 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM 2: Segment Anything in Images and Videos
Aug 01, 2024



We present Segment Anything Model 2 (SAM 2), a foundation model towards solving promptable visual segmentation in images and videos. We build a data engine, which improves model and data via user interaction, to collect the largest video segmentation dataset to date. Our model is a simple transformer architecture with streaming memory for real-time video processing. SAM 2 trained on our data provides strong performance across a wide range of tasks. In video segmentation, we observe better accuracy, using 3x fewer interactions than prior approaches. In image segmentation, our model is more accurate and 6x faster than the Segment Anything Model (SAM). We believe that our data, model, and insights will serve as a significant milestone for video segmentation and related perception tasks. We are releasing a version of our model, the dataset and an interactive demo.
ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
Jan 02, 2023

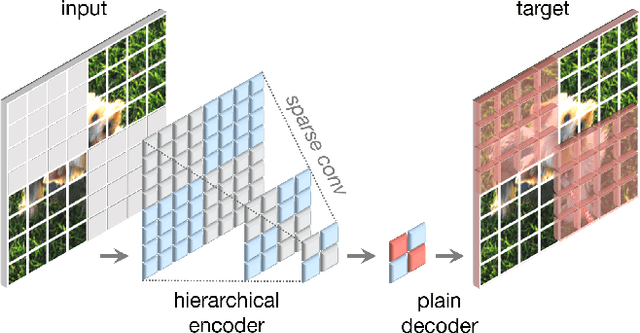

Driven by improved architectures and better representation learning frameworks, the field of visual recognition has enjoyed rapid modernization and performance boost in the early 2020s. For example, modern ConvNets, represented by ConvNeXt, have demonstrated strong performance in various scenarios. While these models were originally designed for supervised learning with ImageNet labels, they can also potentially benefit from self-supervised learning techniques such as masked autoencoders (MAE). However, we found that simply combining these two approaches leads to subpar performance. In this paper, we propose a fully convolutional masked autoencoder framework and a new Global Response Normalization (GRN) layer that can be added to the ConvNeXt architecture to enhance inter-channel feature competition. This co-design of self-supervised learning techniques and architectural improvement results in a new model family called ConvNeXt V2, which significantly improves the performance of pure ConvNets on various recognition benchmarks, including ImageNet classification, COCO detection, and ADE20K segmentation. We also provide pre-trained ConvNeXt V2 models of various sizes, ranging from an efficient 3.7M-parameter Atto model with 76.7% top-1 accuracy on ImageNet, to a 650M Huge model that achieves a state-of-the-art 88.9% accuracy using only public training data.
Scaling Language-Image Pre-training via Masking
Dec 01, 2022



We present Fast Language-Image Pre-training (FLIP), a simple and more efficient method for training CLIP. Our method randomly masks out and removes a large portion of image patches during training. Masking allows us to learn from more image-text pairs given the same wall-clock time and contrast more samples per iteration with similar memory footprint. It leads to a favorable trade-off between accuracy and training time. In our experiments on 400 million image-text pairs, FLIP improves both accuracy and speed over the no-masking baseline. On a large diversity of downstream tasks, FLIP dominantly outperforms the CLIP counterparts trained on the same data. Facilitated by the speedup, we explore the scaling behavior of increasing the model size, data size, or training length, and report encouraging results and comparisons. We hope that our work will foster future research on scaling vision-language learning.
UniT3D: A Unified Transformer for 3D Dense Captioning and Visual Grounding
Dec 01, 2022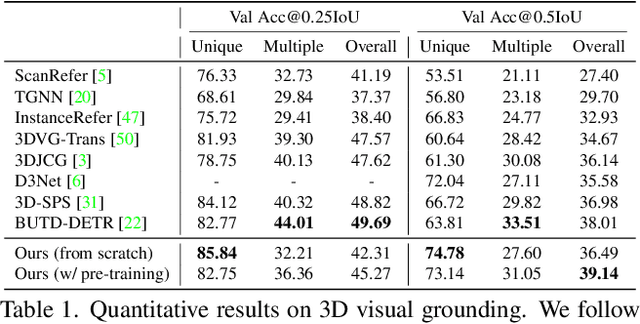
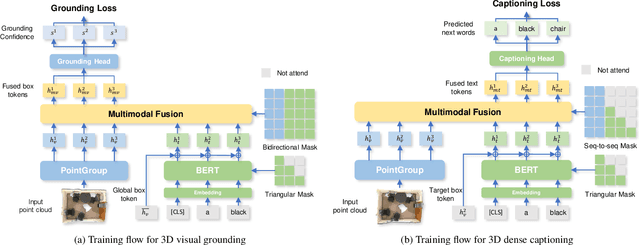

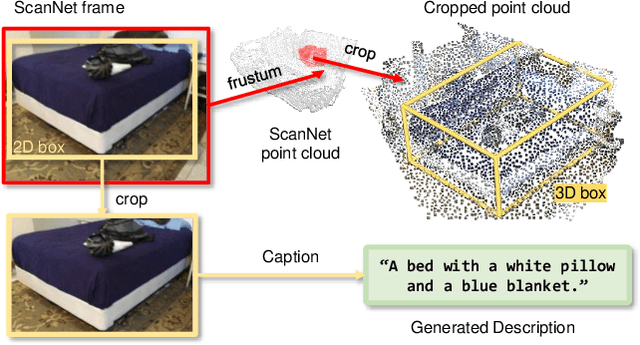
Performing 3D dense captioning and visual grounding requires a common and shared understanding of the underlying multimodal relationships. However, despite some previous attempts on connecting these two related tasks with highly task-specific neural modules, it remains understudied how to explicitly depict their shared nature to learn them simultaneously. In this work, we propose UniT3D, a simple yet effective fully unified transformer-based architecture for jointly solving 3D visual grounding and dense captioning. UniT3D enables learning a strong multimodal representation across the two tasks through a supervised joint pre-training scheme with bidirectional and seq-to-seq objectives. With a generic architecture design, UniT3D allows expanding the pre-training scope to more various training sources such as the synthesized data from 2D prior knowledge to benefit 3D vision-language tasks. Extensive experiments and analysis demonstrate that UniT3D obtains significant gains for 3D dense captioning and visual grounding.
Exploring Long-Sequence Masked Autoencoders
Oct 13, 2022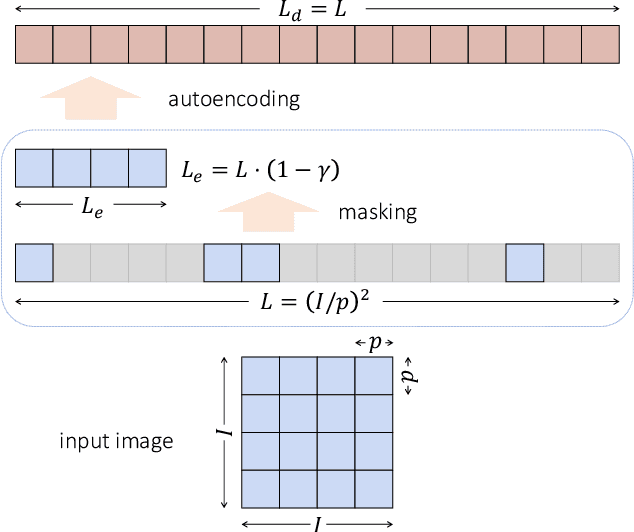

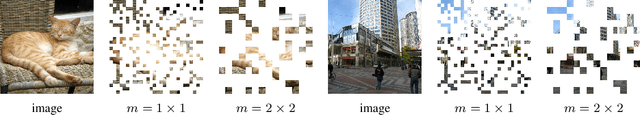

Masked Autoencoding (MAE) has emerged as an effective approach for pre-training representations across multiple domains. In contrast to discrete tokens in natural languages, the input for image MAE is continuous and subject to additional specifications. We systematically study each input specification during the pre-training stage, and find sequence length is a key axis that further scales MAE. Our study leads to a long-sequence version of MAE with minimal changes to the original recipe, by just decoupling the mask size from the patch size. For object detection and semantic segmentation, our long-sequence MAE shows consistent gains across all the experimental setups without extra computation cost during the transfer. While long-sequence pre-training is discerned most beneficial for detection and segmentation, we also achieve strong results on ImageNet-1K classification by keeping a standard image size and only increasing the sequence length. We hope our findings can provide new insights and avenues for scaling in computer vision.
FLAVA: A Foundational Language And Vision Alignment Model
Dec 08, 2021



State-of-the-art vision and vision-and-language models rely on large-scale visio-linguistic pretraining for obtaining good performance on a variety of downstream tasks. Generally, such models are often either cross-modal (contrastive) or multi-modal (with earlier fusion) but not both; and they often only target specific modalities or tasks. A promising direction would be to use a single holistic universal model, as a "foundation", that targets all modalities at once -- a true vision and language foundation model should be good at vision tasks, language tasks, and cross- and multi-modal vision and language tasks. We introduce FLAVA as such a model and demonstrate impressive performance on a wide range of 35 tasks spanning these target modalities.
Transformer is All You Need: Multimodal Multitask Learning with a Unified Transformer
Feb 22, 2021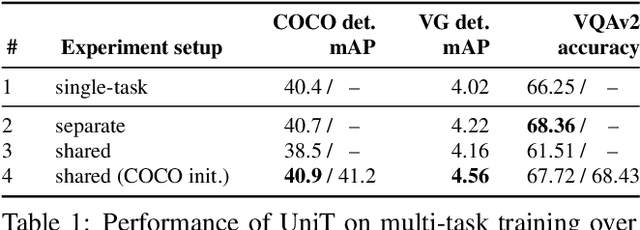
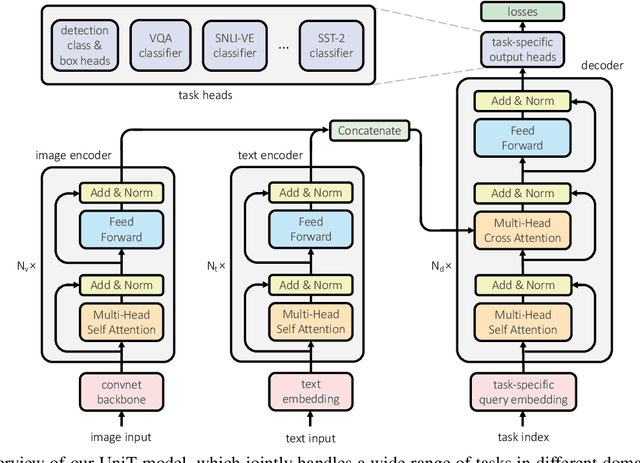

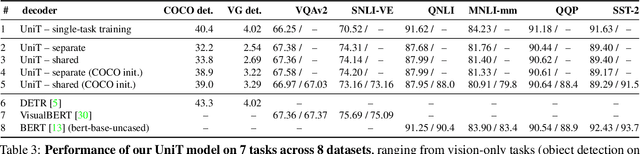
We propose UniT, a Unified Transformer model to simultaneously learn the most prominent tasks across different domains, ranging from object detection to language understanding and multimodal reasoning. Based on the transformer encoder-decoder architecture, our UniT model encodes each input modality with an encoder and makes predictions on each task with a shared decoder over the encoded input representations, followed by task-specific output heads. The entire model is jointly trained end-to-end with losses from each task. Compared to previous efforts on multi-task learning with transformers, we share the same model parameters to all tasks instead of separately fine-tuning task-specific models and handle a much higher variety of tasks across different domains. In our experiments, we learn 7 tasks jointly over 8 datasets, achieving comparable performance to well-established prior work on each domain under the same supervision with a compact set of model parameters. Code will be released in MMF at https://mmf.sh.
Worldsheet: Wrapping the World in a 3D Sheet for View Synthesis from a Single Image
Dec 17, 2020



We present Worldsheet, a method for novel view synthesis using just a single RGB image as input. This is a challenging problem as it requires an understanding of the 3D geometry of the scene as well as texture mapping to generate both visible and occluded regions from new view-points. Our main insight is that simply shrink-wrapping a planar mesh sheet onto the input image, consistent with the learned intermediate depth, captures underlying geometry sufficient enough to generate photorealistic unseen views with arbitrarily large view-point changes. To operationalize this, we propose a novel differentiable texture sampler that allows our wrapped mesh sheet to be textured; which is then transformed into a target image via differentiable rendering. Our approach is category-agnostic, end-to-end trainable without using any 3D supervision and requires a single image at test time. Worldsheet consistently outperforms prior state-of-the-art methods on single-image view synthesis across several datasets. Furthermore, this simple idea captures novel views surprisingly well on a wide range of high resolution in-the-wild images in converting them into a navigable 3D pop-up. Video results and code at https://worldsheet.github.io
TextCaps: a Dataset for Image Captioning with Reading Comprehension
Mar 24, 2020
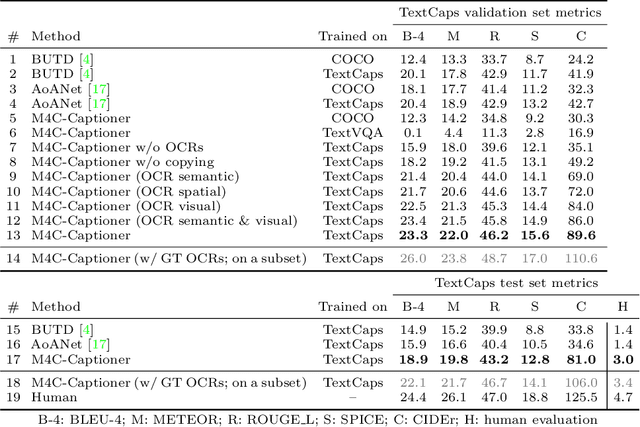

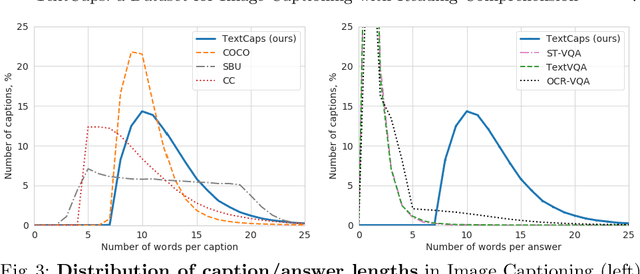
Image descriptions can help visually impaired people to quickly understand the image content. While we made significant progress in automatically describing images and optical character recognition, current approaches are unable to include written text in their descriptions, although text is omnipresent in human environments and frequently critical to understand our surroundings. To study how to comprehend text in the context of an image we collect a novel dataset, TextCaps, with 145k captions for 28k images. Our dataset challenges a model to recognize text, relate it to its visual context, and decide what part of the text to copy or paraphrase, requiring spatial, semantic, and visual reasoning between multiple text tokens and visual entities, such as objects. We study baselines and adapt existing approaches to this new task, which we refer to as image captioning with reading comprehension. Our analysis with automatic and human studies shows that our new TextCaps dataset provides many new technical challenges over previous datasets.
Iterative Answer Prediction with Pointer-Augmented Multimodal Transformers for TextVQA
Dec 05, 2019
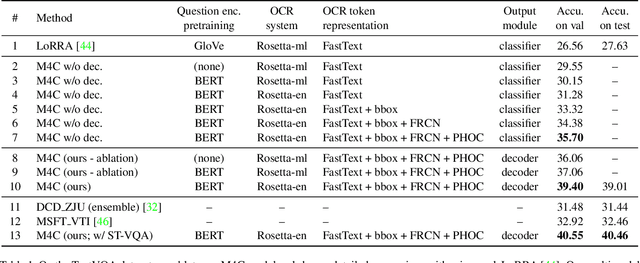
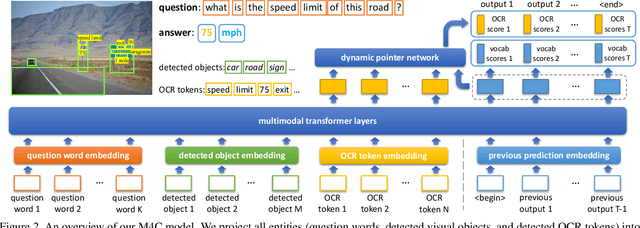
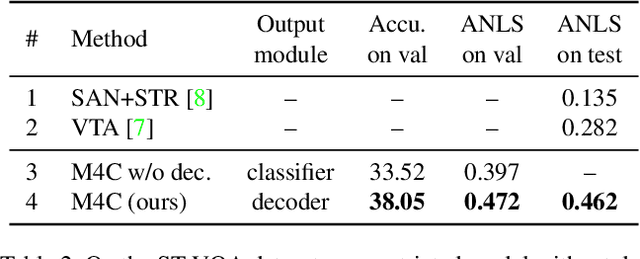
Many visual scenes contain text that carries crucial information, and it is thus essential to understand text in images for downstream reasoning tasks. For example, a deep water label on a warning sign warns people about the danger in the scene. Recent work has explored the TextVQA task that requires reading and understanding text in images to answer a question. However, existing approaches for TextVQA are mostly based on custom pairwise fusion mechanisms between a pair of two modalities and are restricted to a single prediction step by casting TextVQA as a classification task. In this work, we propose a novel model for the TextVQA task based on a multimodal transformer architecture accompanied by a rich representation for text in images. Our model naturally fuses different modalities homogeneously by embedding them into a common semantic space where self-attention is applied to model inter- and intra- modality context. Furthermore, it enables iterative answer decoding with a dynamic pointer network, allowing the model to form an answer through multi-step prediction instead of one-step classification. Our model outperforms existing approaches on three benchmark datasets for the TextVQA task by a large margin.