 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-PerceptCT: Deep Perceptual Enhancement for Low-Dose CT Images
Nov 18, 2025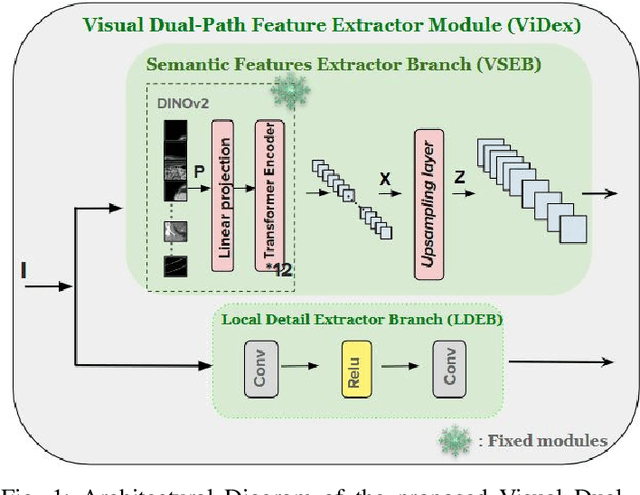
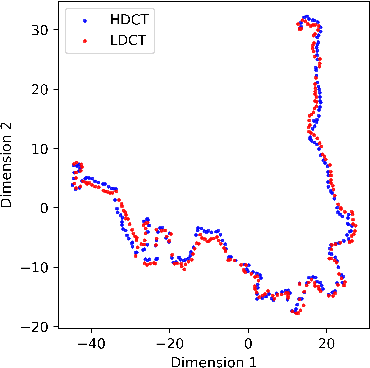
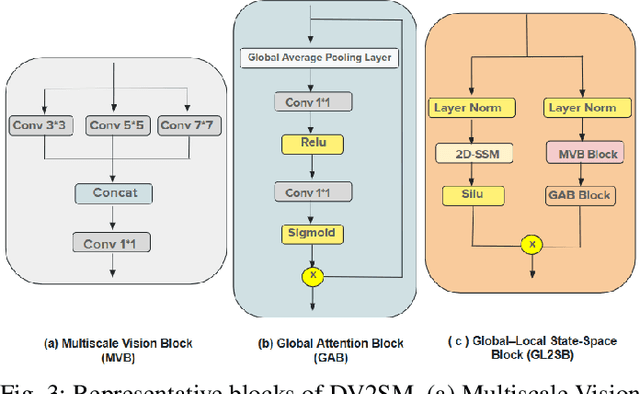
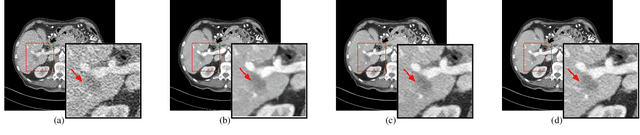
Low Dose Computed Tomography (LDCT) is widely used as an imaging solution to aid diagnosis and other clinical tasks. However, this comes at the price of a deterioration in image quality due to the low dose of radiation used to reduce the risk of secondary cancer development. While some efficient methods have been proposed to enhance LDCT quality, many overestimate noise and perform excessive smoothing, leading to a loss of critical details. In this paper, we introduce D-PerceptCT, a novel architecture inspired by key principles of the Human Visual System (HVS) to enhance LDCT images. The objective is to guide the model to enhance or preserve perceptually relevant features, thereby providing radiologists with CT images where critical anatomical structures and fine pathological details are perceptu- ally visible. D-PerceptCT consists of two main blocks: 1) a Visual Dual-path Extractor (ViDex), which integrates semantic priors from a pretrained DINOv2 model with local spatial features, allowing the network to incorporate semantic-awareness during enhancement; (2) a Global-Local State-Space block that captures long-range information and multiscale features to preserve the important structures and fine details for diagnosis. In addition, we propose a novel deep perceptual loss, designated as the Deep Perceptual Relevancy Loss Function (DPRLF), which is inspired by human contrast sensitivity, to further emphasize perceptually important features. Extensive experiments on the Mayo2016 dataset demonstrate the effectiveness of D-PerceptCT method for LDCT enhancement, showing better preservation of structural and textural information within LDCT images compared to SOTA methods.
A New Lightweight Hybrid Graph Convolutional Neural Network -- CNN Scheme for Scene Classification using Object Detection Inference
Jul 19, 2024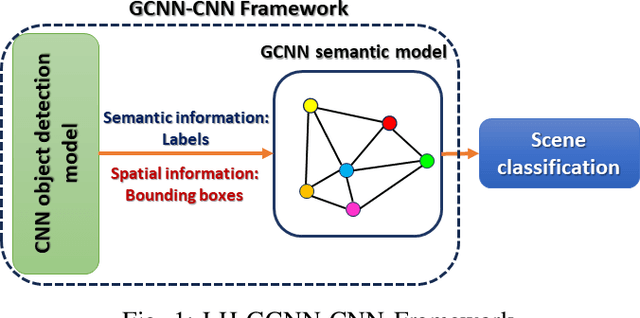
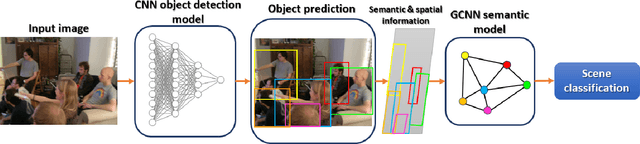
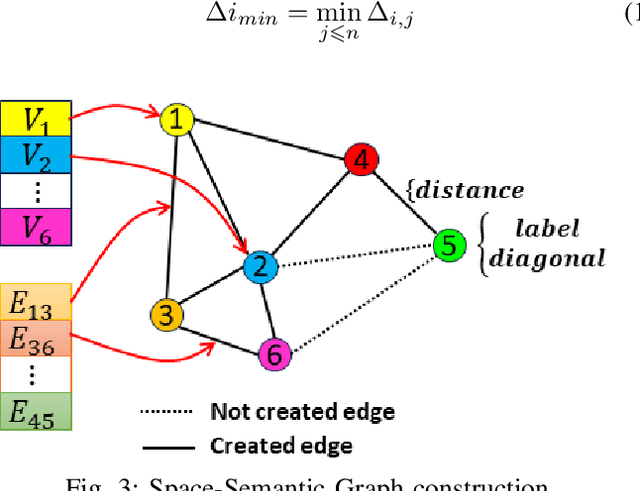
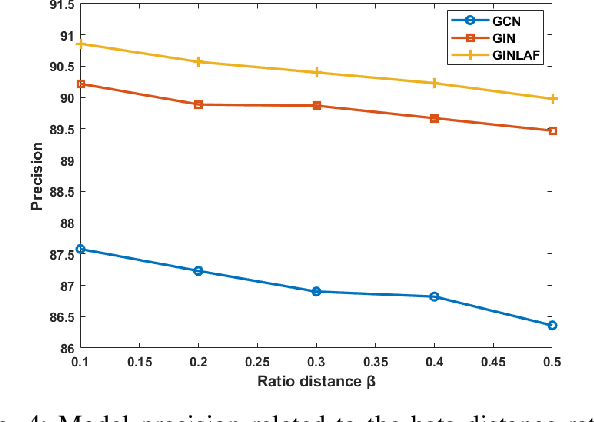
Scene understanding plays an important role in several high-level computer vision applications, such as autonomous vehicles, intelligent video surveillance, or robotics. However, too few solutions have been proposed for indoor/outdoor scene classification to ensure scene context adaptability for computer vision frameworks. We propose the first Lightweight Hybrid Graph Convolutional Neural Network (LH-GCNN)-CNN framework as an add-on to object detection models. The proposed approach uses the output of the CNN object detection model to predict the observed scene type by generating a coherent GCNN representing the semantic and geometric content of the observed scene. This new method, applied to natural scenes, achieves an efficiency of over 90\% for scene classification in a COCO-derived dataset containing a large number of different scenes, while requiring fewer parameters than traditional CNN methods. For the benefit of the scientific community, we will make the source code publicly available: https://github.com/Aymanbegh/Hybrid-GCNN-CNN.
Deep Learning for Multi-Label Learning: A Comprehensive Survey
Jan 29, 2024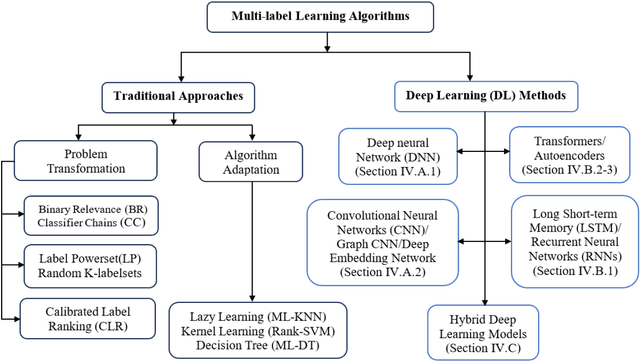
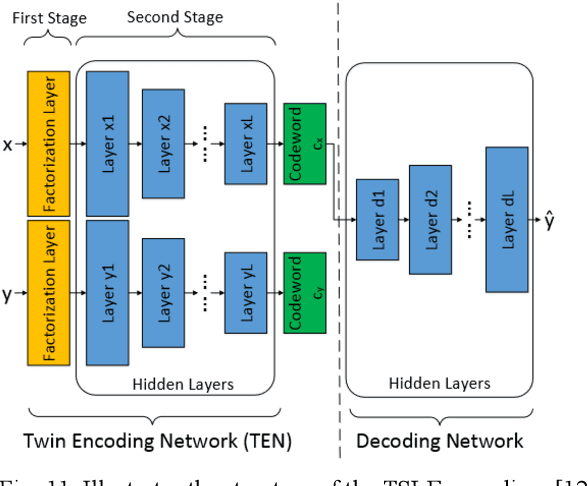
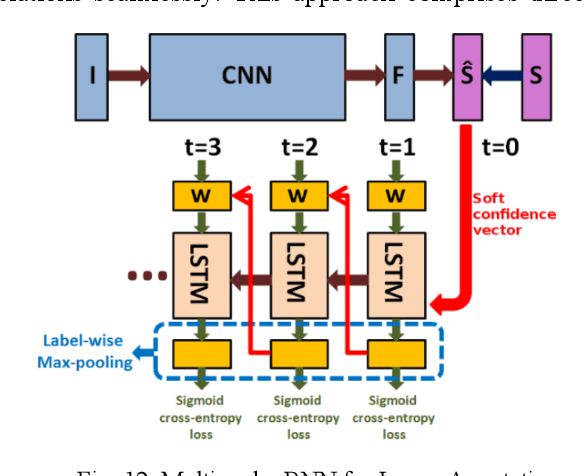
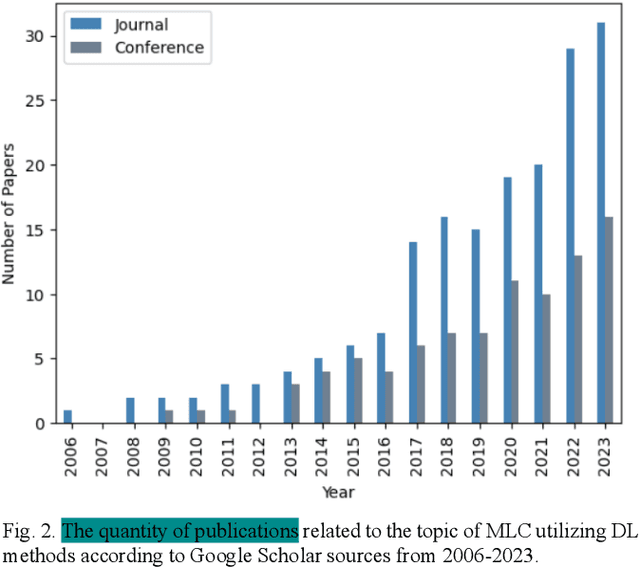
Multi-label learning is a rapidly growing research area that aims to predict multiple labels from a single input data point. In the era of big data, tasks involving multi-label classification (MLC) or ranking present significant and intricate challenges, capturing considerable attention in diverse domains. Inherent difficulties in MLC include dealing with high-dimensional data, addressing label correlations, and handling partial labels, for which conventional methods prove ineffective. Recent years have witnessed a notable increase in adopting deep learning (DL) techniques to address these challenges more effectively in MLC. Notably, there is a burgeoning effort to harness the robust learning capabilities of DL for improved modelling of label dependencies and other challenges in MLC. However, it is noteworthy that comprehensive studies specifically dedicated to DL for multi-label learning are limited. Thus, this survey aims to thoroughly review recent progress in DL for multi-label learning, along with a summary of open research problems in MLC. The review consolidates existing research efforts in DL for MLC,including deep neural networks, transformers, autoencoders, and convolutional and recurrent architectures. Finally, the study presents a comparative analysis of the existing methods to provide insightful observations and stimulate future research directions in this domain.
CD-COCO: A Versatile Complex Distorted COCO Database for Scene-Context-Aware Computer Vision
Nov 12, 2023

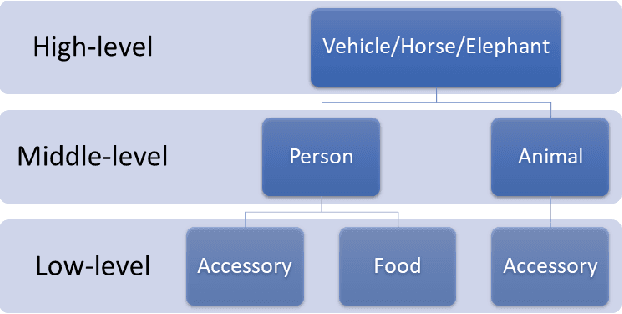
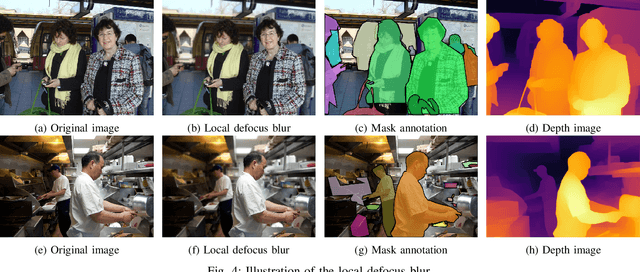
The recent development of deep learning methods applied to vision has enabled their increasing integration into real-world applications to perform complex Computer Vision (CV) tasks. However, image acquisition conditions have a major impact on the performance of high-level image processing. A possible solution to overcome these limitations is to artificially augment the training databases or to design deep learning models that are robust to signal distortions. We opt here for the first solution by enriching the database with complex and realistic distortions which were ignored until now in the existing databases. To this end, we built a new versatile database derived from the well-known MS-COCO database to which we applied local and global photo-realistic distortions. These new local distortions are generated by considering the scene context of the images that guarantees a high level of photo-realism. Distortions are generated by exploiting the depth information of the objects in the scene as well as their semantics. This guarantees a high level of photo-realism and allows to explore real scenarios ignored in conventional databases dedicated to various CV applications. Our versatile database offers an efficient solution to improve the robustness of various CV tasks such as Object Detection (OD), scene segmentation, and distortion-type classification methods. The image database, scene classification index, and distortion generation codes are publicly available \footnote{\url{https://github.com/Aymanbegh/CD-COCO}}
End-to-End Blind Quality Assessment for Laparoscopic Videos using Neural Networks
Feb 09, 2022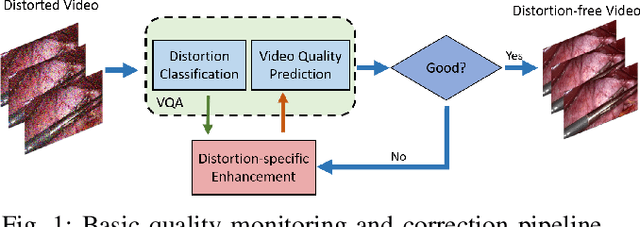
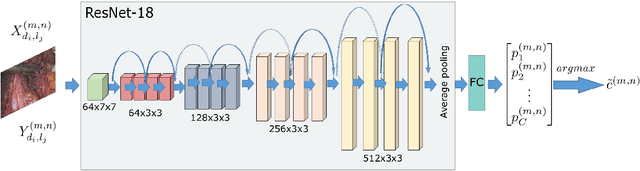
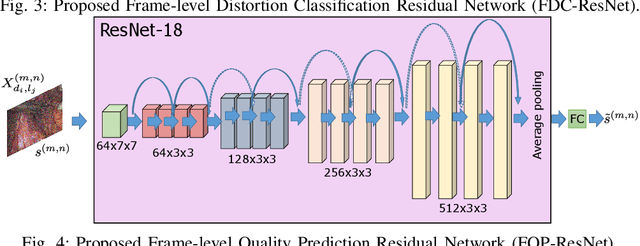
Video quality assessment is a challenging problem having a critical significance in the context of medical imaging. For instance, in laparoscopic surgery, the acquired video data suffers from different kinds of distortion that not only hinder surgery performance but also affect the execution of subsequent tasks in surgical navigation and robotic surgeries. For this reason, we propose in this paper neural network-based approaches for distortion classification as well as quality prediction. More precisely, a Residual Network (ResNet) based approach is firstly developed for simultaneous ranking and classification task. Then, this architecture is extended to make it appropriate for the quality prediction task by using an additional Fully Connected Neural Network (FCNN). To train the overall architecture (ResNet and FCNN models), transfer learning and end-to-end learning approaches are investigated. Experimental results, carried out on a new laparoscopic video quality database, have shown the efficiency of the proposed methods compared to recent conventional and deep learning based approaches.
Residual Networks based Distortion Classification and Ranking for Laparoscopic Image Quality Assessment
Jun 12, 2021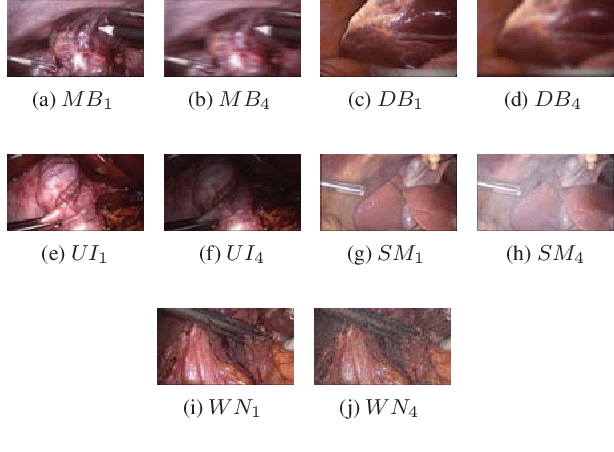


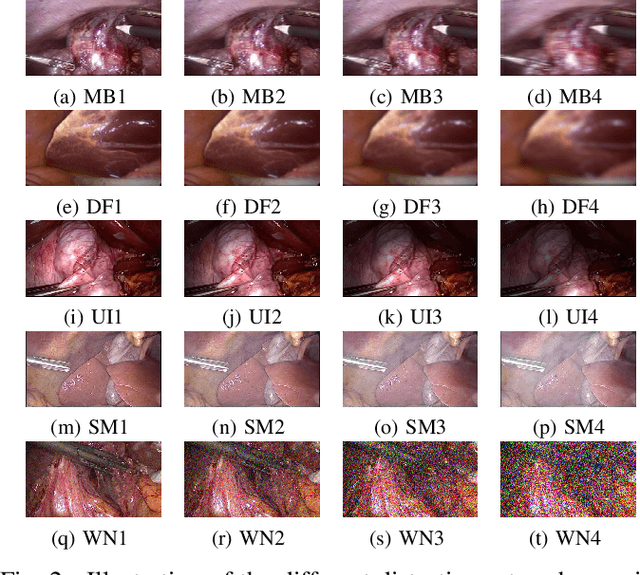
Laparoscopic images and videos are often affected by different types of distortion like noise, smoke, blur and nonuniform illumination. Automatic detection of these distortions, followed generally by application of appropriate image quality enhancement methods, is critical to avoid errors during surgery. In this context, a crucial step involves an objective assessment of the image quality, which is a two-fold problem requiring both the classification of the distortion type affecting the image and the estimation of the severity level of that distortion. Unlike existing image quality measures which focus mainly on estimating a quality score, we propose in this paper to formulate the image quality assessment task as a multi-label classification problem taking into account both the type as well as the severity level (or rank) of distortions. Here, this problem is then solved by resorting to a deep neural networks based approach. The obtained results on a laparoscopic image dataset show the efficiency of the proposed approach.
Kalman Filter Based Multiple Person Head Tracking
Jun 11, 2020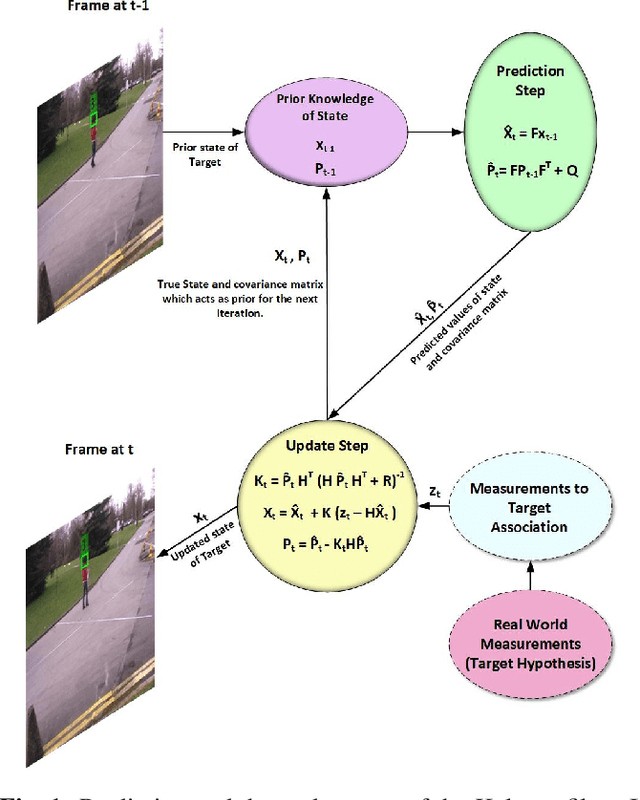

For multi-target tracking, target representation plays a crucial rule in performance. State-of-the-art approaches rely on the deep learning-based visual representation that gives an optimal performance at the cost of high computational complexity. In this paper, we come up with a simple yet effective target representation for human tracking. Our inspiration comes from the fact that the human body goes through severe deformation and inter/intra occlusion over the passage of time. So, instead of tracking the whole body part, a relative rigid organ tracking is selected for tracking the human over an extended period of time. Hence, we followed the tracking-by-detection paradigm and generated the target hypothesis of only the spatial locations of heads in every frame. After the localization of head location, a Kalman filter with a constant velocity motion model is instantiated for each target that follows the temporal evolution of the targets in the scene. For associating the targets in the consecutive frames, combinatorial optimization is used that associates the corresponding targets in a greedy fashion. Qualitative results are evaluated on four challenging video surveillance dataset and promising results has been achieved.
Adaptive Context Encoding Module for Semantic Segmentation
Jul 13, 2019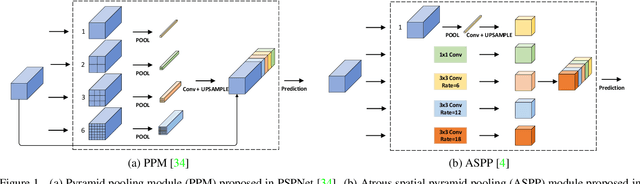
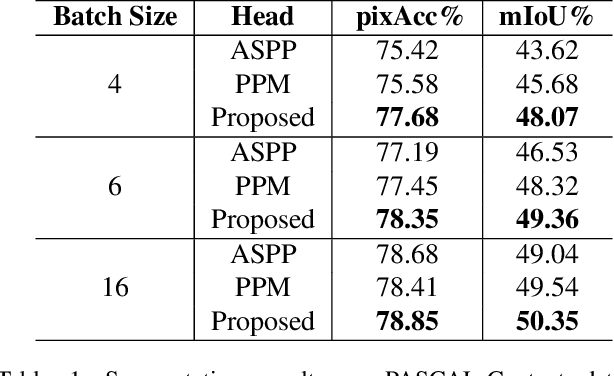
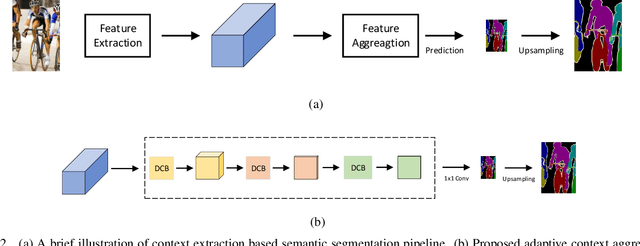

The object sizes in images are diverse, therefore, capturing multiple scale context information is essential for semantic segmentation. Existing context aggregation methods such as pyramid pooling module (PPM) and atrous spatial pyramid pooling (ASPP) design different pooling size or atrous rate, such that multiple scale information is captured. However, the pooling sizes and atrous rates are chosen manually and empirically. In order to capture object context information adaptively, in this paper, we propose an adaptive context encoding (ACE) module based on deformable convolution operation to argument multiple scale information. Our ACE module can be embedded into other Convolutional Neural Networks (CNN) easily for context aggregation. The effectiveness of the proposed module is demonstrated on Pascal-Context and ADE20K datasets. Although our proposed ACE only consists of three deformable convolution blocks, it outperforms PPM and ASPP in terms of mean Intersection of Union (mIoU) on both datasets. All the experiment study confirms that our proposed module is effective as compared to the state-of-the-art methods.
Generative Smoke Removal
Feb 01, 2019
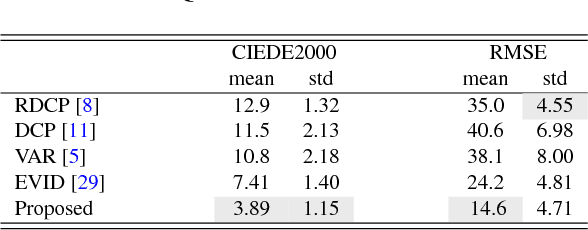
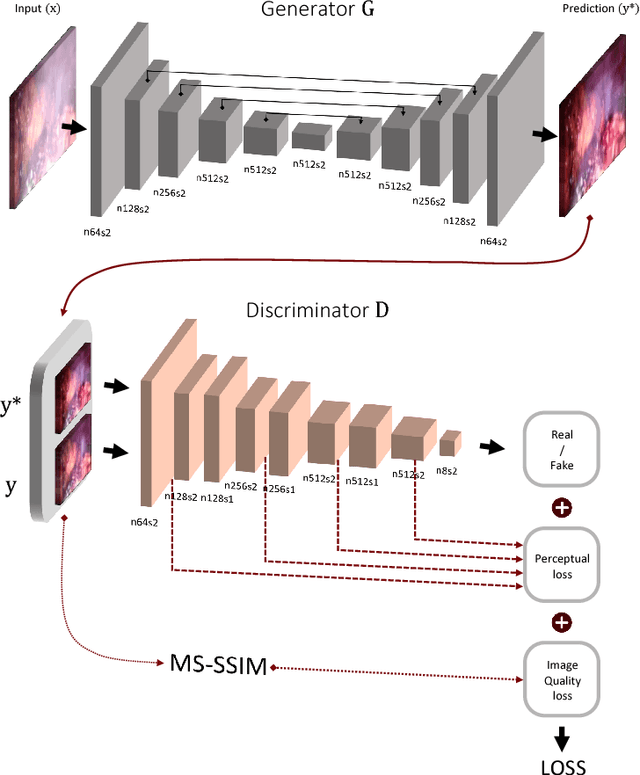
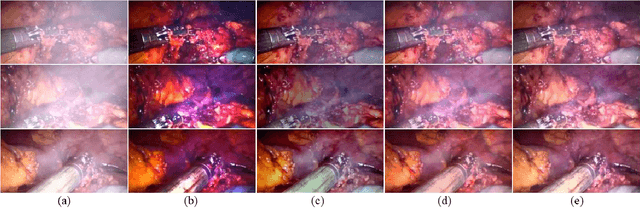
In minimally invasive surgery, the use of tissue dissection tools causes smoke, which inevitably degrades the image quality. This could reduce the visibility of the operation field for surgeons and introduces errors for the computer vision algorithms used in surgical navigation systems. In this paper, we propose a novel approach for computational smoke removal using supervised image-to-image translation. We demonstrate that straightforward application of existing generative algorithms allows removing smoke but decreases image quality and introduces synthetic noise (grid-structure). Thus, we propose to solve this issue by modification of GAN's architecture and adding perceptual image quality metric to the loss function. Obtained results demonstrate that proposed method efficiently removes smoke as well as preserves perceptually sufficient image quality.
Can Image Enhancement be Beneficial to Find Smoke Images in Laparoscopic Surgery?
Dec 27, 2018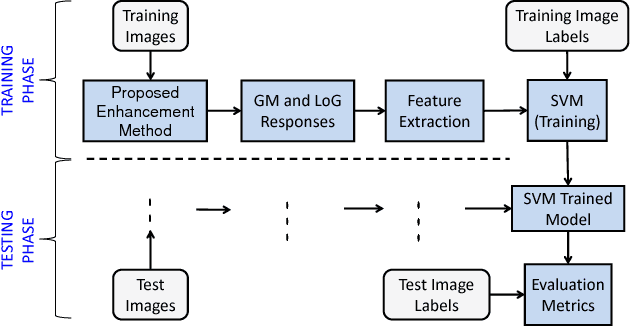
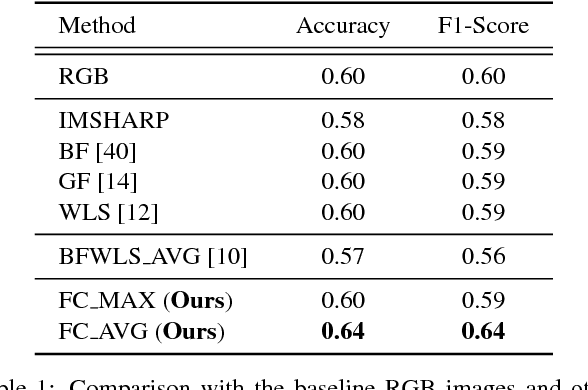
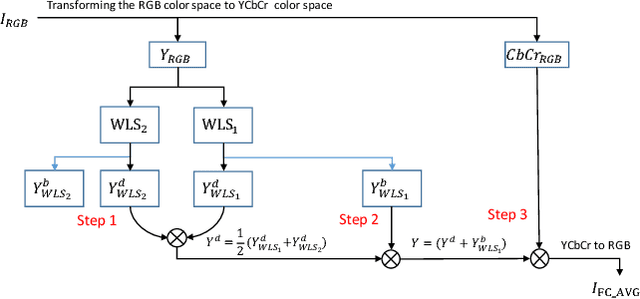

Laparoscopic surgery has a limited field of view. Laser ablation in a laproscopic surgery causes smoke, which inevitably influences the surgeon's visibility. Therefore, it is of vital importance to remove the smoke, such that a clear visualization is possible. In order to employ a desmoking technique, one needs to know beforehand if the image contains smoke or not, to this date, there exists no accurate method that could classify the smoke/non-smoke images completely. In this work, we propose a new enhancement method which enhances the informative details in the RGB images for discrimination of smoke/non-smoke images. Our proposed method utilizes weighted least squares optimization framework~(WLS). For feature extraction, we use statistical features based on bivariate histogram distribution of gradient magnitude~(GM) and Laplacian of Gaussian~(LoG). We then train a SVM classifier with binary smoke/non-smoke classification task. We demonstrate the effectiveness of our method on Cholec80 dataset. Experiments using our proposed enhancement method show promising results with improvements of 4\% in accuracy and 4\% in F1-Score over the baseline performance of RGB images. In addition, our approach improves over the saturation histogram based classification methodologies Saturation Analysis~(SAN) and Saturation Peak Analysis~(SPA) by 1/5\% and 1/6\% in accuracy/F1-Score metrics.