 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Knowledge Distillation for PET-Free Amyloid-Beta Detection from MRI
Apr 14, 2026Detecting amyloid-$β$ (A$β$) positivity is crucial for early diagnosis of Alzheimer's disease but typically requires PET imaging, which is costly, invasive, and not widely accessible, limiting its use for population-level screening. We address this gap by proposing a PET-guided knowledge distillation framework that enables A$β$ prediction from MRI alone, without requiring non-imaging clinical covariates or PET at inference. Our approach employs a BiomedCLIP-based teacher model that learns PET-MRI alignment via cross-modal attention and triplet contrastive learning with PET-informed (Centiloid-aware) online negative sampling. An MRI-only student then mimics the teacher via feature-level and logit-level distillation. Evaluated across four MRI contrasts (T1w, T2w, FLAIR, T2*) and two independent datasets, our approach demonstrates effective knowledge transfer (best AUC: 0.74 on OASIS-3, 0.68 on ADNI) while maintaining interpretability and eliminating the need for clinical variables. Saliency analysis confirms that predictions focus on anatomically relevant cortical regions, supporting the clinical viability of PET-free A$β$ screening. Code is available at https://github.com/FrancescoChiumento/pet-guided-mri-amyloid-detection.
Leveraging Multimodal Models for Enhanced Neuroimaging Diagnostics in Alzheimer's Disease
Nov 12, 2024



The rapid advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have shown great potential in medical diagnostics, particularly in radiology, where datasets such as X-rays are paired with human-generated diagnostic reports. However, a significant research gap exists in the neuroimaging field, especially for conditions such as Alzheimer's disease, due to the lack of comprehensive diagnostic reports that can be utilized for model fine-tuning. This paper addresses this gap by generating synthetic diagnostic reports using GPT-4o-mini on structured data from the OASIS-4 dataset, which comprises 663 patients. Using the synthetic reports as ground truth for training and validation, we then generated neurological reports directly from the images in the dataset leveraging the pre-trained BiomedCLIP and T5 models. Our proposed method achieved a BLEU-4 score of 0.1827, ROUGE-L score of 0.3719, and METEOR score of 0.4163, revealing its potential in generating clinically relevant and accurate diagnostic reports.
Synthetic Time Series for Anomaly Detection in Cloud Microservices
Jul 21, 2024



This paper proposes a framework for time series generation built to investigate anomaly detection in cloud microservices. In the field of cloud computing, ensuring the reliability of microservices is of paramount concern and yet a remarkably challenging task. Despite the large amount of research in this area, validation of anomaly detection algorithms in realistic environments is difficult to achieve. To address this challenge, we propose a framework to mimic the complex time series patterns representative of both normal and anomalous cloud microservices behaviors. We detail the pipeline implementation that allows deployment and management of microservices as well as the theoretical approach required to generate anomalies. Two datasets generated using the proposed framework have been made publicly available through GitHub.
Improved impedance inversion by deep learning and iterated graph Laplacian
Apr 25, 2024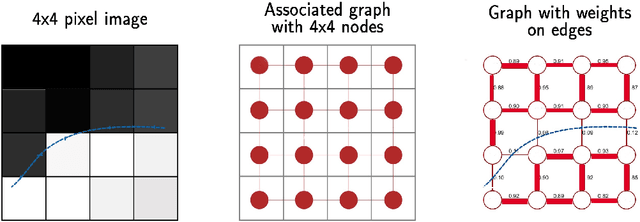
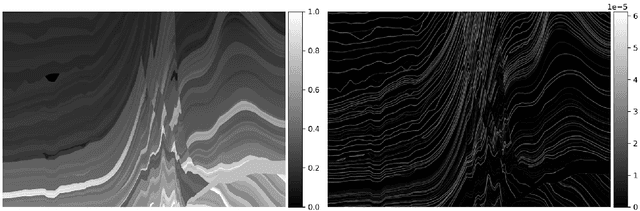
Deep learning techniques have shown significant potential in many applications through recent years. The achieved results often outperform traditional techniques. However, the quality of a neural network highly depends on the used training data. Noisy, insufficient, or biased training data leads to suboptimal results. We present a hybrid method that combines deep learning with iterated graph Laplacian and show its application in acoustic impedance inversion which is a routine procedure in seismic explorations. A neural network is used to obtain a first approximation of the underlying acoustic impedance and construct a graph Laplacian matrix from this approximation. Afterwards, we use a Tikhonov-like variational method to solve the impedance inversion problem where the regularizer is based on the constructed graph Laplacian. The obtained solution can be shown to be more accurate and stable with respect to noise than the initial guess obtained by the neural network. This process can be iterated several times, each time constructing a new graph Laplacian matrix from the most recent reconstruction. The method converges after only a few iterations returning a much more accurate reconstruction. We demonstrate the potential of our method on two different datasets and under various levels of noise. We use two different neural networks that have been introduced in previous works. The experiments show that our approach improves the reconstruction quality in the presence of noise.
Data-driven Energy Consumption Modelling for Electric Micromobility using an Open Dataset
Mar 26, 2024



The escalating challenges of traffic congestion and environmental degradation underscore the critical importance of embracing E-Mobility solutions in urban spaces. In particular, micro E-Mobility tools such as E-scooters and E-bikes, play a pivotal role in this transition, offering sustainable alternatives for urban commuters. However, the energy consumption patterns for these tools are a critical aspect that impacts their effectiveness in real-world scenarios and is essential for trip planning and boosting user confidence in using these. To this effect, recent studies have utilised physical models customised for specific mobility tools and conditions, but these models struggle with generalization and effectiveness in real-world scenarios due to a notable absence of open datasets for thorough model evaluation and verification. To fill this gap, our work presents an open dataset, collected in Dublin, Ireland, specifically designed for energy modelling research related to E-Scooters and E-Bikes. Furthermore, we provide a comprehensive analysis of energy consumption modelling based on the dataset using a set of representative machine learning algorithms and compare their performance against the contemporary mathematical models as a baseline. Our results demonstrate a notable advantage for data-driven models in comparison to the corresponding mathematical models for estimating energy consumption. Specifically, data-driven models outperform physical models in accuracy by up to 83.83% for E-Bikes and 82.16% for E-Scooters based on an in-depth analysis of the dataset under certain assumptions.
Optimal Design and Implementation of an Open-source Emulation Platform for User-Centric Shared E-mobility Services
Mar 12, 2024In response to the escalating global challenge of increasing emissions and pollution in transportation, shared electric mobility services, encompassing e-cars, e-bikes, and e-scooters, have emerged as a popular strategy. However, existingshared electric mobility services exhibit critical design deficiencies, including insufficient service integration, imprecise energy consumption forecasting, limited scalability and geographical coverage, and a notable absence of a user-centric perspective, particularly in the context of multi-modal transportation. More importantly, there is no consolidated open-source framework which could benefit the e-mobility research community. This paper aims to bridge this gap by providing a pioneering open-source framework for shared e-mobility. The proposed framework, with an agent-in-the-loop approach and modular architecture, is tailored to diverse user preferences and offers enhanced customization. We demonstrate the viability of this framework by solving an integrated multi-modal route-optimization problem using the modified Ant Colony Optimization (ACO) algorithm. The primary contribution of this work is to provide a collaborative and transparent framework to tackle the dynamic challenges in the field of e-mobility research using a consolidated approach.
Privacy-Aware Energy Consumption Modeling of Connected Battery Electric Vehicles using Federated Learning
Dec 12, 2023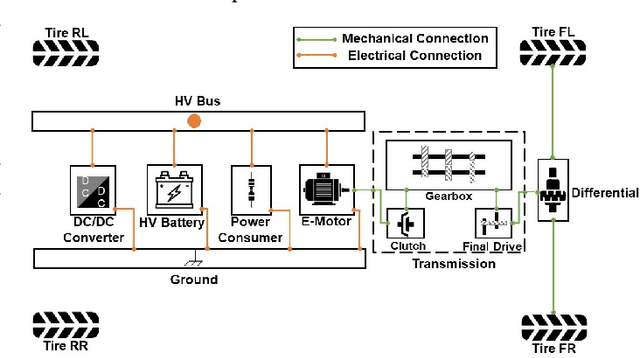
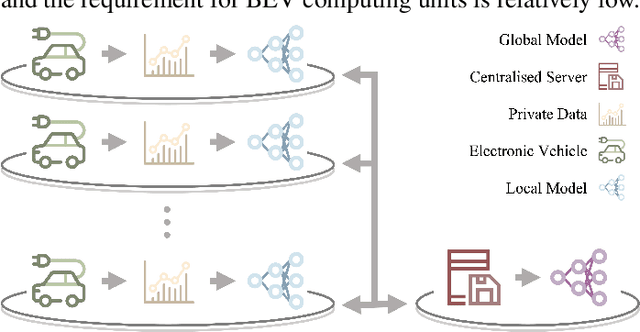
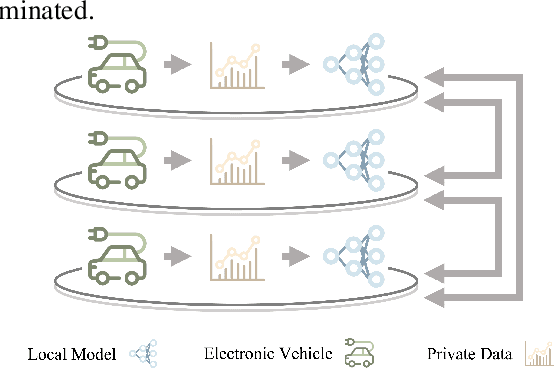
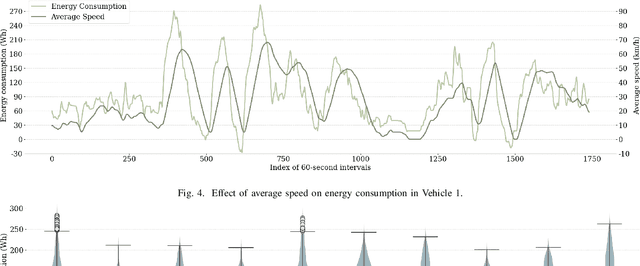
Battery Electric Vehicles (BEVs) are increasingly significant in modern cities due to their potential to reduce air pollution. Precise and real-time estimation of energy consumption for them is imperative for effective itinerary planning and optimizing vehicle systems, which can reduce driving range anxiety and decrease energy costs. As public awareness of data privacy increases, adopting approaches that safeguard data privacy in the context of BEV energy consumption modeling is crucial. Federated Learning (FL) is a promising solution mitigating the risk of exposing sensitive information to third parties by allowing local data to remain on devices and only sharing model updates with a central server. Our work investigates the potential of using FL methods, such as FedAvg, and FedPer, to improve BEV energy consumption prediction while maintaining user privacy. We conducted experiments using data from 10 BEVs under simulated real-world driving conditions. Our results demonstrate that the FedAvg-LSTM model achieved a reduction of up to 67.84\% in the MAE value of the prediction results. Furthermore, we explored various real-world scenarios and discussed how FL methods can be employed in those cases. Our findings show that FL methods can effectively improve the performance of BEV energy consumption prediction while maintaining user privacy.
A Review on AI Algorithms for Energy Management in E-Mobility Services
Sep 26, 2023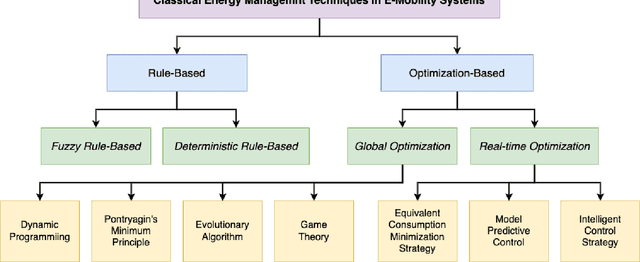
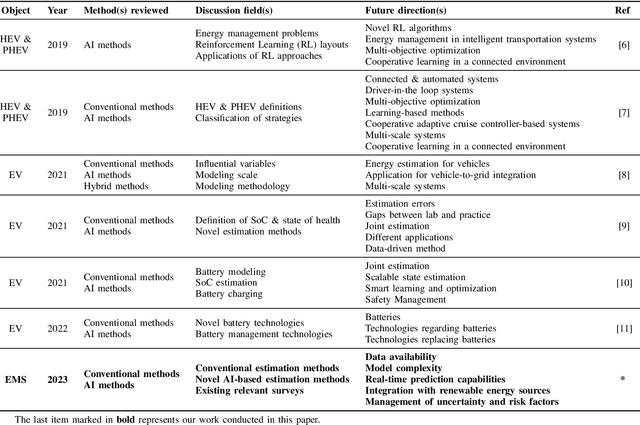
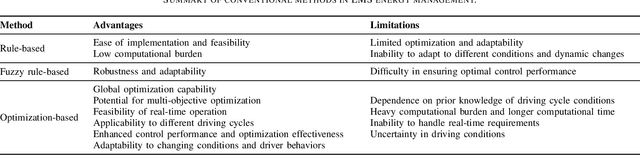
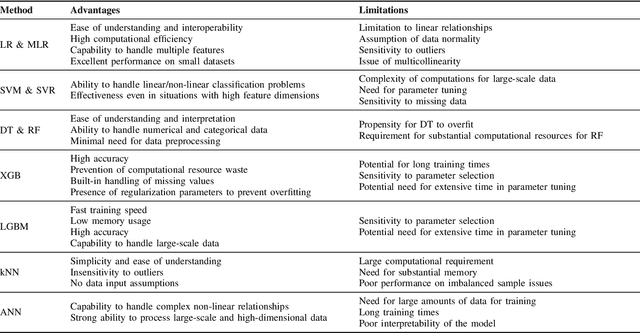
E-mobility, or electric mobility, has emerged as a pivotal solution to address pressing environmental and sustainability concerns in the transportation sector. The depletion of fossil fuels, escalating greenhouse gas emissions, and the imperative to combat climate change underscore the significance of transitioning to electric vehicles (EVs). This paper seeks to explore the potential of artificial intelligence (AI) in addressing various challenges related to effective energy management in e-mobility systems (EMS). These challenges encompass critical factors such as range anxiety, charge rate optimization, and the longevity of energy storage in EVs. By analyzing existing literature, we delve into the role that AI can play in tackling these challenges and enabling efficient energy management in EMS. Our objectives are twofold: to provide an overview of the current state-of-the-art in this research domain and propose effective avenues for future investigations. Through this analysis, we aim to contribute to the advancement of sustainable and efficient e-mobility solutions, shaping a greener and more sustainable future for transportation.
Recent Advances in Graph-based Machine Learning for Applications in Smart Urban Transportation Systems
Jun 02, 2023

The Intelligent Transportation System (ITS) is an important part of modern transportation infrastructure, employing a combination of communication technology, information processing and control systems to manage transportation networks. This integration of various components such as roads, vehicles, and communication systems, is expected to improve efficiency and safety by providing better information, services, and coordination of transportation modes. In recent years, graph-based machine learning has become an increasingly important research focus in the field of ITS aiming at the development of complex, data-driven solutions to address various ITS-related challenges. This chapter presents background information on the key technical challenges for ITS design, along with a review of research methods ranging from classic statistical approaches to modern machine learning and deep learning-based approaches. Specifically, we provide an in-depth review of graph-based machine learning methods, including basic concepts of graphs, graph data representation, graph neural network architectures and their relation to ITS applications. Additionally, two case studies of graph-based ITS applications proposed in our recent work are presented in detail to demonstrate the potential of graph-based machine learning in the ITS domain.
Classical Sequence Match is a Competitive Few-Shot One-Class Learner
Sep 14, 2022
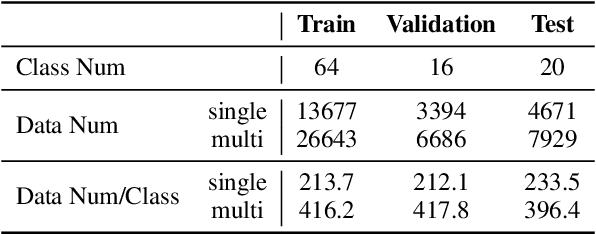
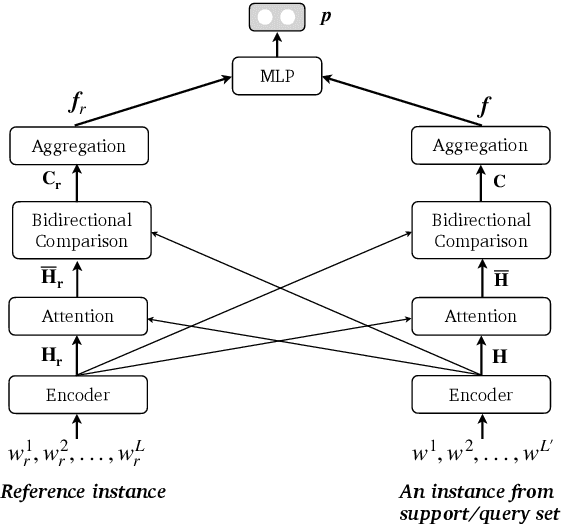
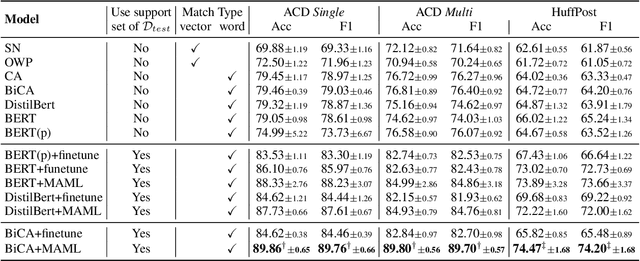
Nowadays, transformer-based models gradually become the default choice for artificial intelligence pioneers. The models also show superiority even in the few-shot scenarios. In this paper, we revisit the classical methods and propose a new few-shot alternative. Specifically, we investigate the few-shot one-class problem, which actually takes a known sample as a reference to detect whether an unknown instance belongs to the same class. This problem can be studied from the perspective of sequence match. It is shown that with meta-learning, the classical sequence match method, i.e. Compare-Aggregate, significantly outperforms transformer ones. The classical approach requires much less training cost. Furthermore, we perform an empirical comparison between two kinds of sequence match approaches under simple fine-tuning and meta-learning. Meta-learning causes the transformer models' features to have high-correlation dimensions. The reason is closely related to the number of layers and heads of transformer models. Experimental codes and data are available at https://github.com/hmt2014/FewOne