 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom GPT-3 to GPT-5: Mapping their capabilities, scope, limitations, and consequences
Apr 11, 2026We present the progress of the GPT family from GPT-3 through GPT-3.5, GPT-4, GPT-4 Turbo, GPT-4o, GPT-4.1, and the GPT-5 family. Our work is comparative rather than merely historical. We investigates how the family evolved in technical framing, user interaction, modality, deployment architecture, and governance viewpoint. The work focuses on five recurring themes: technical progression, capability changes, deployment shifts, persistent limitations, and downstream consequences. In term of research design, we consider official technical reports, system cards, API and model documentation, product announcements, release notes, and peer-reviewed secondary studies. A primary assertion is that later GPT generations should not be interpreted only as larger or more accurate language models. Instead, the family evolves from a scaled few-shot text predictor into a set of aligned, multimodal, tool-oriented, long-context, and increasingly workflow-integrated systems. This development complicates simple model-to-model comparison because product routing, tool access, safety tuning, and interface design become part of the effective system. Across generations, several limitations remain unchanged: hallucination, prompt sensitivity, benchmark fragility, uneven behavior across domains and populations, and incomplete public transparency about architecture and training. However, the family has evolved software development, educational practice, information work, interface design, and discussions of frontier-model governance. We infer that the transition from GPT-3 to GPT-5 is best understood not only as an improvement in model capability, but also as a broader reformulation of what a deployable AI system is, how it is evaluated, and where responsibility should be located when such systems are used at scale.
Towards Sustainable Universal Deepfake Detection with Frequency-Domain Masking
Dec 08, 2025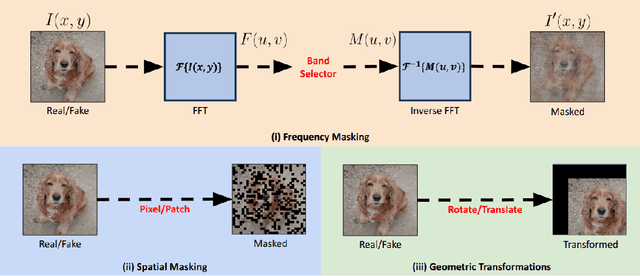
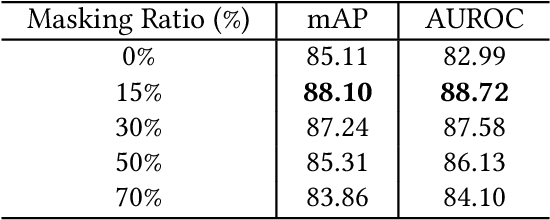
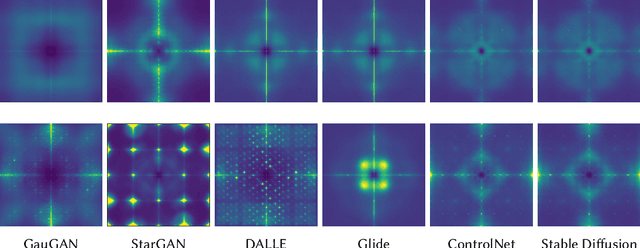
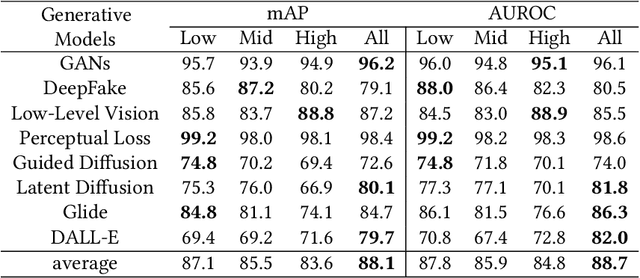
Universal deepfake detection aims to identify AI-generated images across a broad range of generative models, including unseen ones. This requires robust generalization to new and unseen deepfakes, which emerge frequently, while minimizing computational overhead to enable large-scale deepfake screening, a critical objective in the era of Green AI. In this work, we explore frequency-domain masking as a training strategy for deepfake detectors. Unlike traditional methods that rely heavily on spatial features or large-scale pretrained models, our approach introduces random masking and geometric transformations, with a focus on frequency masking due to its superior generalization properties. We demonstrate that frequency masking not only enhances detection accuracy across diverse generators but also maintains performance under significant model pruning, offering a scalable and resource-conscious solution. Our method achieves state-of-the-art generalization on GAN- and diffusion-generated image datasets and exhibits consistent robustness under structured pruning. These results highlight the potential of frequency-based masking as a practical step toward sustainable and generalizable deepfake detection. Code and models are available at: [https://github.com/chandlerbing65nm/FakeImageDetection](https://github.com/chandlerbing65nm/FakeImageDetection).
Building Trustworthy AI: Transparent AI Systems via Large Language Models, Ontologies, and Logical Reasoning (TranspNet)
Nov 13, 2024Growing concerns over the lack of transparency in AI, particularly in high-stakes fields like healthcare and finance, drive the need for explainable and trustworthy systems. While Large Language Models (LLMs) perform exceptionally well in generating accurate outputs, their "black box" nature poses significant challenges to transparency and trust. To address this, the paper proposes the TranspNet pipeline, which integrates symbolic AI with LLMs. By leveraging domain expert knowledge, retrieval-augmented generation (RAG), and formal reasoning frameworks like Answer Set Programming (ASP), TranspNet enhances LLM outputs with structured reasoning and verification. This approach ensures that AI systems deliver not only accurate but also explainable and trustworthy results, meeting regulatory demands for transparency and accountability. TranspNet provides a comprehensive solution for developing AI systems that are reliable and interpretable, making it suitable for real-world applications where trust is critical.
Symbolic-AI-Fusion Deep Learning (SAIF-DL): Encoding Knowledge into Training with Answer Set Programming Loss Penalties by a Novel Loss Function Approach
Nov 13, 2024This paper presents a hybrid methodology that enhances the training process of deep learning (DL) models by embedding domain expert knowledge using ontologies and answer set programming (ASP). By integrating these symbolic AI methods, we encode domain-specific constraints, rules, and logical reasoning directly into the model's learning process, thereby improving both performance and trustworthiness. The proposed approach is flexible and applicable to both regression and classification tasks, demonstrating generalizability across various fields such as healthcare, autonomous systems, engineering, and battery manufacturing applications. Unlike other state-of-the-art methods, the strength of our approach lies in its scalability across different domains. The design allows for the automation of the loss function by simply updating the ASP rules, making the system highly scalable and user-friendly. This facilitates seamless adaptation to new domains without significant redesign, offering a practical solution for integrating expert knowledge into DL models in industrial settings such as battery manufacturing.
RevCD -- Reversed Conditional Diffusion for Generalized Zero-Shot Learning
Aug 31, 2024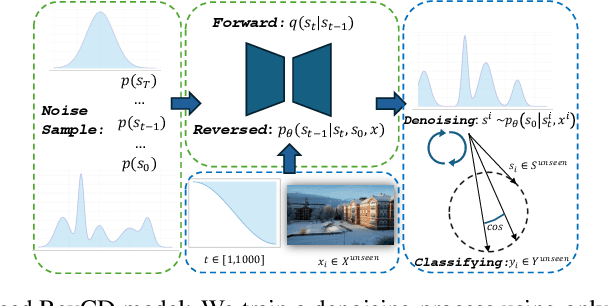

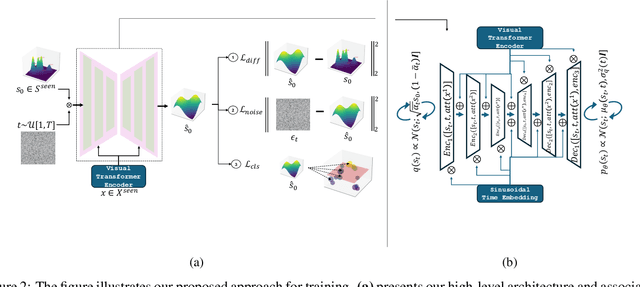

In Generalized Zero-Shot Learning (GZSL), we aim to recognize both seen and unseen categories using a model trained only on seen categories. In computer vision, this translates into a classification problem, where knowledge from seen categories is transferred to unseen categories by exploiting the relationships between visual features and available semantic information, such as text corpora or manual annotations. However, learning this joint distribution is costly and requires one-to-one training with corresponding semantic information. We present a reversed conditional Diffusion-based model (RevCD) that mitigates this issue by generating semantic features synthesized from visual inputs by leveraging Diffusion models' conditional mechanisms. Our RevCD model consists of a cross Hadamard-Addition embedding of a sinusoidal time schedule and a multi-headed visual transformer for attention-guided embeddings. The proposed approach introduces three key innovations. First, we reverse the process of generating semantic space based on visual data, introducing a novel loss function that facilitates more efficient knowledge transfer. Second, we apply Diffusion models to zero-shot learning - a novel approach that exploits their strengths in capturing data complexity. Third, we demonstrate our model's performance through a comprehensive cross-dataset evaluation. The complete code will be available on GitHub.
SEER-ZSL: Semantic Encoder-Enhanced Representations for Generalized Zero-Shot Learning
Dec 20, 2023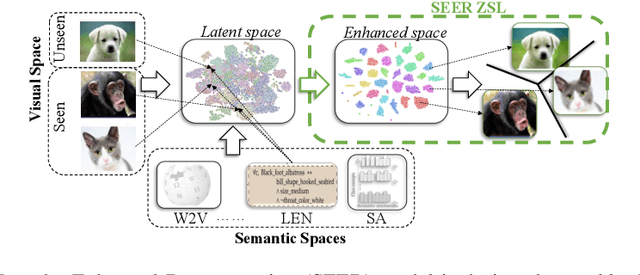
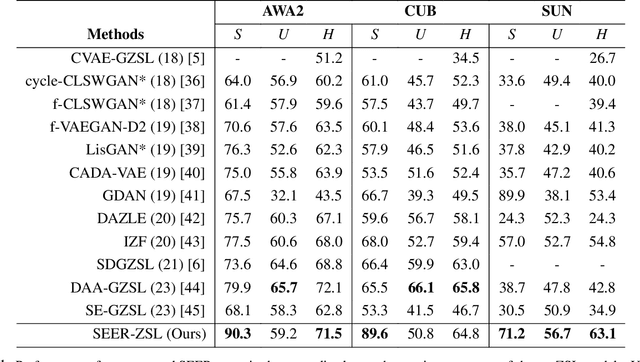
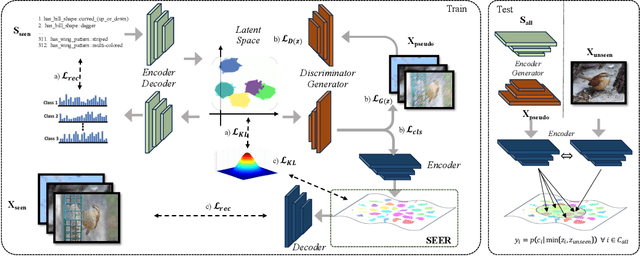
Generalized Zero-Shot Learning (GZSL) recognizes unseen classes by transferring knowledge from the seen classes, depending on the inherent interactions between visual and semantic data. However, the discrepancy between well-prepared training data and unpredictable real-world test scenarios remains a significant challenge. This paper introduces a dual strategy to address the generalization gap. Firstly, we incorporate semantic information through an innovative encoder. This encoder effectively integrates class-specific semantic information by targeting the performance disparity, enhancing the produced features to enrich the semantic space for class-specific attributes. Secondly, we refine our generative capabilities using a novel compositional loss function. This approach generates discriminative classes, effectively classifying both seen and unseen classes. In addition, we extend the exploitation of the learned latent space by utilizing controlled semantic inputs, ensuring the robustness of the model in varying environments. This approach yields a model that outperforms the state-of-the-art models in terms of both generalization and diverse settings, notably without requiring hyperparameter tuning or domain-specific adaptations. We also propose a set of novel evaluation metrics to provide a more detailed assessment of the reliability and reproducibility of the results. The complete code is made available on https://github.com/william-heyden/SEER-ZeroShotLearning/.
An Integral Projection-based Semantic Autoencoder for Zero-Shot Learning
Jun 26, 2023Zero-shot Learning (ZSL) classification categorizes or predicts classes (labels) that are not included in the training set (unseen classes). Recent works proposed different semantic autoencoder (SAE) models where the encoder embeds a visual feature vector space into the semantic space and the decoder reconstructs the original visual feature space. The objective is to learn the embedding by leveraging a source data distribution, which can be applied effectively to a different but related target data distribution. Such embedding-based methods are prone to domain shift problems and are vulnerable to biases. We propose an integral projection-based semantic autoencoder (IP-SAE) where an encoder projects a visual feature space concatenated with the semantic space into a latent representation space. We force the decoder to reconstruct the visual-semantic data space. Due to this constraint, the visual-semantic projection function preserves the discriminatory data included inside the original visual feature space. The enriched projection forces a more precise reconstitution of the visual feature space invariant to the domain manifold. Consequently, the learned projection function is less domain-specific and alleviates the domain shift problem. Our proposed IP-SAE model consolidates a symmetric transformation function for embedding and projection, and thus, it provides transparency for interpreting generative applications in ZSL. Therefore, in addition to outperforming state-of-the-art methods considering four benchmark datasets, our analytical approach allows us to investigate distinct characteristics of generative-based methods in the unique context of zero-shot inference.
A Survey of Hand Crafted and Deep Learning Methods for Image Aesthetic Assessment
Mar 22, 2021
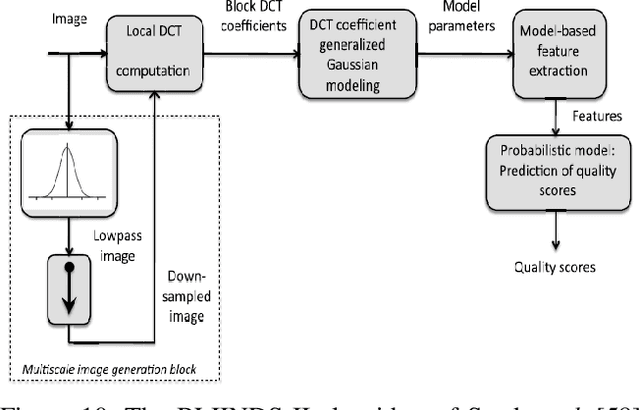
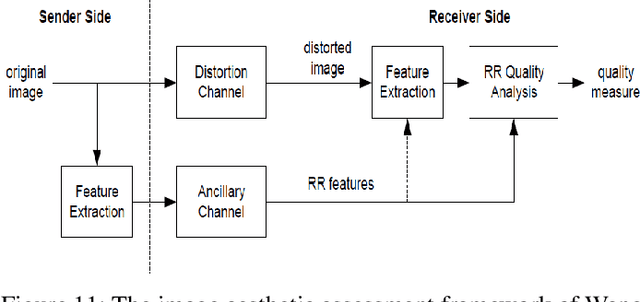
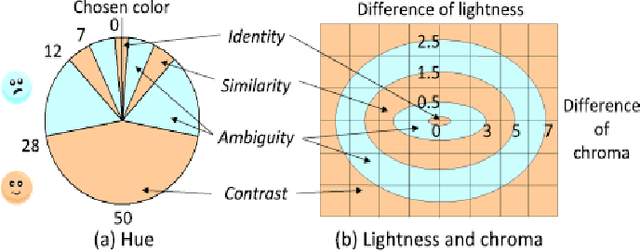
Automatic image aesthetics assessment is a computer vision problem that deals with the categorization of images into different aesthetic levels. The categorization is usually done by analyzing an input image and computing some measure of the degree to which the image adhere to the key principles of photography (balance, rhythm, harmony, contrast, unity, look, feel, tone and texture). Owing to its diverse applications in many areas, automatic image aesthetic assessment has gained significant research attention in recent years. This paper presents a literature review of the recent techniques of automatic image aesthetics assessment. A large number of traditional hand crafted and deep learning based approaches are reviewed. Key problem aspects are discussed such as why some features or models perform better than others and what are the limitations. A comparison of the quantitative results of different methods is also provided at the end.
Anomalous entities detection using a cascade of deep learning models
Mar 09, 2021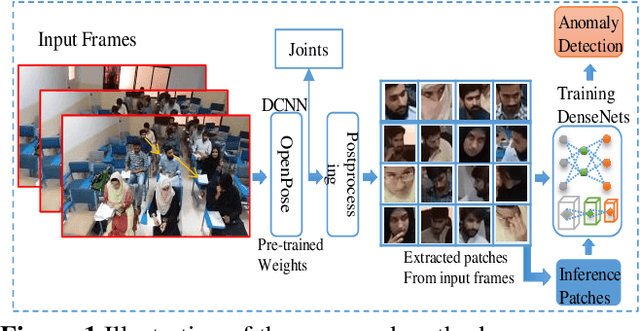
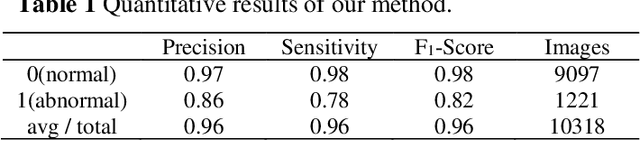
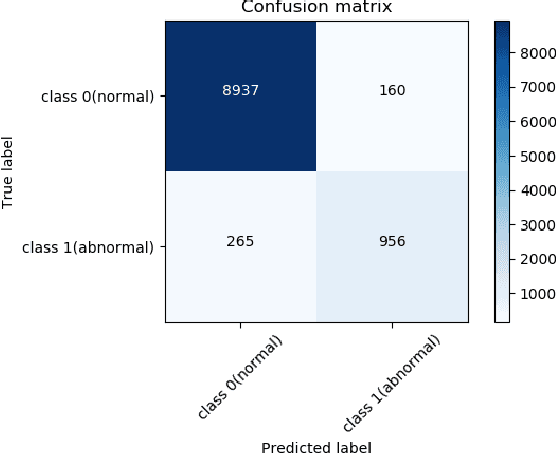

Human actions that do not conform to usual behavior are considered as anomalous and such actors are called anomalous entities. Detection of anomalous entities using visual data is a challenging problem in computer vision. This paper presents a new approach to detect anomalous entities in complex situations of examination halls. The proposed method uses a cascade of deep convolutional neural network models. In the first stage, we apply a pretrained model of human pose estimation on frames of videos to extract key feature points of body. Patches extracted from each key point are utilized in the second stage to build a densely connected deep convolutional neural network model for detecting anomalous entities. For experiments we collect a video database of students undertaking examination in a hall. Our results show that the proposed method can detect anomalous entities and warrant unusual behavior with high accuracy.
Kalman Filter Based Multiple Person Head Tracking
Jun 11, 2020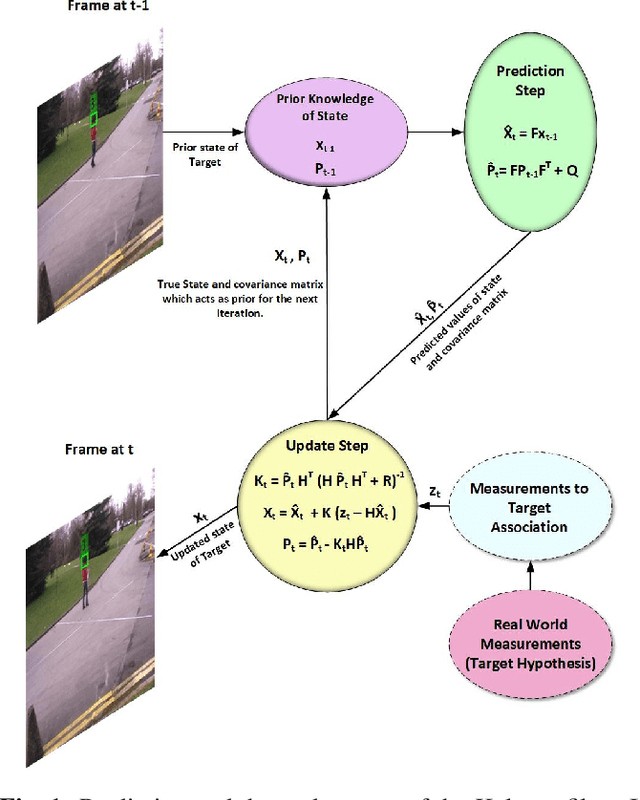

For multi-target tracking, target representation plays a crucial rule in performance. State-of-the-art approaches rely on the deep learning-based visual representation that gives an optimal performance at the cost of high computational complexity. In this paper, we come up with a simple yet effective target representation for human tracking. Our inspiration comes from the fact that the human body goes through severe deformation and inter/intra occlusion over the passage of time. So, instead of tracking the whole body part, a relative rigid organ tracking is selected for tracking the human over an extended period of time. Hence, we followed the tracking-by-detection paradigm and generated the target hypothesis of only the spatial locations of heads in every frame. After the localization of head location, a Kalman filter with a constant velocity motion model is instantiated for each target that follows the temporal evolution of the targets in the scene. For associating the targets in the consecutive frames, combinatorial optimization is used that associates the corresponding targets in a greedy fashion. Qualitative results are evaluated on four challenging video surveillance dataset and promising results has been achieved.