12% and 24% in complex, contact-rich real-world tasks, respectively, while also demonstrating improved generalization to unseen configurations. Project website: https://sites.google.com/view/open-mla
SR3D: Unleashing Single-view 3D Reconstruction for Transparent and Specular Object Grasping
May 30, 2025Recent advancements in 3D robotic manipulation have improved grasping of everyday objects, but transparent and specular materials remain challenging due to depth sensing limitations. While several 3D reconstruction and depth completion approaches address these challenges, they suffer from setup complexity or limited observation information utilization. To address this, leveraging the power of single view 3D object reconstruction approaches, we propose a training free framework SR3D that enables robotic grasping of transparent and specular objects from a single view observation. Specifically, given single view RGB and depth images, SR3D first uses the external visual models to generate 3D reconstructed object mesh based on RGB image. Then, the key idea is to determine the 3D object's pose and scale to accurately localize the reconstructed object back into its original depth corrupted 3D scene. Therefore, we propose view matching and keypoint matching mechanisms,which leverage both the 2D and 3D's inherent semantic and geometric information in the observation to determine the object's 3D state within the scene, thereby reconstructing an accurate 3D depth map for effective grasp detection. Experiments in both simulation and real world show the reconstruction effectiveness of SR3D.
TransDiff: Diffusion-Based Method for Manipulating Transparent Objects Using a Single RGB-D Image
Mar 17, 2025Manipulating transparent objects presents significant challenges due to the complexities introduced by their reflection and refraction properties, which considerably hinder the accurate estimation of their 3D shapes. To address these challenges, we propose a single-view RGB-D-based depth completion framework, TransDiff, that leverages the Denoising Diffusion Probabilistic Models(DDPM) to achieve material-agnostic object grasping in desktop. Specifically, we leverage features extracted from RGB images, including semantic segmentation, edge maps, and normal maps, to condition the depth map generation process. Our method learns an iterative denoising process that transforms a random depth distribution into a depth map, guided by initially refined depth information, ensuring more accurate depth estimation in scenarios involving transparent objects. Additionally, we propose a novel training method to better align the noisy depth and RGB image features, which are used as conditions to refine depth estimation step by step. Finally, we utilized an improved inference process to accelerate the denoising procedure. Through comprehensive experimental validation, we demonstrate that our method significantly outperforms the baselines in both synthetic and real-world benchmarks with acceptable inference time. The demo of our method can be found on https://wang-haoxiao.github.io/TransDiff/
Empowering Sparse-Input Neural Radiance Fields with Dual-Level Semantic Guidance from Dense Novel Views
Mar 04, 2025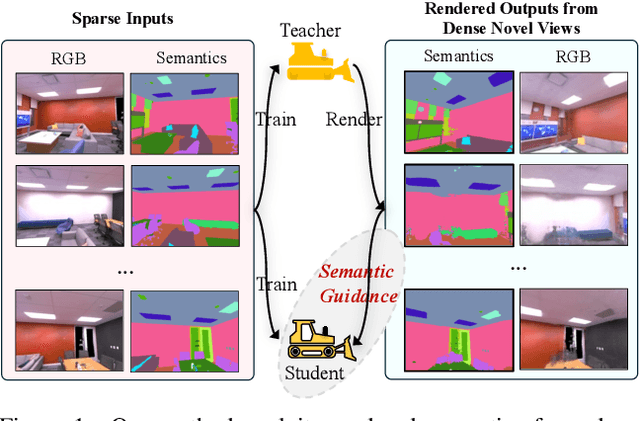

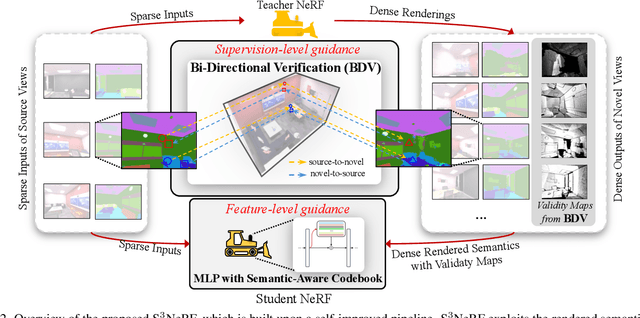

Neural Radiance Fields (NeRF) have shown remarkable capabilities for photorealistic novel view synthesis. One major deficiency of NeRF is that dense inputs are typically required, and the rendering quality will drop drastically given sparse inputs. In this paper, we highlight the effectiveness of rendered semantics from dense novel views, and show that rendered semantics can be treated as a more robust form of augmented data than rendered RGB. Our method enhances NeRF's performance by incorporating guidance derived from the rendered semantics. The rendered semantic guidance encompasses two levels: the supervision level and the feature level. The supervision-level guidance incorporates a bi-directional verification module that decides the validity of each rendered semantic label, while the feature-level guidance integrates a learnable codebook that encodes semantic-aware information, which is queried by each point via the attention mechanism to obtain semantic-relevant predictions. The overall semantic guidance is embedded into a self-improved pipeline. We also introduce a more challenging sparse-input indoor benchmark, where the number of inputs is limited to as few as 6. Experiments demonstrate the effectiveness of our method and it exhibits superior performance compared to existing approaches.
RAD: A Dataset and Benchmark for Real-Life Anomaly Detection with Robotic Observations
Oct 01, 2024



Recent advancements in industrial anomaly detection have been hindered by the lack of realistic datasets that accurately represent real-world conditions. Existing algorithms are often developed and evaluated using idealized datasets, which deviate significantly from real-life scenarios characterized by environmental noise and data corruption such as fluctuating lighting conditions, variable object poses, and unstable camera positions. To address this gap, we introduce the Realistic Anomaly Detection (RAD) dataset, the first multi-view RGB-based anomaly detection dataset specifically collected using a real robot arm, providing unique and realistic data scenarios. RAD comprises 4765 images across 13 categories and 4 defect types, collected from more than 50 viewpoints, providing a comprehensive and realistic benchmark. This multi-viewpoint setup mirrors real-world conditions where anomalies may not be detectable from every perspective. Moreover, by sampling varying numbers of views, the algorithm's performance can be comprehensively evaluated across different viewpoints. This approach enhances the thoroughness of performance assessment and helps improve the algorithm's robustness. Besides, to support 3D multi-view reconstruction algorithms, we propose a data augmentation method to improve the accuracy of pose estimation and facilitate the reconstruction of 3D point clouds. We systematically evaluate state-of-the-art RGB-based and point cloud-based models using RAD, identifying limitations and future research directions. The code and dataset could found at https://github.com/kaichen-z/RAD
MambaLoc: Efficient Camera Localisation via State Space Model
Aug 20, 2024



Location information is pivotal for the automation and intelligence of terminal devices and edge-cloud IoT systems, such as autonomous vehicles and augmented reality. However, achieving reliable positioning across diverse IoT applications remains challenging due to significant training costs and the necessity of densely collected data. To tackle these issues, we have innovatively applied the selective state space (SSM) model to visual localization, introducing a new model named MambaLoc. The proposed model demonstrates exceptional training efficiency by capitalizing on the SSM model's strengths in efficient feature extraction, rapid computation, and memory optimization, and it further ensures robustness in sparse data environments due to its parameter sparsity. Additionally, we propose the Global Information Selector (GIS), which leverages selective SSM to implicitly achieve the efficient global feature extraction capabilities of Non-local Neural Networks. This design leverages the computational efficiency of the SSM model alongside the Non-local Neural Networks' capacity to capture long-range dependencies with minimal layers. Consequently, the GIS enables effective global information capture while significantly accelerating convergence. Our extensive experimental validation using public indoor and outdoor datasets first demonstrates our model's effectiveness, followed by evidence of its versatility with various existing localization models. Our code and models are publicly available to support further research and development in this area.