 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Inpainting MIMO-OFDM Channels with Limited Noisy Observations
Apr 10, 2026Acquiring the channel state information from limited and noisy observations at pilot positions is critical for wireless multiple-input multiple-output (MIMO)-orthogonal frequency division multiplexing (OFDM) systems. In this paper, we view this process as a conditional generative task in which the partial noisy channel estimates at the pilots are utilized as a ``prompt'' to guide the diffusion ``inpainting'' of the underlying channel. To this end, we resort to a general Conditional Diffusion Transformer (CDiT) framework with a well-designed network architecture and update rule. In particular, we design a dedicated embedding strategy to encode and adapt to different pilot patterns and noise levels, and utilize a special cross-attention mechanism to align the partial raw channel observations with the denoised channel at each time step of the generation process. This architecture effectively anchors the diffusion process, enabling the model to accurately recover full channel details from limited noisy observations. Comprehensive experimental results show that, the proposed approach achieves a performance gain of over 5 dB compared to the baselines under varying noise conditions, and provides robust channel acquisition even under a sparse pilot density of 1/32 without significant performance loss compared to the denser pilot cases. Moreover, it is capable of generating high-quality channel matrices within just 10 inference steps, effectively balancing estimation accuracy with computational efficiency and inference speed. Ablation studies demonstrate the rationality of the model design and the necessity of its modules.
Reading Radio from Camera: Visually-Grounded, Lightweight, and Interpretable RSSI Prediction
Oct 29, 2025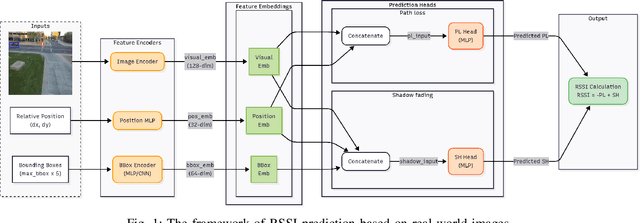
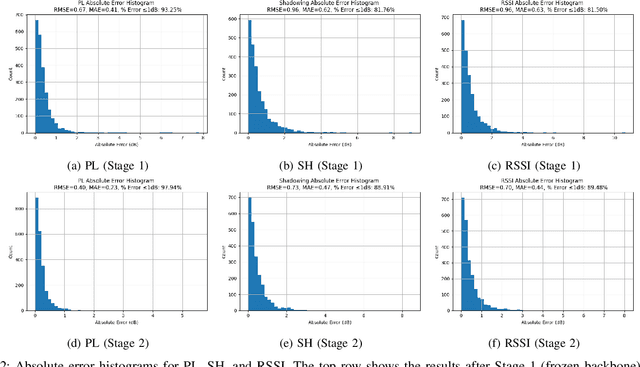
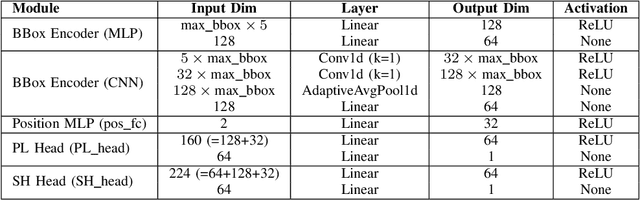
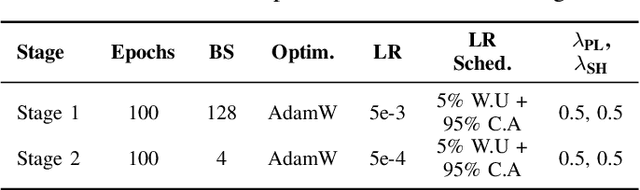
Accurate, real-time wireless signal prediction is essential for next-generation networks. However, existing vision-based frameworks often rely on computationally intensive models and are also sensitive to environmental interference. To overcome these limitations, we propose a novel, physics-guided and light-weighted framework that predicts the received signal strength indicator (RSSI) from camera images. By decomposing RSSI into its physically interpretable components, path loss and shadow fading, we significantly reduce the model's learning difficulty and exhibit interpretability. Our approach establishes a new state-of-the-art by demonstrating exceptional robustness to environmental interference, a critical flaw in prior work. Quantitatively, our model reduces the prediction root mean squared error (RMSE) by 50.3% under conventional conditions and still achieves an 11.5% lower RMSE than the previous benchmark's interference-eliminated results. This superior performance is achieved with a remarkably lightweight framework, utilizing a MobileNet-based model up to 19 times smaller than competing solutions. The combination of high accuracy, robustness to interference, and computational efficiency makes our framework highly suitable for real-time, on-device deployment in edge devices, paving the way for more intelligent and reliable wireless communication systems.
DiffNMR: Advancing Inpainting of Randomly Sampled Nuclear Magnetic Resonance Signals
May 26, 2025Nuclear Magnetic Resonance (NMR) spectroscopy leverages nuclear magnetization to probe molecules' chemical environment, structure, and dynamics, with applications spanning from pharmaceuticals to the petroleum industry. Despite its utility, the high cost of NMR instrumentation, operation and the lengthy duration of experiments necessitate the development of computational techniques to optimize acquisition times. Non-Uniform sampling (NUS) is widely employed as a sub-sampling method to address these challenges, but it often introduces artifacts and degrades spectral quality, offsetting the benefits of reduced acquisition times. In this work, we propose the use of deep learning techniques to enhance the reconstruction quality of NUS spectra. Specifically, we explore the application of diffusion models, a relatively untapped approach in this domain. Our methodology involves applying diffusion models to both time-time and time-frequency NUS data, yielding satisfactory reconstructions of challenging spectra from the benchmark Artina dataset. This approach demonstrates the potential of diffusion models to improve the efficiency and accuracy of NMR spectroscopy as well as the superiority of using a time-frequency domain data over the time-time one, opening new landscapes for future studies.
DiffNMR2: NMR Guided Sampling Acquisition Through Diffusion Model Uncertainty
Feb 06, 2025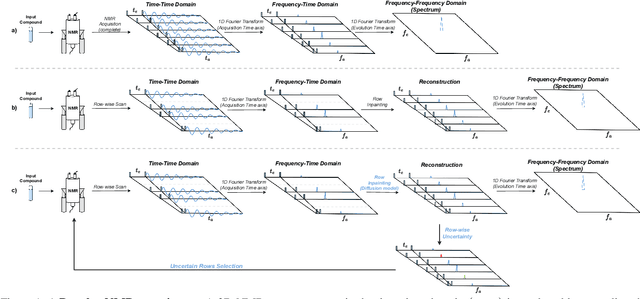
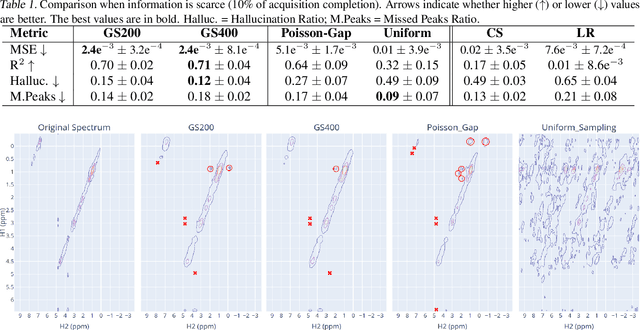
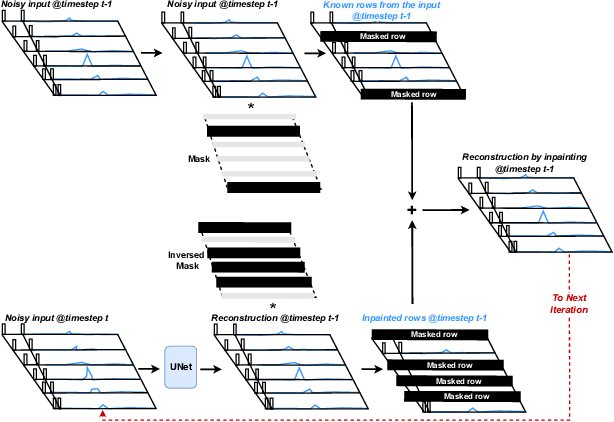
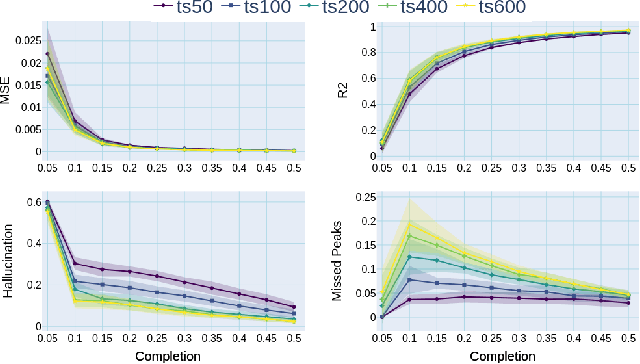
Nuclear Magnetic Resonance (NMR) spectrometry uses electro-frequency pulses to probe the resonance of a compound's nucleus, which is then analyzed to determine its structure. The acquisition time of high-resolution NMR spectra remains a significant bottleneck, especially for complex biological samples such as proteins. In this study, we propose a novel and efficient sub-sampling strategy based on a diffusion model trained on protein NMR data. Our method iteratively reconstructs under-sampled spectra while using model uncertainty to guide subsequent sampling, significantly reducing acquisition time. Compared to state-of-the-art strategies, our approach improves reconstruction accuracy by 52.9\%, reduces hallucinated peaks by 55.6%, and requires 60% less time in complex NMR experiments. This advancement holds promise for many applications, from drug discovery to materials science, where rapid and high-resolution spectral analysis is critical.
Data-driven Energy Consumption Modelling for Electric Micromobility using an Open Dataset
Mar 26, 2024



The escalating challenges of traffic congestion and environmental degradation underscore the critical importance of embracing E-Mobility solutions in urban spaces. In particular, micro E-Mobility tools such as E-scooters and E-bikes, play a pivotal role in this transition, offering sustainable alternatives for urban commuters. However, the energy consumption patterns for these tools are a critical aspect that impacts their effectiveness in real-world scenarios and is essential for trip planning and boosting user confidence in using these. To this effect, recent studies have utilised physical models customised for specific mobility tools and conditions, but these models struggle with generalization and effectiveness in real-world scenarios due to a notable absence of open datasets for thorough model evaluation and verification. To fill this gap, our work presents an open dataset, collected in Dublin, Ireland, specifically designed for energy modelling research related to E-Scooters and E-Bikes. Furthermore, we provide a comprehensive analysis of energy consumption modelling based on the dataset using a set of representative machine learning algorithms and compare their performance against the contemporary mathematical models as a baseline. Our results demonstrate a notable advantage for data-driven models in comparison to the corresponding mathematical models for estimating energy consumption. Specifically, data-driven models outperform physical models in accuracy by up to 83.83% for E-Bikes and 82.16% for E-Scooters based on an in-depth analysis of the dataset under certain assumptions.
Privacy-Aware Energy Consumption Modeling of Connected Battery Electric Vehicles using Federated Learning
Dec 12, 2023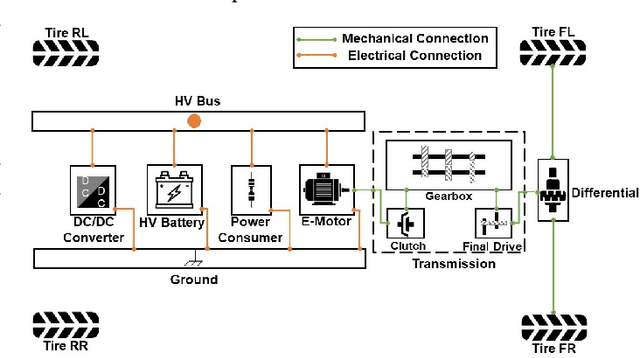
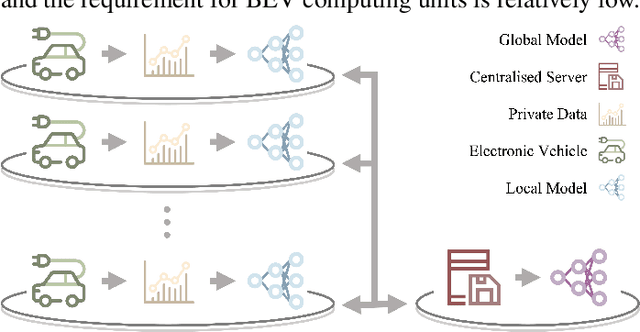
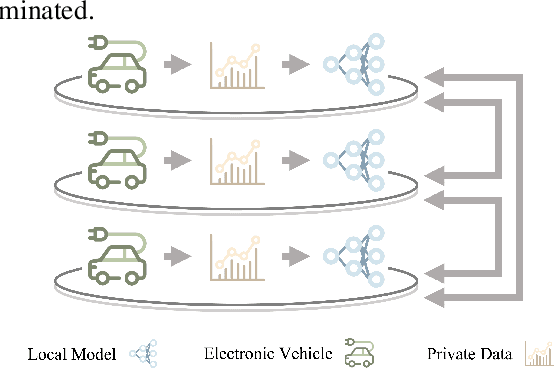
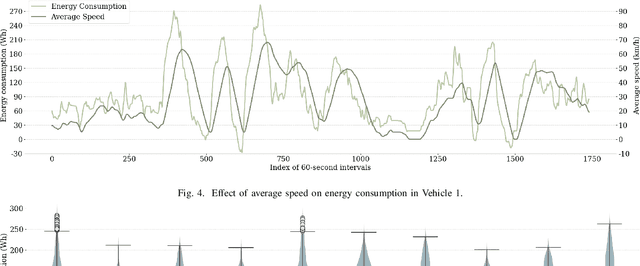
Battery Electric Vehicles (BEVs) are increasingly significant in modern cities due to their potential to reduce air pollution. Precise and real-time estimation of energy consumption for them is imperative for effective itinerary planning and optimizing vehicle systems, which can reduce driving range anxiety and decrease energy costs. As public awareness of data privacy increases, adopting approaches that safeguard data privacy in the context of BEV energy consumption modeling is crucial. Federated Learning (FL) is a promising solution mitigating the risk of exposing sensitive information to third parties by allowing local data to remain on devices and only sharing model updates with a central server. Our work investigates the potential of using FL methods, such as FedAvg, and FedPer, to improve BEV energy consumption prediction while maintaining user privacy. We conducted experiments using data from 10 BEVs under simulated real-world driving conditions. Our results demonstrate that the FedAvg-LSTM model achieved a reduction of up to 67.84\% in the MAE value of the prediction results. Furthermore, we explored various real-world scenarios and discussed how FL methods can be employed in those cases. Our findings show that FL methods can effectively improve the performance of BEV energy consumption prediction while maintaining user privacy.
A Review on AI Algorithms for Energy Management in E-Mobility Services
Sep 26, 2023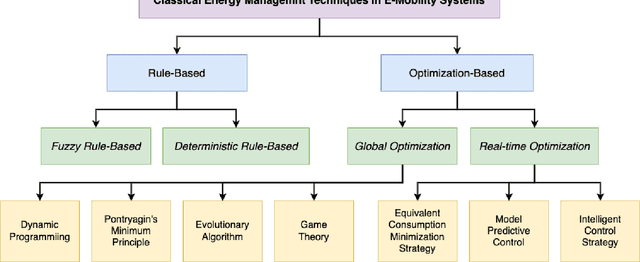
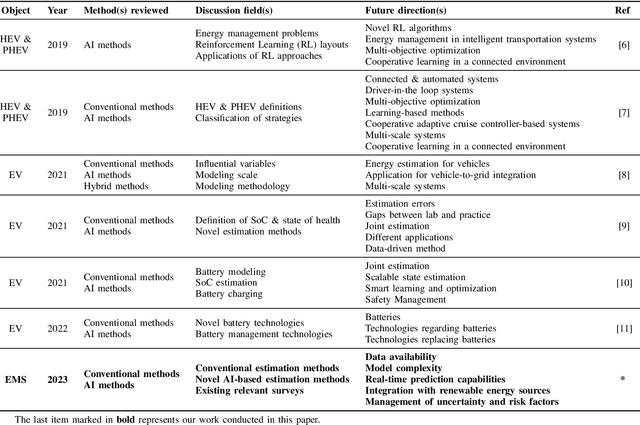
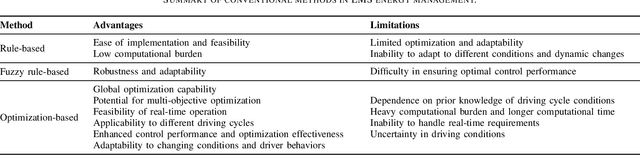
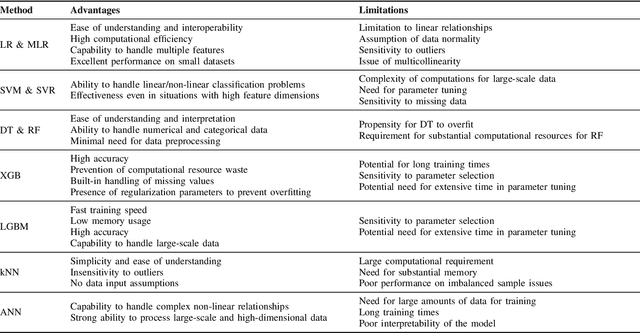
E-mobility, or electric mobility, has emerged as a pivotal solution to address pressing environmental and sustainability concerns in the transportation sector. The depletion of fossil fuels, escalating greenhouse gas emissions, and the imperative to combat climate change underscore the significance of transitioning to electric vehicles (EVs). This paper seeks to explore the potential of artificial intelligence (AI) in addressing various challenges related to effective energy management in e-mobility systems (EMS). These challenges encompass critical factors such as range anxiety, charge rate optimization, and the longevity of energy storage in EVs. By analyzing existing literature, we delve into the role that AI can play in tackling these challenges and enabling efficient energy management in EMS. Our objectives are twofold: to provide an overview of the current state-of-the-art in this research domain and propose effective avenues for future investigations. Through this analysis, we aim to contribute to the advancement of sustainable and efficient e-mobility solutions, shaping a greener and more sustainable future for transportation.
Recent Advances in Graph-based Machine Learning for Applications in Smart Urban Transportation Systems
Jun 02, 2023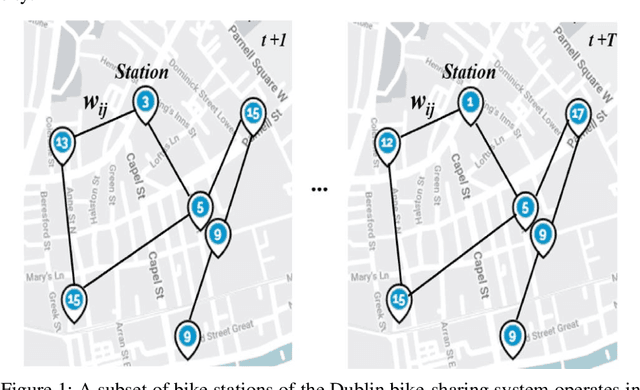

The Intelligent Transportation System (ITS) is an important part of modern transportation infrastructure, employing a combination of communication technology, information processing and control systems to manage transportation networks. This integration of various components such as roads, vehicles, and communication systems, is expected to improve efficiency and safety by providing better information, services, and coordination of transportation modes. In recent years, graph-based machine learning has become an increasingly important research focus in the field of ITS aiming at the development of complex, data-driven solutions to address various ITS-related challenges. This chapter presents background information on the key technical challenges for ITS design, along with a review of research methods ranging from classic statistical approaches to modern machine learning and deep learning-based approaches. Specifically, we provide an in-depth review of graph-based machine learning methods, including basic concepts of graphs, graph data representation, graph neural network architectures and their relation to ITS applications. Additionally, two case studies of graph-based ITS applications proposed in our recent work are presented in detail to demonstrate the potential of graph-based machine learning in the ITS domain.
Isotonic Data Augmentation for Knowledge Distillation
Jul 06, 2021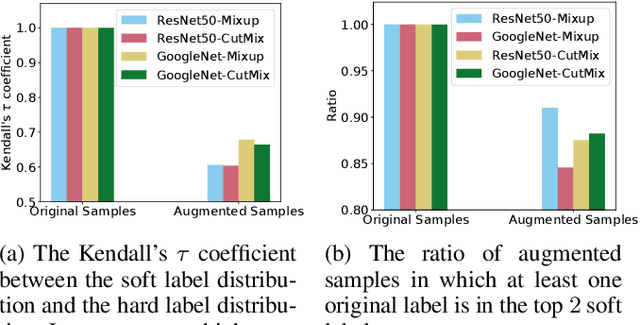

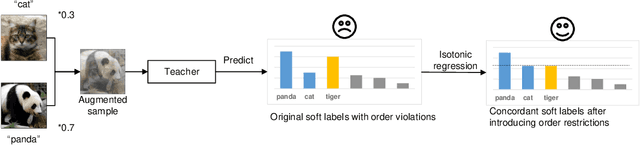

Knowledge distillation uses both real hard labels and soft labels predicted by teacher models as supervision. Intuitively, we expect the soft labels and hard labels to be concordant w.r.t. their orders of probabilities. However, we found critical order violations between hard labels and soft labels in augmented samples. For example, for an augmented sample $x=0.7*panda+0.3*cat$, we expect the order of meaningful soft labels to be $P_\text{soft}(panda|x)>P_\text{soft}(cat|x)>P_\text{soft}(other|x)$. But real soft labels usually violate the order, e.g. $P_\text{soft}(tiger|x)>P_\text{soft}(panda|x)>P_\text{soft}(cat|x)$. We attribute this to the unsatisfactory generalization ability of the teacher, which leads to the prediction error of augmented samples. Empirically, we found the violations are common and injure the knowledge transfer. In this paper, we introduce order restrictions to data augmentation for knowledge distillation, which is denoted as isotonic data augmentation (IDA). We use isotonic regression (IR) -- a classic technique from statistics -- to eliminate the order violations. We show that IDA can be modeled as a tree-structured IR problem. We thereby adapt the classical IRT-BIN algorithm for optimal solutions with $O(c \log c)$ time complexity, where $c$ is the number of labels. In order to further reduce the time complexity, we also propose a GPU-friendly approximation with linear time complexity. We have verified on variant datasets and data augmentation techniques that our proposed IDA algorithms effectively increases the accuracy of knowledge distillation by eliminating the rank violations.
Image super-resolution reconstruction based on attention mechanism and feature fusion
Apr 08, 2020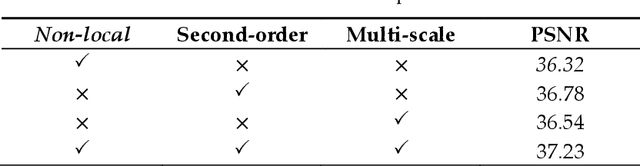
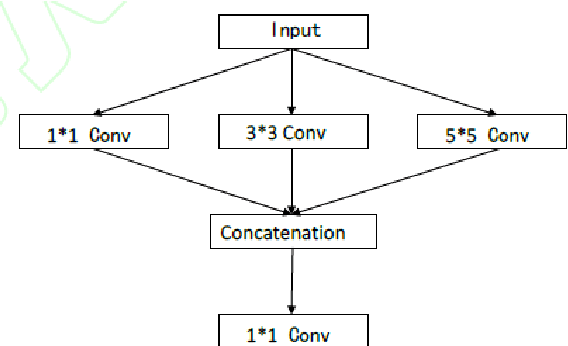
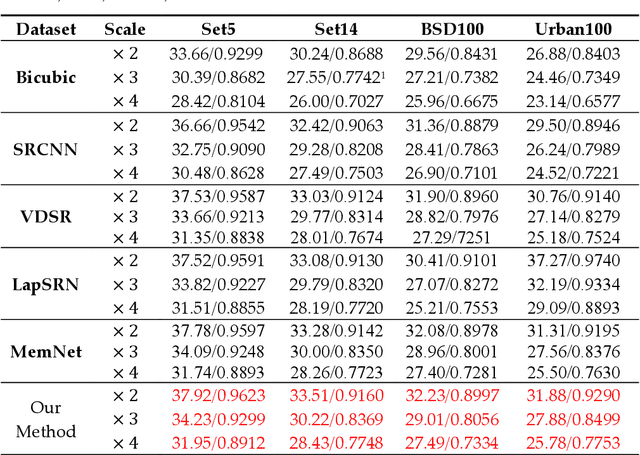
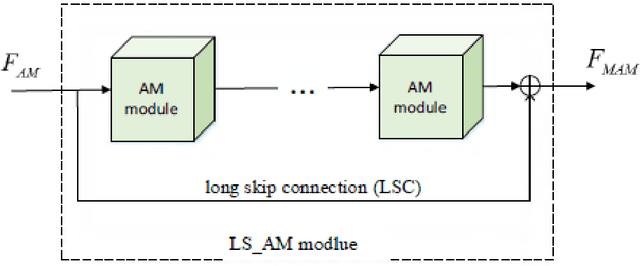
Aiming at the problems that the convolutional neural networks neglect to capture the inherent attributes of natural images and extract features only in a single scale in the field of image super-resolution reconstruction, a network structure based on attention mechanism and multi-scale feature fusion is proposed. By using the attention mechanism, the network can effectively integrate the non-local information and second-order features of the image, so as to improve the feature expression ability of the network. At the same time, the convolution kernel of different scales is used to extract the multi-scale information of the image, so as to preserve the complete information characteristics at different scales. Experimental results show that the proposed method can achieve better performance over other representative super-resolution reconstruction algorithms in objective quantitative metrics and visual quality.