 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Sparse-Input Neural Radiance Fields with Dual-Level Semantic Guidance from Dense Novel Views
Paper and Code
Mar 04, 2025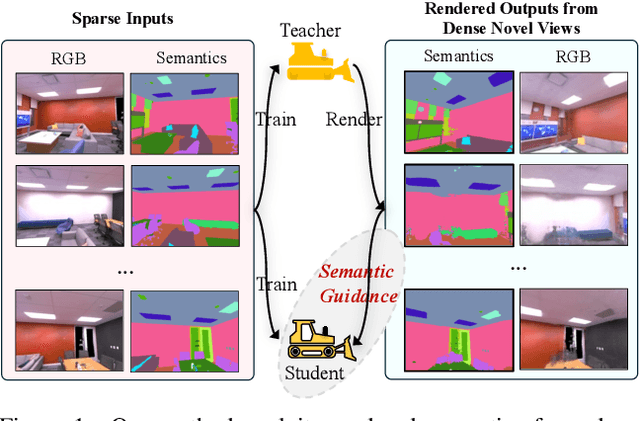

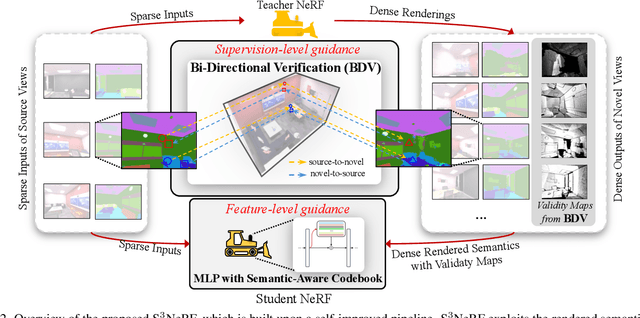

Neural Radiance Fields (NeRF) have shown remarkable capabilities for photorealistic novel view synthesis. One major deficiency of NeRF is that dense inputs are typically required, and the rendering quality will drop drastically given sparse inputs. In this paper, we highlight the effectiveness of rendered semantics from dense novel views, and show that rendered semantics can be treated as a more robust form of augmented data than rendered RGB. Our method enhances NeRF's performance by incorporating guidance derived from the rendered semantics. The rendered semantic guidance encompasses two levels: the supervision level and the feature level. The supervision-level guidance incorporates a bi-directional verification module that decides the validity of each rendered semantic label, while the feature-level guidance integrates a learnable codebook that encodes semantic-aware information, which is queried by each point via the attention mechanism to obtain semantic-relevant predictions. The overall semantic guidance is embedded into a self-improved pipeline. We also introduce a more challenging sparse-input indoor benchmark, where the number of inputs is limited to as few as 6. Experiments demonstrate the effectiveness of our method and it exhibits superior performance compared to existing approaches.