 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneCanvas: 3D Scene Understanding via Panoramic Reprojection
Jun 17, 2026Existing approaches to 3D scene understanding in Vision-Language Models (VLMs) either rely on complex, model-specific geometry encoders or large training budgets in pursuit of spatial reasoning. Instead, OneCanvas aggregates patch features from all views onto a single equirectangular panoramic canvas. Namely, each patch is unprojected to a 3D world coordinate using its depth and camera pose, then placed on the canvas at the continuous longitude and latitude of that point as seen from the canvas origin, with no rasterization or aggregation across overlapping views. A 3D position embedding of the patch's metric coordinates is added to its feature, restoring the depth lost when collapsing the world position to an angular canvas coordinate. Patches from all frames thus share one spatial coordinate system with no fusion or major architectural modifications of the backbone. The pretrained VLM consumes this representation as if it were an ordinary image. Because the canvas can be centered on any pose of interest, the same representation directly supports situated reasoning from a specific viewpoint, a common requirement in robotics and embodied AI. Thanks to this representation, we can also introduce a spatial pretraining curriculum: by procedurally placing patch features of objects, drawn from real images, at chosen 3D world positions on an otherwise empty canvas, we generate on-the-fly supervision spanning a broad range of spatial reasoning tasks, with answer distributions controlled to reduce spatial reasoning shortcuts. OneCanvas achieves state-of-the-art accuracy on SQA3D and VSI-Bench, and generalizes to out-of-distribution data on SPBench, using an order of magnitude less training compute than the strongest competing methods.
AnchorSplat: Feed-Forward 3D Gaussian Splatting with 3D Geometric Priors
Apr 09, 2026Recent feed-forward Gaussian reconstruction models adopt a pixel-aligned formulation that maps each 2D pixel to a 3D Gaussian, entangling Gaussian representations tightly with the input images. In this paper, we propose AnchorSplat, a novel feed-forward 3DGS framework for scene-level reconstruction that represents the scene directly in 3D space. AnchorSplat introduces an anchor-aligned Gaussian representation guided by 3D geometric priors (e.g., sparse point clouds, voxels, or RGB-D point clouds), enabling a more geometry-aware renderable 3D Gaussians that is independent of image resolution and number of views. This design substantially reduces the number of required Gaussians, improving computational efficiency while enhancing reconstruction fidelity. Beyond the anchor-aligned design, we utilize a Gaussian Refiner to adjust the intermediate Gaussiansy via merely a few forward passes. Experiments on the ScanNet++ v2 NVS benchmark demonstrate the SOTA performance, outperforming previous methods with more view-consistent and substantially fewer Gaussian primitives.
Reliev3R: Relieving Feed-forward Reconstruction from Multi-View Geometric Annotations
Apr 01, 2026With recent advances, Feed-forward Reconstruction Models (FFRMs) have demonstrated great potential in reconstruction quality and adaptiveness to multiple downstream tasks. However, the excessive reliance on multi-view geometric annotations, e.g. 3D point maps and camera poses, makes the fully-supervised training scheme of FFRMs difficult to scale up. In this paper, we propose Reliev3R, a weakly-supervised paradigm for training FFRMs from scratch without cost-prohibitive multi-view geometric annotations. Relieving the reliance on geometric sensory data and compute-exhaustive structure-from-motion preprocessing, our method draws 3D knowledge directly from monocular relative depths and image sparse correspondences given by zero-shot predictions of pretrained models. At the core of Reliev3R, we design an ambiguity-aware relative depth loss and a trigonometry-based reprojection loss to facilitate supervision for multi-view geometric consistency. Training from scratch with the less data, Reliev3R catches up with its fully-supervised sibling models, taking a step towards low-cost 3D reconstruction supervisions and scalable FFRMs.
GAP-MLLM: Geometry-Aligned Pre-training for Activating 3D Spatial Perception in Multimodal Large Language Models
Mar 17, 2026Multimodal Large Language Models (MLLMs) demonstrate exceptional semantic reasoning but struggle with 3D spatial perception when restricted to pure RGB inputs. Despite leveraging implicit geometric priors from 3D reconstruction models, image-based methods still exhibit a notable performance gap compared to methods using explicit 3D data. We argue that this gap does not arise from insufficient geometric priors, but from a misalignment in the training paradigm: text-dominated fine-tuning fails to activate geometric representations within MLLMs. Existing approaches typically resort to naive feature concatenation and optimize directly for downstream tasks without geometry-specific supervision, leading to suboptimal structural utilization. To address this limitation, we propose GAP-MLLM, a Geometry-Aligned Pre-training paradigm that explicitly activates structural perception before downstream adaptation. Specifically, we introduce a visual-prompted joint task that compels the MLLMs to predict sparse pointmaps alongside semantic labels, thereby enforcing geometric awareness. Furthermore, we design a multi-level progressive fusion module with a token-level gating mechanism, enabling adaptive integration of geometric priors without suppressing semantic reasoning. Extensive experiments demonstrate that GAP-MLLM significantly enhances geometric feature fusion and consistently enhances performance across 3D visual grounding, 3D dense captioning, and 3D video object detection tasks.
VGGT-Det: Mining VGGT Internal Priors for Sensor-Geometry-Free Multi-View Indoor 3D Object Detection
Mar 01, 2026Current multi-view indoor 3D object detectors rely on sensor geometry that is costly to obtain (i.e., precisely calibrated multi-view camera poses) to fuse multi-view information into a global scene representation, limiting deployment in real-world scenes. We target a more practical setting: Sensor-Geometry-Free (SG-Free) multi-view indoor 3D object detection, where there are no sensor-provided geometric inputs (multi-view poses or depth). Recent Visual Geometry Grounded Transformer (VGGT) shows that strong 3D cues can be inferred directly from images. Building on this insight, we present VGGT-Det, the first framework tailored for SG-Free multi-view indoor 3D object detection. Rather than merely consuming VGGT predictions, our method integrates VGGT encoder into a transformer-based pipeline. To effectively leverage both the semantic and geometric priors from inside VGGT, we introduce two novel key components: (i) Attention-Guided Query Generation (AG): exploits VGGT attention maps as semantic priors to initialize object queries, improving localization by focusing on object regions while preserving global spatial structure; (ii) Query-Driven Feature Aggregation (QD): a learnable See-Query interacts with object queries to 'see' what they need, and then dynamically aggregates multi-level geometric features across VGGT layers that progressively lift 2D features into 3D. Experiments show that VGGT-Det significantly surpasses the best-performing method in the SG-Free setting by 4.4 and 8.6 mAP@0.25 on ScanNet and ARKitScenes, respectively. Ablation study shows that VGGT's internally learned semantic and geometric priors can be effectively leveraged by our AG and QD.
Map2Thought: Explicit 3D Spatial Reasoning via Metric Cognitive Maps
Jan 16, 2026We propose Map2Thought, a framework that enables explicit and interpretable spatial reasoning for 3D VLMs. The framework is grounded in two key components: Metric Cognitive Map (Metric-CogMap) and Cognitive Chain-of-Thought (Cog-CoT). Metric-CogMap provides a unified spatial representation by integrating a discrete grid for relational reasoning with a continuous, metric-scale representation for precise geometric understanding. Building upon the Metric-CogMap, Cog-CoT performs explicit geometric reasoning through deterministic operations, including vector operations, bounding-box distances, and occlusion-aware appearance order cues, producing interpretable inference traces grounded in 3D structure. Experimental results show that Map2Thought enables explainable 3D understanding, achieving 59.9% accuracy using only half the supervision, closely matching the 60.9% baseline trained with the full dataset. It consistently outperforms state-of-the-art methods by 5.3%, 4.8%, and 4.0% under 10%, 25%, and 50% training subsets, respectively, on the VSI-Bench.
Does Your 3D Encoder Really Work? When Pretrain-SFT from 2D VLMs Meets 3D VLMs
Jun 06, 2025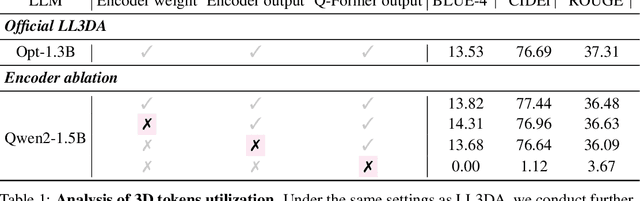
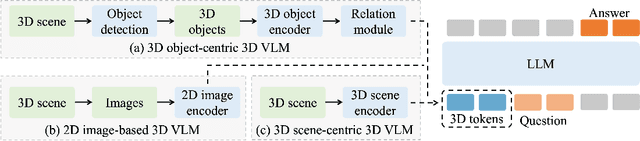

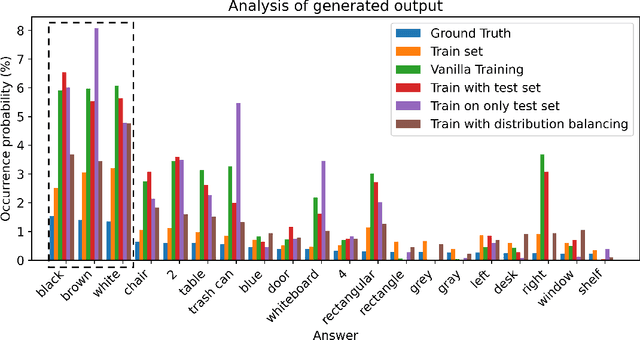
Remarkable progress in 2D Vision-Language Models (VLMs) has spurred interest in extending them to 3D settings for tasks like 3D Question Answering, Dense Captioning, and Visual Grounding. Unlike 2D VLMs that typically process images through an image encoder, 3D scenes, with their intricate spatial structures, allow for diverse model architectures. Based on their encoder design, this paper categorizes recent 3D VLMs into 3D object-centric, 2D image-based, and 3D scene-centric approaches. Despite the architectural similarity of 3D scene-centric VLMs to their 2D counterparts, they have exhibited comparatively lower performance compared with the latest 3D object-centric and 2D image-based approaches. To understand this gap, we conduct an in-depth analysis, revealing that 3D scene-centric VLMs show limited reliance on the 3D scene encoder, and the pre-train stage appears less effective than in 2D VLMs. Furthermore, we observe that data scaling benefits are less pronounced on larger datasets. Our investigation suggests that while these models possess cross-modal alignment capabilities, they tend to over-rely on linguistic cues and overfit to frequent answer distributions, thereby diminishing the effective utilization of the 3D encoder. To address these limitations and encourage genuine 3D scene understanding, we introduce a novel 3D Relevance Discrimination QA dataset designed to disrupt shortcut learning and improve 3D understanding. Our findings highlight the need for advanced evaluation and improved strategies for better 3D understanding in 3D VLMs.
Taming Video Diffusion Prior with Scene-Grounding Guidance for 3D Gaussian Splatting from Sparse Inputs
Mar 07, 2025



Despite recent successes in novel view synthesis using 3D Gaussian Splatting (3DGS), modeling scenes with sparse inputs remains a challenge. In this work, we address two critical yet overlooked issues in real-world sparse-input modeling: extrapolation and occlusion. To tackle these issues, we propose to use a reconstruction by generation pipeline that leverages learned priors from video diffusion models to provide plausible interpretations for regions outside the field of view or occluded. However, the generated sequences exhibit inconsistencies that do not fully benefit subsequent 3DGS modeling. To address the challenge of inconsistencies, we introduce a novel scene-grounding guidance based on rendered sequences from an optimized 3DGS, which tames the diffusion model to generate consistent sequences. This guidance is training-free and does not require any fine-tuning of the diffusion model. To facilitate holistic scene modeling, we also propose a trajectory initialization method. It effectively identifies regions that are outside the field of view and occluded. We further design a scheme tailored for 3DGS optimization with generated sequences. Experiments demonstrate that our method significantly improves upon the baseline and achieves state-of-the-art performance on challenging benchmarks.
When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models
May 16, 2024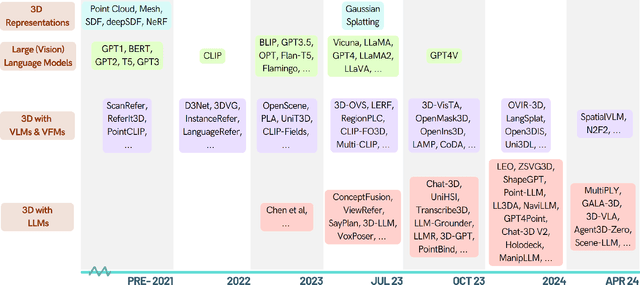
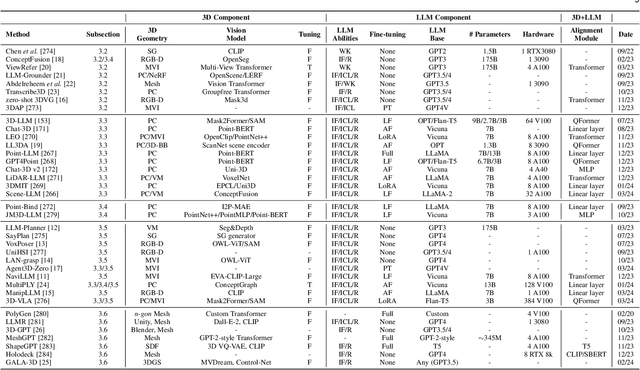
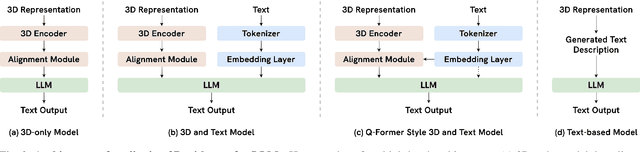
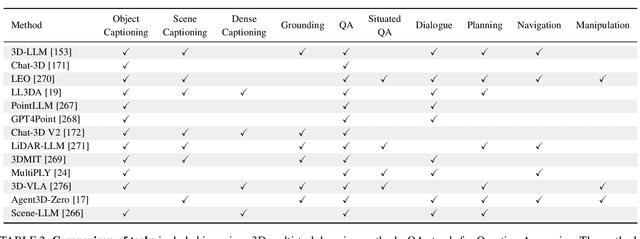
As large language models (LLMs) evolve, their integration with 3D spatial data (3D-LLMs) has seen rapid progress, offering unprecedented capabilities for understanding and interacting with physical spaces. This survey provides a comprehensive overview of the methodologies enabling LLMs to process, understand, and generate 3D data. Highlighting the unique advantages of LLMs, such as in-context learning, step-by-step reasoning, open-vocabulary capabilities, and extensive world knowledge, we underscore their potential to significantly advance spatial comprehension and interaction within embodied Artificial Intelligence (AI) systems. Our investigation spans various 3D data representations, from point clouds to Neural Radiance Fields (NeRFs). It examines their integration with LLMs for tasks such as 3D scene understanding, captioning, question-answering, and dialogue, as well as LLM-based agents for spatial reasoning, planning, and navigation. The paper also includes a brief review of other methods that integrate 3D and language. The meta-analysis presented in this paper reveals significant progress yet underscores the necessity for novel approaches to harness the full potential of 3D-LLMs. Hence, with this paper, we aim to chart a course for future research that explores and expands the capabilities of 3D-LLMs in understanding and interacting with the complex 3D world. To support this survey, we have established a project page where papers related to our topic are organized and listed: https://github.com/ActiveVisionLab/Awesome-LLM-3D.
EchoScene: Indoor Scene Generation via Information Echo over Scene Graph Diffusion
May 02, 2024We present EchoScene, an interactive and controllable generative model that generates 3D indoor scenes on scene graphs. EchoScene leverages a dual-branch diffusion model that dynamically adapts to scene graphs. Existing methods struggle to handle scene graphs due to varying numbers of nodes, multiple edge combinations, and manipulator-induced node-edge operations. EchoScene overcomes this by associating each node with a denoising process and enables collaborative information exchange, enhancing controllable and consistent generation aware of global constraints. This is achieved through an information echo scheme in both shape and layout branches. At every denoising step, all processes share their denoising data with an information exchange unit that combines these updates using graph convolution. The scheme ensures that the denoising processes are influenced by a holistic understanding of the scene graph, facilitating the generation of globally coherent scenes. The resulting scenes can be manipulated during inference by editing the input scene graph and sampling the noise in the diffusion model. Extensive experiments validate our approach, which maintains scene controllability and surpasses previous methods in generation fidelity. Moreover, the generated scenes are of high quality and thus directly compatible with off-the-shelf texture generation. Code and trained models are open-sourced.