 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
DiffNMR: Advancing Inpainting of Randomly Sampled Nuclear Magnetic Resonance Signals
May 26, 2025Nuclear Magnetic Resonance (NMR) spectroscopy leverages nuclear magnetization to probe molecules' chemical environment, structure, and dynamics, with applications spanning from pharmaceuticals to the petroleum industry. Despite its utility, the high cost of NMR instrumentation, operation and the lengthy duration of experiments necessitate the development of computational techniques to optimize acquisition times. Non-Uniform sampling (NUS) is widely employed as a sub-sampling method to address these challenges, but it often introduces artifacts and degrades spectral quality, offsetting the benefits of reduced acquisition times. In this work, we propose the use of deep learning techniques to enhance the reconstruction quality of NUS spectra. Specifically, we explore the application of diffusion models, a relatively untapped approach in this domain. Our methodology involves applying diffusion models to both time-time and time-frequency NUS data, yielding satisfactory reconstructions of challenging spectra from the benchmark Artina dataset. This approach demonstrates the potential of diffusion models to improve the efficiency and accuracy of NMR spectroscopy as well as the superiority of using a time-frequency domain data over the time-time one, opening new landscapes for future studies.
DiffNMR2: NMR Guided Sampling Acquisition Through Diffusion Model Uncertainty
Feb 06, 2025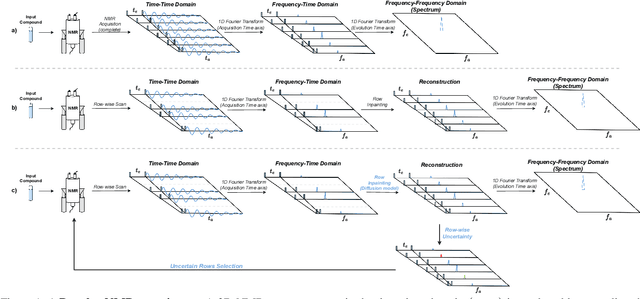
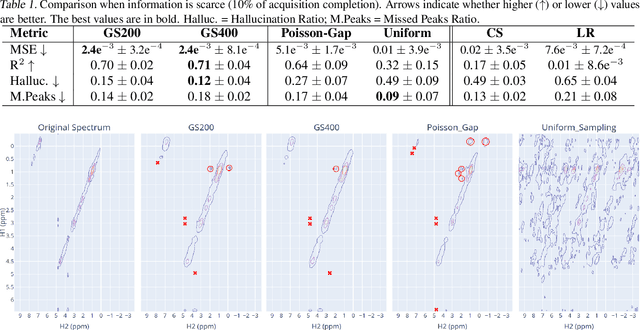
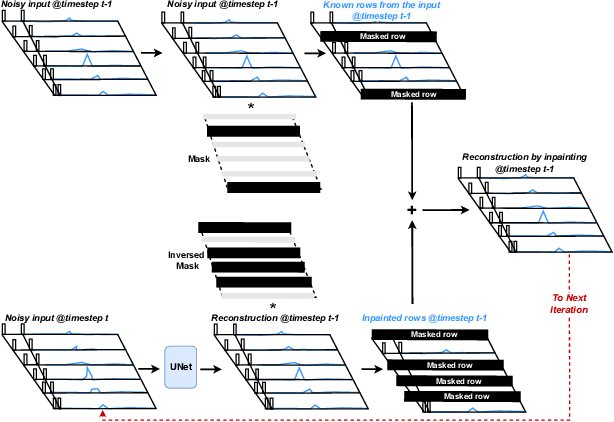
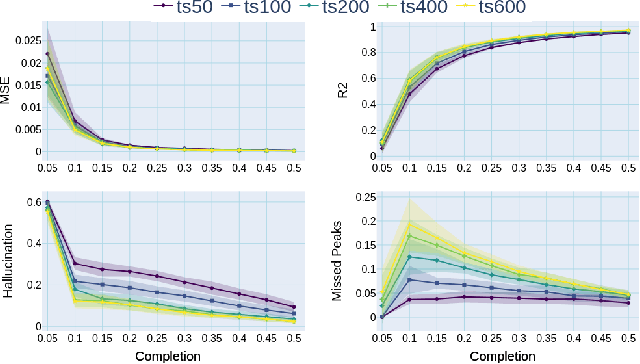
Nuclear Magnetic Resonance (NMR) spectrometry uses electro-frequency pulses to probe the resonance of a compound's nucleus, which is then analyzed to determine its structure. The acquisition time of high-resolution NMR spectra remains a significant bottleneck, especially for complex biological samples such as proteins. In this study, we propose a novel and efficient sub-sampling strategy based on a diffusion model trained on protein NMR data. Our method iteratively reconstructs under-sampled spectra while using model uncertainty to guide subsequent sampling, significantly reducing acquisition time. Compared to state-of-the-art strategies, our approach improves reconstruction accuracy by 52.9\%, reduces hallucinated peaks by 55.6%, and requires 60% less time in complex NMR experiments. This advancement holds promise for many applications, from drug discovery to materials science, where rapid and high-resolution spectral analysis is critical.
Distributed Collapsed Gibbs Sampler for Dirichlet Process Mixture Models in Federated Learning
Dec 18, 2023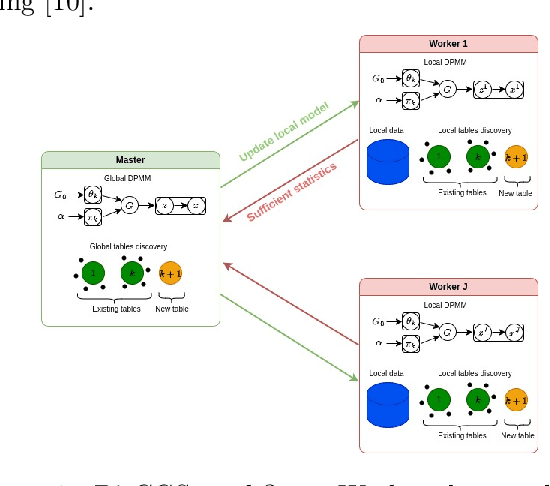

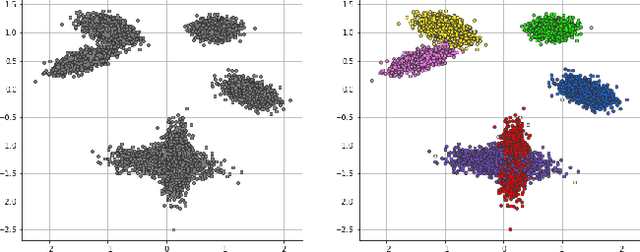
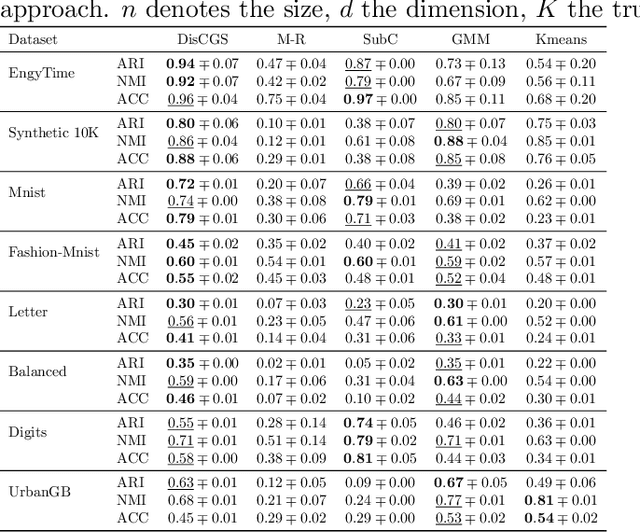
Dirichlet Process Mixture Models (DPMMs) are widely used to address clustering problems. Their main advantage lies in their ability to automatically estimate the number of clusters during the inference process through the Bayesian non-parametric framework. However, the inference becomes considerably slow as the dataset size increases. This paper proposes a new distributed Markov Chain Monte Carlo (MCMC) inference method for DPMMs (DisCGS) using sufficient statistics. Our approach uses the collapsed Gibbs sampler and is specifically designed to work on distributed data across independent and heterogeneous machines, which habilitates its use in horizontal federated learning. Our method achieves highly promising results and notable scalability. For instance, with a dataset of 100K data points, the centralized algorithm requires approximately 12 hours to complete 100 iterations while our approach achieves the same number of iterations in just 3 minutes, reducing the execution time by a factor of 200 without compromising clustering performance. The code source is publicly available at https://github.com/redakhoufache/DisCGS.
Conditional Latent Block Model: a Multivariate Time Series Clustering Approach for Autonomous Driving Validation
Aug 03, 2020

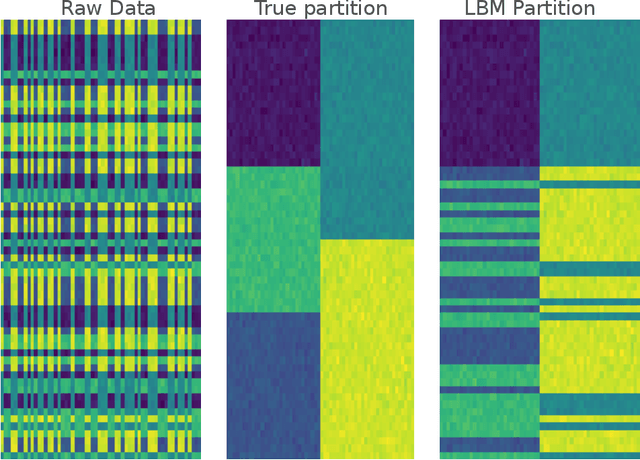
Autonomous driving systems validation remains one of the biggest challenges car manufacturers must tackle in order to provide safe driverless cars. The high complexity stems from several factors: the multiplicity of vehicles, embedded systems, use cases, and the very high required level of reliability for the driving system to be at least as safe as a human driver. In order to circumvent these issues, large scale simulations reproducing this huge variety of physical conditions are intensively used to test driverless cars. Therefore, the validation step produces a massive amount of data, including many time-indexed ones, to be processed. In this context, building a structure in the feature space is mandatory to interpret the various scenarios. In this work, we propose a new co-clustering approach adapted to high-dimensional time series analysis, that extends the standard model-based co-clustering. The FunCLBM model extends the recently proposed Functional Latent Block Model and allows to create a dependency structure between row and column clusters. This structured partition acts as a feature selection method, that provides several clustering views of a dataset, while discriminating irrelevant features. In this workflow, times series are projected onto a common interpolated low-dimensional frequency space, which allows to optimize the projection basis. In addition, FunCLBM refines the definition of each latent block by performing block-wise dimension reduction and feature selection. We propose a SEM-Gibbs algorithm to infer this model, as well as a dedicated criterion to select the optimal nested partition. Experiments on both simulated and real-case Renault datasets shows the effectiveness of the proposed tools and the adequacy to our use case.