 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effects of Grouped Structural Global Pruning of Vision Transformers on Domain Generalisation
Apr 05, 2025With the growing sizes of AI models like large language models (LLMs) and vision transformers, deploying them on devices with limited computational resources is a significant challenge particularly when addressing domain generalisation (DG) tasks. This paper introduces a novel grouped structural pruning method for pre-trained vision transformers (ViT, BeiT, and DeiT), evaluated on the PACS and Office-Home DG benchmarks. Our method uses dependency graph analysis to identify and remove redundant groups of neurons, weights, filters, or attention heads within transformers, using a range of selection metrics. Grouped structural pruning is applied at pruning ratios of 50\%, 75\% and 95\% and the models are then fine-tuned on selected distributions from DG benchmarks to evaluate their overall performance in DG tasks. Results show significant improvements in inference speed and fine-tuning time with minimal trade-offs in accuracy and DG task performance. For instance, on the PACS benchmark, pruning ViT, BeiT, and DeiT models by 50\% using the Hessian metric resulted in accuracy drops of only -2.94\%, -1.42\%, and -1.72\%, respectively, while achieving speed boosts of 2.5x, 1.81x, and 2.15x. These findings demonstrate the effectiveness of our approach in balancing model efficiency with domain generalisation performance.
Resilience of Vision Transformers for Domain Generalisation in the Presence of Out-of-Distribution Noisy Images
Apr 05, 2025



Modern AI models excel in controlled settings but often fail in real-world scenarios where data distributions shift unpredictably - a challenge known as domain generalisation (DG). This paper tackles this limitation by rigorously evaluating vision tramsformers, specifically the BEIT architecture which is a model pre-trained with masked image modelling (MIM), against synthetic out-of-distribution (OOD) benchmarks designed to mimic real-world noise and occlusions. We introduce a novel framework to generate OOD test cases by strategically masking object regions in images using grid patterns (25\%, 50\%, 75\% occlusion) and leveraging cutting-edge zero-shot segmentation via Segment Anything and Grounding DINO to ensure precise object localisation. Experiments across three benchmarks (PACS, Office-Home, DomainNet) demonstrate BEIT's known robustness while maintaining 94\% accuracy on PACS and 87\% on Office-Home, despite significant occlusions, outperforming CNNs and other vision transformers by margins of up to 37\%. Analysis of self-attention distances reveals that the BEIT dependence on global features correlates with its resilience. Furthermore, our synthetic benchmarks expose critical failure modes: performance degrades sharply when occlusions disrupt object shapes e.g. 68\% drop for external grid masking vs. 22\% for internal masking. This work provides two key advances (1) a scalable method to generate OOD benchmarks using controllable noise, and (2) empirical evidence that MIM and self-attention mechanism in vision transformers enhance DG by learning invariant features. These insights bridge the gap between lab-trained models and real-world deployment that offer a blueprint for building AI systems that generalise reliably under uncertainty.
Domain Generalisation with Bidirectional Encoder Representations from Vision Transformers
Jul 16, 2023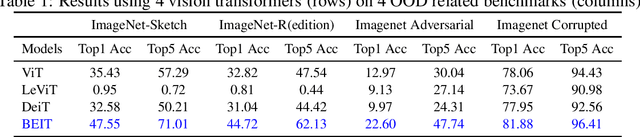

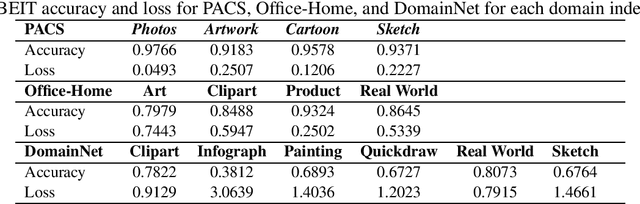
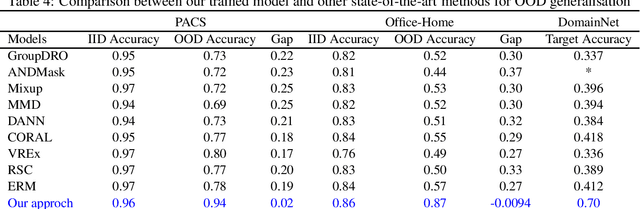
Domain generalisation involves pooling knowledge from source domain(s) into a single model that can generalise to unseen target domain(s). Recent research in domain generalisation has faced challenges when using deep learning models as they interact with data distributions which differ from those they are trained on. Here we perform domain generalisation on out-of-distribution (OOD) vision benchmarks using vision transformers. Initially we examine four vision transformer architectures namely ViT, LeViT, DeiT, and BEIT on out-of-distribution data. As the bidirectional encoder representation from image transformers (BEIT) architecture performs best, we use it in further experiments on three benchmarks PACS, Home-Office and DomainNet. Our results show significant improvements in validation and test accuracy and our implementation significantly overcomes gaps between within-distribution and OOD data.
Vision Based Machine Learning Algorithms for Out-of-Distribution Generalisation
Jan 17, 2023There are many computer vision applications including object segmentation, classification, object detection, and reconstruction for which machine learning (ML) shows state-of-the-art performance. Nowadays, we can build ML tools for such applications with real-world accuracy. However, each tool works well within the domain in which it has been trained and developed. Often, when we train a model on a dataset in one specific domain and test on another unseen domain known as an out of distribution (OOD) dataset, models or ML tools show a decrease in performance. For instance, when we train a simple classifier on real-world images and apply that model on the same classes but with a different domain like cartoons, paintings or sketches then the performance of ML tools disappoints. This presents serious challenges of domain generalisation (DG), domain adaptation (DA), and domain shifting. To enhance the power of ML tools, we can rebuild and retrain models from scratch or we can perform transfer learning. In this paper, we present a comparison study between vision-based technologies for domain-specific and domain-generalised methods. In this research we highlight that simple convolutional neural network (CNN) based deep learning methods perform poorly when they have to tackle domain shifting. Experiments are conducted on two popular vision-based benchmarks, PACS and Office-Home. We introduce an implementation pipeline for domain generalisation methods and conventional deep learning models. The outcome confirms that CNN-based deep learning models show poor generalisation compare to other extensive methods.
Facilitating reflection in teletandem through automatically generated conversation metrics and playback video
Nov 18, 2021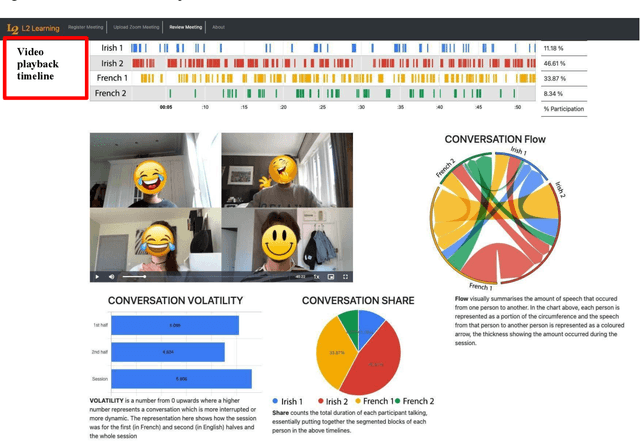
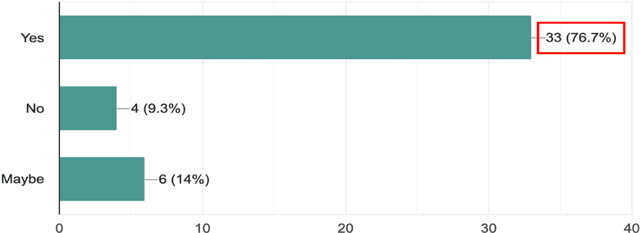
This pilot study focuses on a tool called L2L that allows second language (L2) learners to visualise and analyse their Zoom interactions with native speakers. L2L uses the Zoom transcript to automatically generate conversation metrics and its playback feature with timestamps allows students to replay any chosen portion of the conversation for post-session reflection and self-review. This exploratory study investigates a seven-week teletandem project, where undergraduate students from an Irish University learning French (B2) interacted with their peers from a French University learning English (B2+) via Zoom. The data collected from a survey (N=43) and semi-structured interviews (N=35) show that the quantitative conversation metrics and qualitative review of the synchronous content helped raise students' confidence levels while engaging with native speakers. Furthermore, it allowed them to set tangible goals to improve their participation, and be more aware of what, why and how they are learning.
* 5 pages
Anomalous entities detection using a cascade of deep learning models
Mar 09, 2021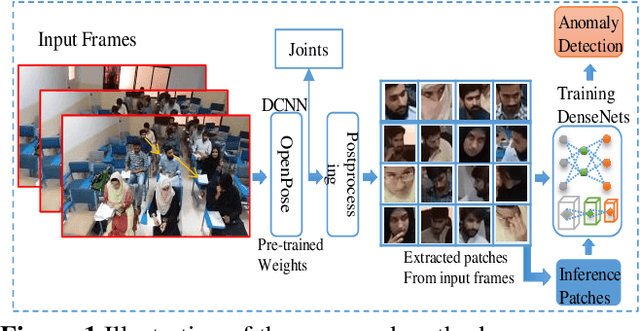
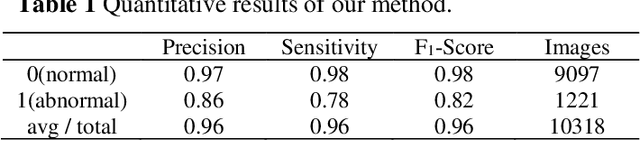
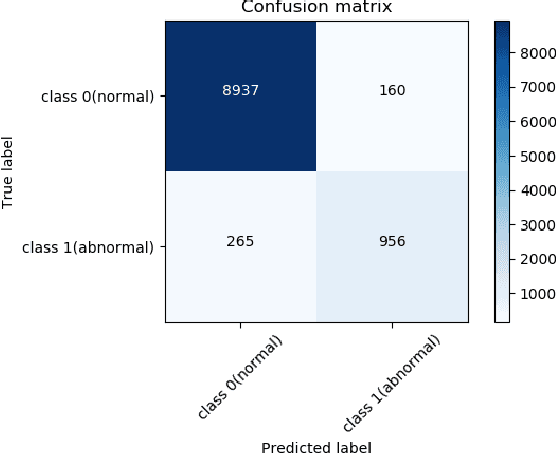

Human actions that do not conform to usual behavior are considered as anomalous and such actors are called anomalous entities. Detection of anomalous entities using visual data is a challenging problem in computer vision. This paper presents a new approach to detect anomalous entities in complex situations of examination halls. The proposed method uses a cascade of deep convolutional neural network models. In the first stage, we apply a pretrained model of human pose estimation on frames of videos to extract key feature points of body. Patches extracted from each key point are utilized in the second stage to build a densely connected deep convolutional neural network model for detecting anomalous entities. For experiments we collect a video database of students undertaking examination in a hall. Our results show that the proposed method can detect anomalous entities and warrant unusual behavior with high accuracy.
Attention Based Video Summaries of Live Online Zoom Classes
Jan 15, 2021This paper describes a system developed to help University students get more from their online lectures, tutorials, laboratory and other live sessions. We do this by logging their attention levels on their laptops during live Zoom sessions and providing them with personalised video summaries of those live sessions. Using facial attention analysis software we create personalised video summaries composed of just the parts where a student's attention was below some threshold. We can also factor in other criteria into video summary generation such as parts where the student was not paying attention while others in the class were, and parts of the video that other students have replayed extensively which a given student has not. Attention and usage based video summaries of live classes are a form of personalised content, they are educational video segments recommended to highlight important parts of live sessions, useful in both topic understanding and in exam preparation. The system also allows a Professor to review the aggregated attention levels of those in a class who attended a live session and logged their attention levels. This allows her to see which parts of the live activity students were paying most, and least, attention to. The Help-Me-Watch system is deployed and in use at our University in a way that protects student's personal data, operating in a GDPR-compliant way.