 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-P-to-3: Zero-Shot Partial-View Images to 3D Object
May 29, 2025



Generative 3D reconstruction shows strong potential in incomplete observations. While sparse-view and single-image reconstruction are well-researched, partial observation remains underexplored. In this context, dense views are accessible only from a specific angular range, with other perspectives remaining inaccessible. This task presents two main challenges: (i) limited View Range: observations confined to a narrow angular scope prevent effective traditional interpolation techniques that require evenly distributed perspectives. (ii) inconsistent Generation: views created for invisible regions often lack coherence with both visible regions and each other, compromising reconstruction consistency. To address these challenges, we propose \method, a novel training-free approach that integrates the local dense observations and multi-source priors for reconstruction. Our method introduces a fusion-based strategy to effectively align these priors in DDIM sampling, thereby generating multi-view consistent images to supervise invisible views. We further design an iterative refinement strategy, which uses the geometric structures of the object to enhance reconstruction quality. Extensive experiments on multiple datasets show the superiority of our method over SOTAs, especially in invisible regions.
Taming Video Diffusion Prior with Scene-Grounding Guidance for 3D Gaussian Splatting from Sparse Inputs
Mar 07, 2025



Despite recent successes in novel view synthesis using 3D Gaussian Splatting (3DGS), modeling scenes with sparse inputs remains a challenge. In this work, we address two critical yet overlooked issues in real-world sparse-input modeling: extrapolation and occlusion. To tackle these issues, we propose to use a reconstruction by generation pipeline that leverages learned priors from video diffusion models to provide plausible interpretations for regions outside the field of view or occluded. However, the generated sequences exhibit inconsistencies that do not fully benefit subsequent 3DGS modeling. To address the challenge of inconsistencies, we introduce a novel scene-grounding guidance based on rendered sequences from an optimized 3DGS, which tames the diffusion model to generate consistent sequences. This guidance is training-free and does not require any fine-tuning of the diffusion model. To facilitate holistic scene modeling, we also propose a trajectory initialization method. It effectively identifies regions that are outside the field of view and occluded. We further design a scheme tailored for 3DGS optimization with generated sequences. Experiments demonstrate that our method significantly improves upon the baseline and achieves state-of-the-art performance on challenging benchmarks.
Empowering Sparse-Input Neural Radiance Fields with Dual-Level Semantic Guidance from Dense Novel Views
Mar 04, 2025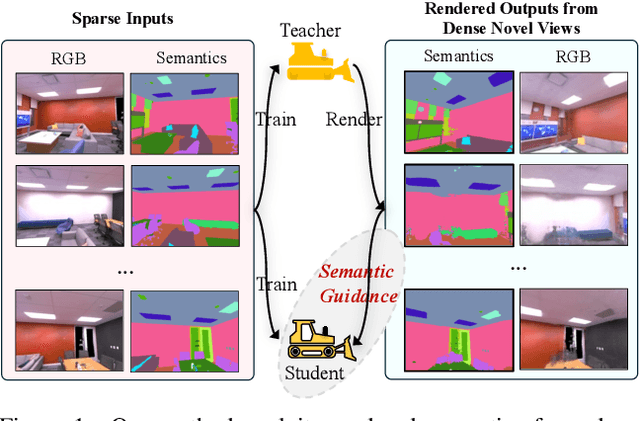

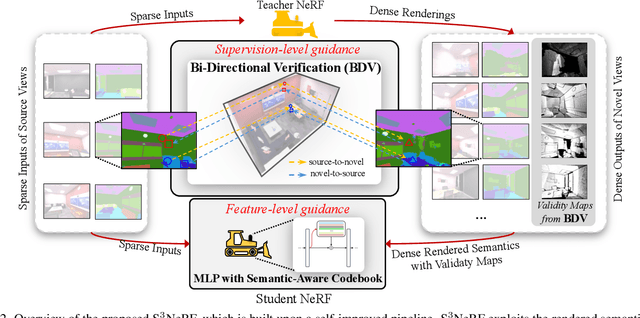

Neural Radiance Fields (NeRF) have shown remarkable capabilities for photorealistic novel view synthesis. One major deficiency of NeRF is that dense inputs are typically required, and the rendering quality will drop drastically given sparse inputs. In this paper, we highlight the effectiveness of rendered semantics from dense novel views, and show that rendered semantics can be treated as a more robust form of augmented data than rendered RGB. Our method enhances NeRF's performance by incorporating guidance derived from the rendered semantics. The rendered semantic guidance encompasses two levels: the supervision level and the feature level. The supervision-level guidance incorporates a bi-directional verification module that decides the validity of each rendered semantic label, while the feature-level guidance integrates a learnable codebook that encodes semantic-aware information, which is queried by each point via the attention mechanism to obtain semantic-relevant predictions. The overall semantic guidance is embedded into a self-improved pipeline. We also introduce a more challenging sparse-input indoor benchmark, where the number of inputs is limited to as few as 6. Experiments demonstrate the effectiveness of our method and it exhibits superior performance compared to existing approaches.
CVT-xRF: Contrastive In-Voxel Transformer for 3D Consistent Radiance Fields from Sparse Inputs
Mar 25, 2024Neural Radiance Fields (NeRF) have shown impressive capabilities for photorealistic novel view synthesis when trained on dense inputs. However, when trained on sparse inputs, NeRF typically encounters issues of incorrect density or color predictions, mainly due to insufficient coverage of the scene causing partial and sparse supervision, thus leading to significant performance degradation. While existing works mainly consider ray-level consistency to construct 2D learning regularization based on rendered color, depth, or semantics on image planes, in this paper we propose a novel approach that models 3D spatial field consistency to improve NeRF's performance with sparse inputs. Specifically, we first adopt a voxel-based ray sampling strategy to ensure that the sampled rays intersect with a certain voxel in 3D space. We then randomly sample additional points within the voxel and apply a Transformer to infer the properties of other points on each ray, which are then incorporated into the volume rendering. By backpropagating through the rendering loss, we enhance the consistency among neighboring points. Additionally, we propose to use a contrastive loss on the encoder output of the Transformer to further improve consistency within each voxel. Experiments demonstrate that our method yields significant improvement over different radiance fields in the sparse inputs setting, and achieves comparable performance with current works.
Robust Partial Matching for Person Search in the Wild
Apr 20, 2020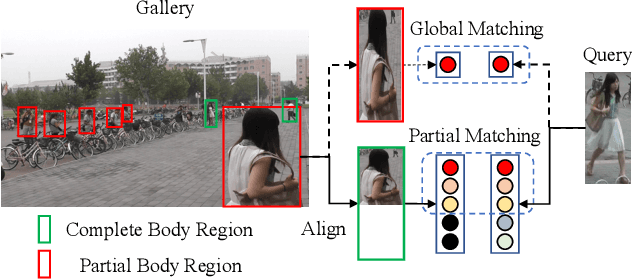
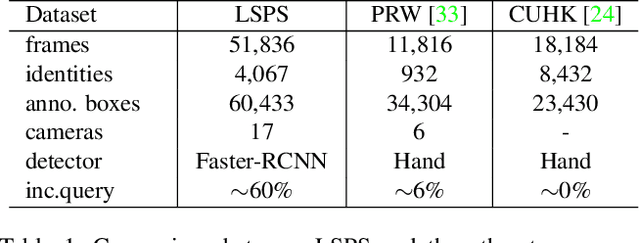
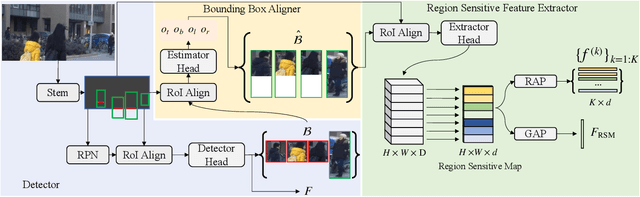
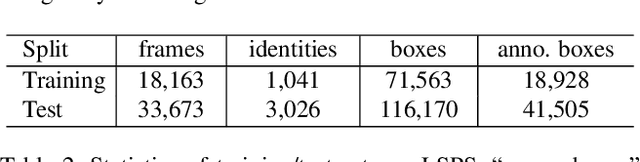
Various factors like occlusions, backgrounds, etc., would lead to misaligned detected bounding boxes , e.g., ones covering only portions of human body. This issue is common but overlooked by previous person search works. To alleviate this issue, this paper proposes an Align-to-Part Network (APNet) for person detection and re-Identification (reID). APNet refines detected bounding boxes to cover the estimated holistic body regions, from which discriminative part features can be extracted and aligned. Aligned part features naturally formulate reID as a partial feature matching procedure, where valid part features are selected for similarity computation, while part features on occluded or noisy regions are discarded. This design enhances the robustness of person search to real-world challenges with marginal computation overhead. This paper also contributes a Large-Scale dataset for Person Search in the wild (LSPS), which is by far the largest and the most challenging dataset for person search. Experiments show that APNet brings considerable performance improvement on LSPS. Meanwhile, it achieves competitive performance on existing person search benchmarks like CUHK-SYSU and PRW.