 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextCaps: a Dataset for Image Captioning with Reading Comprehension
Mar 24, 2020
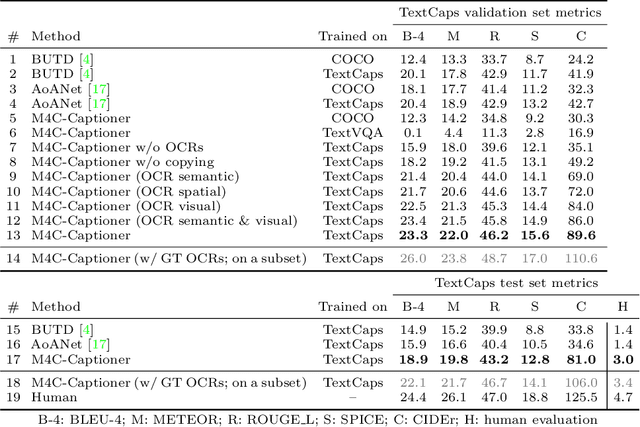

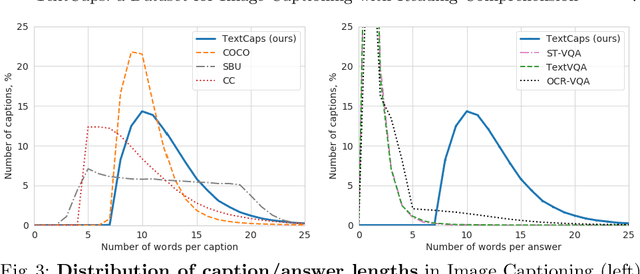
Image descriptions can help visually impaired people to quickly understand the image content. While we made significant progress in automatically describing images and optical character recognition, current approaches are unable to include written text in their descriptions, although text is omnipresent in human environments and frequently critical to understand our surroundings. To study how to comprehend text in the context of an image we collect a novel dataset, TextCaps, with 145k captions for 28k images. Our dataset challenges a model to recognize text, relate it to its visual context, and decide what part of the text to copy or paraphrase, requiring spatial, semantic, and visual reasoning between multiple text tokens and visual entities, such as objects. We study baselines and adapt existing approaches to this new task, which we refer to as image captioning with reading comprehension. Our analysis with automatic and human studies shows that our new TextCaps dataset provides many new technical challenges over previous datasets.
"The cracks that wanted to be a graph": application of image processing and Graph Neural Networks to the description of craquelure patterns
May 13, 2019
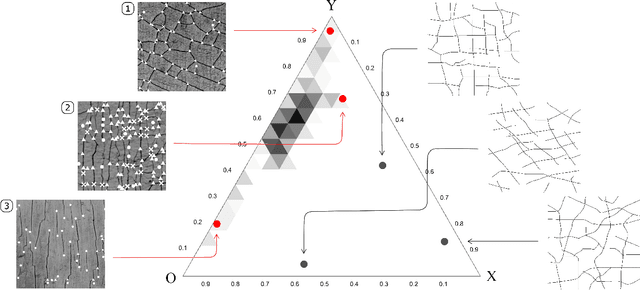

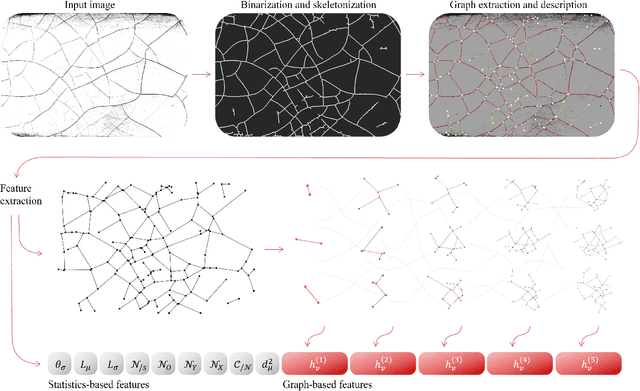
Cracks on a painting is not a defect but an inimitable signature of an artwork which can be used for origin examination, aging monitoring, damage identification, and even forgery detection. This work presents the development of a new methodology and corresponding toolbox for the extraction and characterization of information from an image of a craquelure pattern. The proposed approach processes craquelure network as a graph. The graph representation captures the network structure via mutual organization of junctions and fractures. Furthermore, it is invariant to any geometrical distortions. At the same time, our tool extracts the properties of each node and edge individually, which allows to characterize the pattern statistically. We illustrate benefits from the graph representation and statistical features individually using novel Graph Neural Network and hand-crafted descriptors correspondingly. However, we also show that the best performance is achieved when both techniques are merged into one framework. We perform experiments on the dataset for paintings' origin classification and demonstrate that our approach outperforms existing techniques by a large margin.
Generative Smoke Removal
Feb 01, 2019
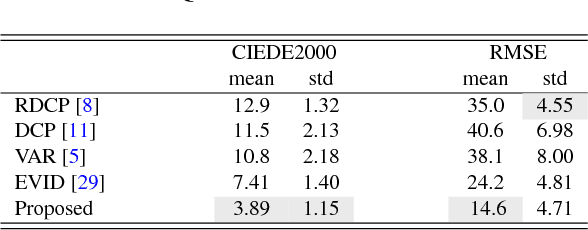
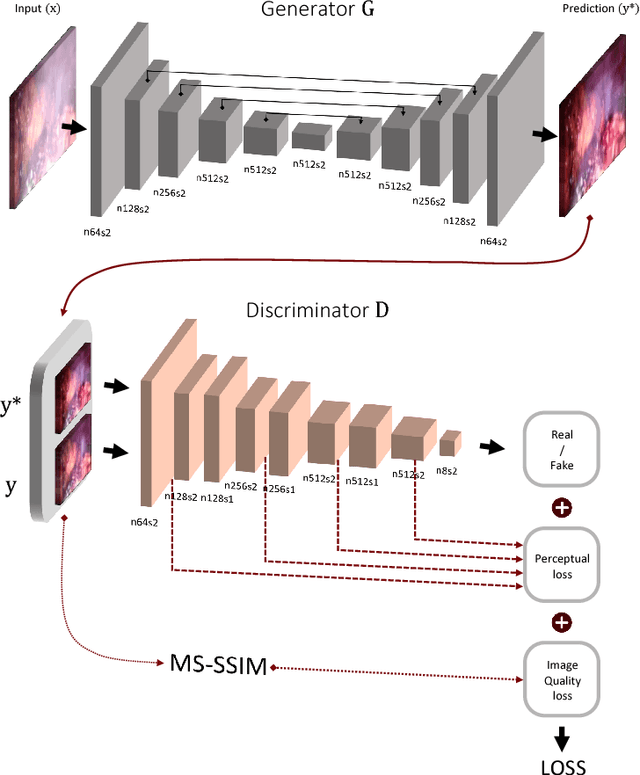
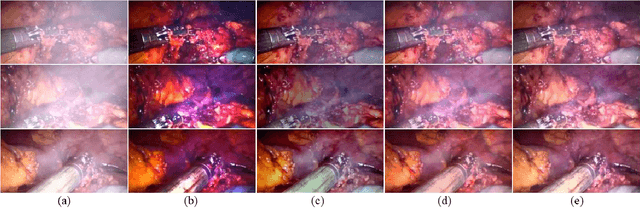
In minimally invasive surgery, the use of tissue dissection tools causes smoke, which inevitably degrades the image quality. This could reduce the visibility of the operation field for surgeons and introduces errors for the computer vision algorithms used in surgical navigation systems. In this paper, we propose a novel approach for computational smoke removal using supervised image-to-image translation. We demonstrate that straightforward application of existing generative algorithms allows removing smoke but decreases image quality and introduces synthetic noise (grid-structure). Thus, we propose to solve this issue by modification of GAN's architecture and adding perceptual image quality metric to the loss function. Obtained results demonstrate that proposed method efficiently removes smoke as well as preserves perceptually sufficient image quality.
Deep Hyperspectral Prior: Denoising, Inpainting, Super-Resolution
Feb 01, 2019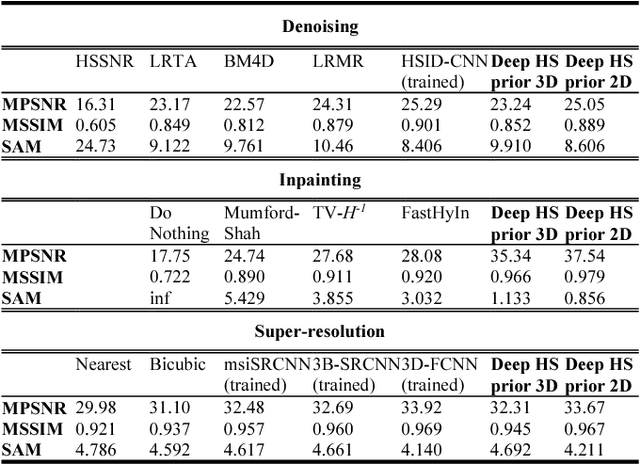
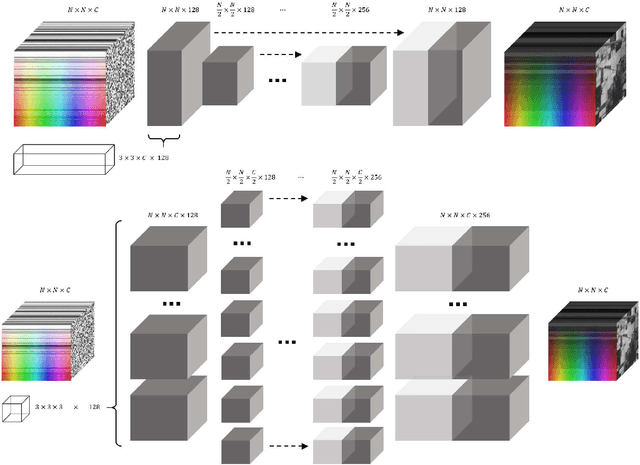


Deep learning algorithms have demonstrated state-of-the-art performance in various tasks of image restoration. This was made possible through the ability of CNNs to learn from large exemplar sets. However, the latter becomes an issue for hyperspectral image processing where datasets commonly consist of just a few images. In this work, we propose a new approach to denoising, inpainting, and super-resolution of hyperspectral image data using intrinsic properties of a CNN without any training. The performance of the given algorithm is shown to be comparable to the performance of trained networks, while its application is not restricted by the availability of training data. This work is an extension of original "deep prior" algorithm to HSI domain and 3D-convolutional networks.
Artificial Color Constancy via GoogLeNet with Angular Loss Function
Nov 20, 2018
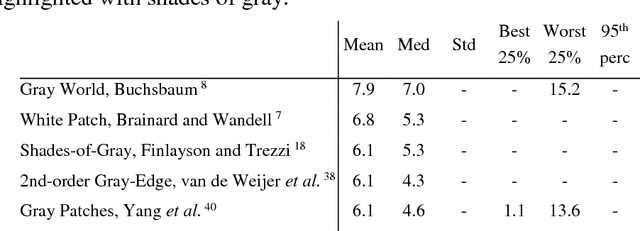
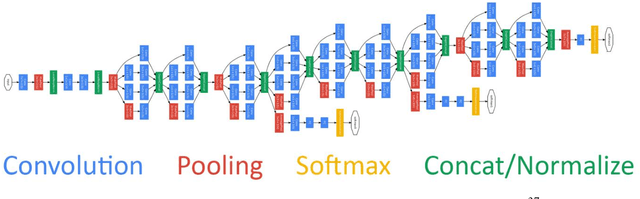
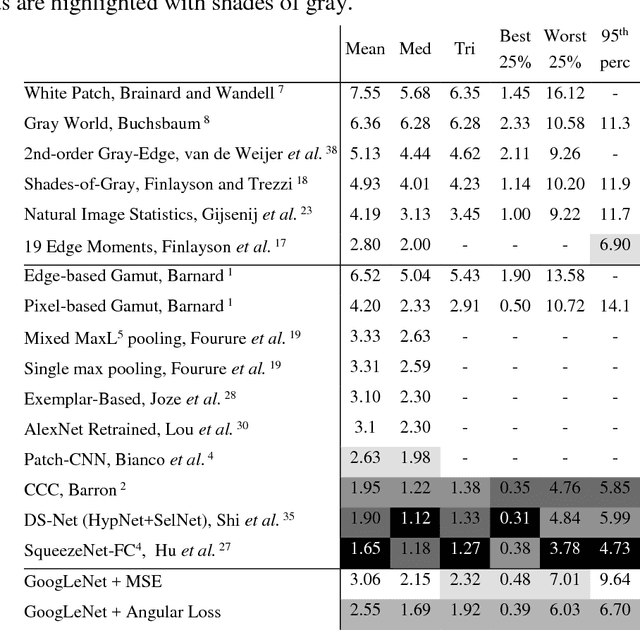
Color Constancy is the ability of the human visual system to perceive colors unchanged independently of the illumination. Giving a machine this feature will be beneficial in many fields where chromatic information is used. Particularly, it significantly improves scene understanding and object recognition. In this paper, we propose transfer learning-based algorithm, which has two main features: accuracy higher than many state-of-the-art algorithms and simplicity of implementation. Despite the fact that GoogLeNet was used in the experiments, given approach may be applied to any CNN. Additionally, we discuss design of a new loss function oriented specifically to this problem, and propose a few the most suitable options.
Changing the Image Memorability: From Basic Photo Editing to GANs
Nov 15, 2018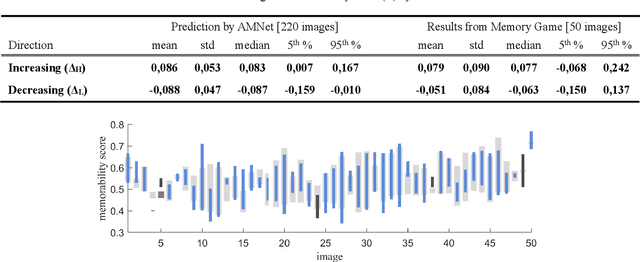

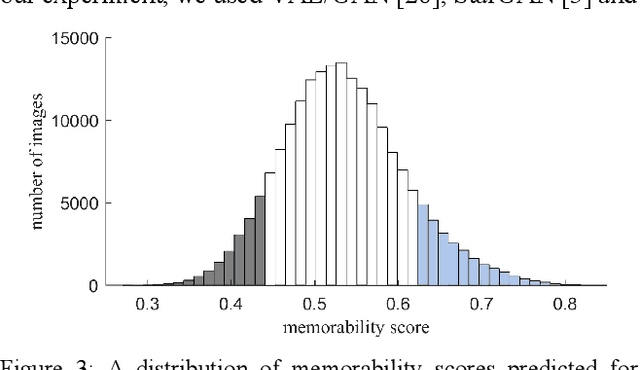
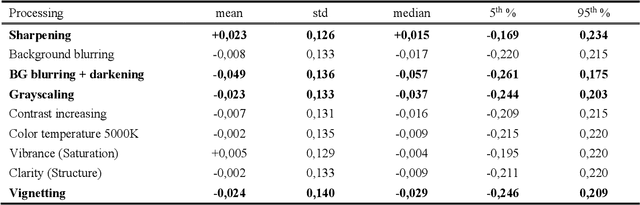
Memorability is considered to be an important characteristic of visual content, whereas for advertisement and educational purposes it is the most important one. Despite numerous studies on understanding and predicting image memorability, there are almost no achievements in memorability modification. In this work, we study two possible approaches to image modification which likely may influence memorability. The visual features which influence memorability directly stay unknown till now, hence it is impossible to control it manually. As a solution, we let GAN learn it deeply using labeled data, and then use it for conditional generation of new images. By analogy with algorithms which edit facial attributes, we consider memorability as yet another attribute and operate with it in the same way. Obtained data is also interesting for analysis, simply because there are no real-world examples of successful change of image memorability while preserving its other attributes. We believe this may give many new answers to the question "what makes an image memorable?" Apart from that we also study the influence of conventional photo-editing tools (Photoshop, Instagram, etc.) used daily by a wide audience on memorability. In this case, we start from real practical methods and study it using statistics and recent advances in memorability prediction. Photographers, designers, and advertisers will benefit from the results of this study directly.
Conditional GANs for Multi-Illuminant Color Constancy: Revolution or Yet Another Approach?
Nov 15, 2018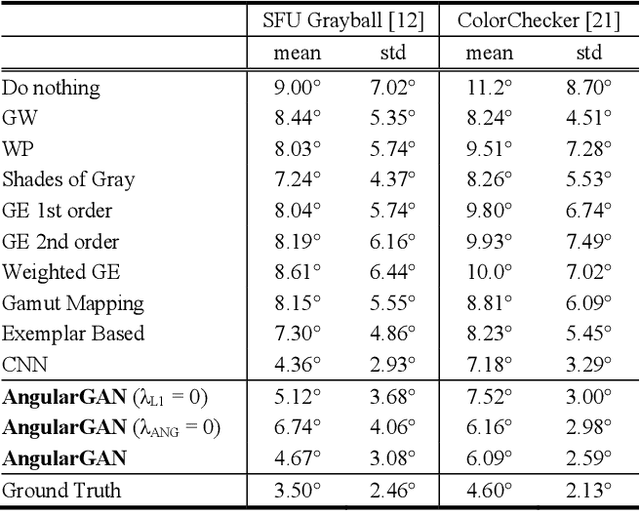
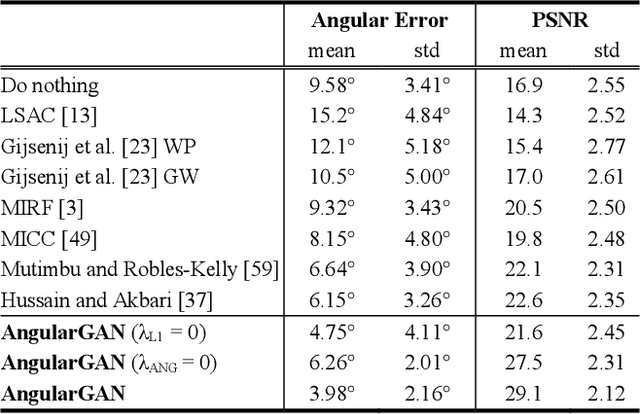
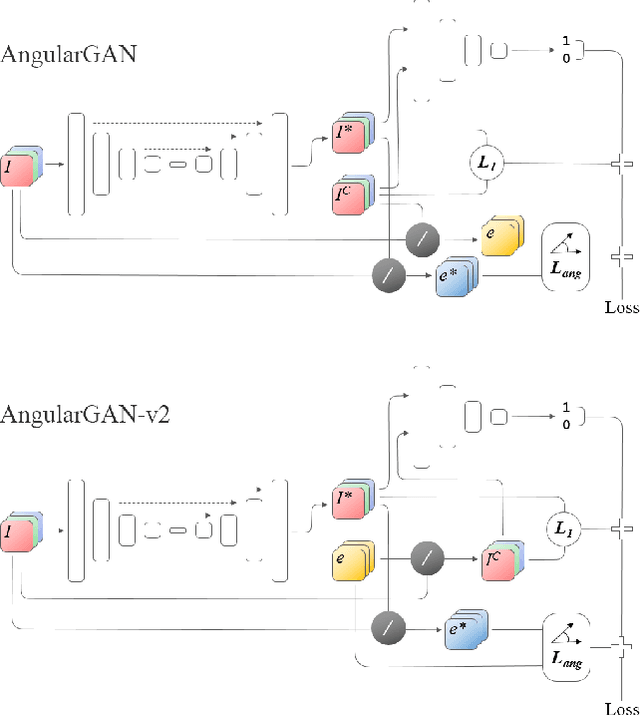

Non-uniform and multi-illuminant color constancy are important tasks, the solution of which will allow to discard information about lighting conditions in the image. Non-uniform illumination and shadows distort colors of real-world objects and mostly do not contain valuable information. Thus, many computer vision and image processing techniques would benefit from automatic discarding of this information at the pre-processing step. In this work we propose novel view on this classical problem via generative end-to-end algorithm, namely image conditioned Generative Adversarial Network. We also demonstrate the potential of the given approach for joint shadow detection and removal. Forced by the lack of training data, we render the largest existing shadow removal dataset and make it publicly available. It consists of approximately 6,000 pairs of wide field of view synthetic images with and without shadows.